 图码
图码1.1 什么是数据结构?
在计算机世界中,数据结构代表了计算机在内存中存储和组织数据的独特方法。通过不同的排列和组合方式,可以使用户高效且适当的方式访问和使用他们所需的数据。
数据结构的存在使用户能够方便地按需访问和操作他们的数据,有助于以高效而紧凑的方式组织和检索各种类型的数据。
对于接触过计算机基础知识的读者而言,对于下面这个公式应该不会陌生:
算法 + 数据结构 = 程序
提出这一公式并以此作为其一本专著书名Algorithms + Data Structures = Programs的瑞士计算机科学家Niklaus Wirth于1984年获得了图灵奖。
程序(Program)是由数据结构(Data Structure)和算法(Algorithm)组成,这意味着的程序的好和快是直接由程序所采用的数据结构和算法决定的。
❗️ 注意
本章节仅作介绍,涉及到的具体数据结构和算法会在后续章节中详细讲解。
数据结构分类
数据也可以被细分为以下两种类型:
线性结构
非线性结构
线性结构
数据元素按顺序或者线性排列
除了第一个元素和最后一个元素之外,剩余每个元素都有前一个和下一个相邻元素。
有两种技术可以在内存中表示这种线性结构。
数组:存储在连续内存位置的相同数据类型的项目的集合。
链表:通过使用指针或链接的概念来表示的所有元素之间的线性关系。
常见的线性结构例子有:
数组:存储在连续内存位置的元素的集合。
链表:节点的集合,每个节点包含一个元素和对下一个节点的引用。
堆栈:具有后进先出 (LIFO)顺序的元素集合。
队列:具有先进先出 (FIFO)顺序的元素集合。
非线性结构
该结构主要用于表示包含各种元素之间的层次关系的数据。
常见的非线性结构例子有:
图:顶点(节点)和表示顶点之间关系的边的集合。图用于建模和分析网络,例如社交网络或交通网络。
树:树的结构呈现出一个类似根和分支的形状,其中有一个根节点,从根节点出发,分成多个子节点,每个子节点可以又分为更多的子节点,依此类推
各种数据结构的简单介绍
数组(Arrays)
数组是相似数据元素的集合。这些数据元素具有相同的数据类型。
数组的元素存储在连续的内存位置中,并由索引(也称为下标)来指向数据。
在C语言中,数组声明使用以下格式:
- 1
- 2
- 3
ElemType name[size];
//例如
char array[10] = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'
// 完整代码:https://totuma.cn上面的语句声明了一个包含10个元素的数组标记。 在C中,数组索引从零开始。这意味着数组标记将总共包含10个元素。
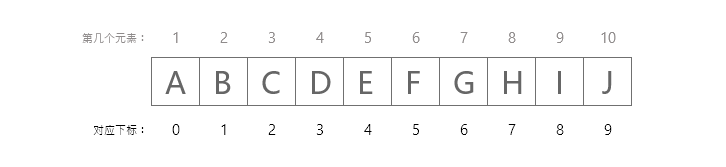
数组下标对应位序
第一个元素将存储在array[0]中,第二个元素将存储在array[1]中,等等。因此,最后一个元素,即第10个元素,将被存储在array[9]中。 在计算机中存储如下图所示。
当我们想要存储大量相同类型的数据时,通常会使用数组。当然,数组也有一些限制,比如:
数组的大小是固定的。
数据元素存储在连续的内存位置中,但是内存中剩余的大小可能不足以容纳当前数组。
元素的插入和删除会很麻烦。
链表(Linked Lists)
链表是一种非常灵活的动态数据结构,其中元素(称为节点)形成一个顺序列表。 与静态数组相比,我们不需要担心链表中将存储多少个元素。这个特性使我们能够编写需要较少维护的健壮程序。在链表中,每个节点都有data域和next指针域:
data域:存放该节点或与该节点对应的任何其他数据的值。
next指针域:指向列表中的下一个节点的指针或链接。
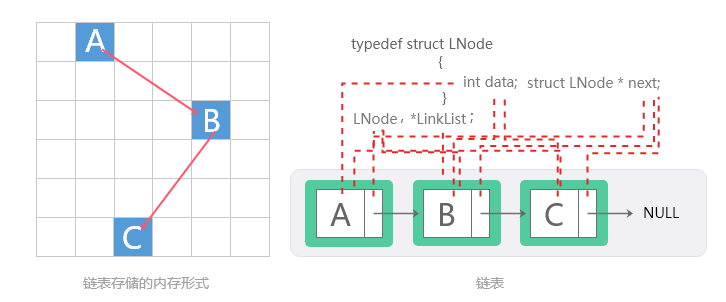
链表结构
列表中的最后一个节点包含一个NULL指针,表明它是当前列表的尾。由于节点的内存是在添加到列表中时动态分配的,因此可以添加到列表中的节点总数仅受可用内存量的限制。具体结构可见下图:
栈(Stacks)
栈是一种线性数据结构, 其中元素的插入和删除只在一端完成,这被称为栈顶。 栈被称为先入后出(LIFO)结构,因为添加到堆栈中的最后一个元素是从堆栈中删除的第一个元素。在计算机的内存中,堆栈可以使用数组或链表来实现。
下面可视化操作显示了一个栈的数组实现。每个栈都有一个与其关联的变量top,用于指向最上面的元素。这是将从中添加或删除元素的位置。
栈支持push 入栈和pop 出栈 操作,push 就是在从栈顶中压入一个元素,pop 就是在栈顶中弹出一个元素,即增和删。
💡 提示
点击下方的入栈、出栈按钮。可以明了的理解到什么是先入后出。
栈 | 可视化完整可视化
1.1 Was ist eine Datenstruktur? - Tutorial zur Datenstruktur Visualisiere deinen Code mit Animationen

Lineare Datenstrukturen verstehen: Liste, Stapel und sequenzielle Liste
Dieser Artikel erklärt die grundlegenden Konzepte von linearen Datenstrukturen, insbesondere die lineare Liste, den Stapel (Stack) und die sequenzielle Liste (Sequenzielle Liste). Er richtet sich an Lernende der Datenstrukturen und Algorithmen, die diese Konzepte mit Hilfe einer visuellen Lernplattform besser verstehen möchten.
Was sind lineare Datenstrukturen?
Lineare Datenstrukturen sind eine Gruppe von Datenstrukturen, bei denen die Elemente in einer linearen Reihenfolge angeordnet sind. Das bedeutet, dass jedes Element einen Vorgänger (außer das erste) und einen Nachfolger (außer das letzte) hat. Die drei wichtigsten Vertreter sind die lineare Liste, der Stapel und die sequenzielle Liste. Sie sind die Grundlage für viele komplexe Algorithmen und werden in der Softwareentwicklung häufig eingesetzt.
Die lineare Liste (Liste)
Eine lineare Liste ist eine geordnete Sammlung von Elementen. Die Reihenfolge der Elemente ist durch die Position in der Liste definiert. Man kann Elemente am Anfang, am Ende oder an einer beliebigen Position einfügen oder entfernen. Es gibt zwei Hauptimplementierungen: die sequenzielle Liste (mit einem Array) und die verkettete Liste (mit Knoten).
Prinzip: Die Elemente werden nacheinander gespeichert. Bei einer sequenziellen Liste sind sie im Speicher hintereinander angeordnet, bei einer verketteten Liste sind sie über Zeiger verbunden.
Eigenschaften: Dynamische Größe (bei verketteten Listen), wahlfreier Zugriff (bei sequenziellen Listen), Einfügen und Löschen an beliebigen Positionen (bei verketteten Listen effizienter).
Anwendungsbereiche: Lineare Listen werden für Aufgaben verwendet, bei denen eine geordnete Sammlung von Elementen benötigt wird, z. B. für Aufgabenlisten, Warteschlangen oder als Grundlage für andere Datenstrukturen wie Stapel und Warteschlangen.
Der Stapel (Stack)
Ein Stapel ist eine spezielle lineare Datenstruktur, die nach dem LIFO-Prinzip (Last In, First Out) funktioniert. Das bedeutet, dass das zuletzt hinzugefügte Element als erstes wieder entfernt wird. Man kann sich einen Stapel wie einen Stapel Bücher vorstellen: Man legt ein Buch oben auf und nimmt auch das oberste Buch als erstes wieder herunter.
Prinzip: Die Operationen sind auf das oberste Element beschränkt. Es gibt zwei Hauptoperationen: push (Element hinzufügen) und pop (Element entfernen). Eine weitere wichtige Operation ist peek (das oberste Element ansehen, ohne es zu entfernen).
Eigenschaften: Einfach und effizient. Die Größe kann dynamisch oder fest sein. Der Zugriff ist nur auf das oberste Element möglich.
Anwendungsbereiche: Stapel werden in vielen Bereichen eingesetzt, z. B. für die Auswertung von Ausdrücken (z. B. Klammerpaare), für das Rückgängigmachen von Aktionen (Undo-Funktion), für die Tiefensuche (DFS) in Graphen und für die Verwaltung von Funktionsaufrufen (Call-Stack).
Die sequenzielle Liste (Sequenzielle Liste)
Die sequenzielle Liste ist eine Implementierung einer linearen Liste, bei der die Elemente in einem zusammenhängenden Speicherbereich (einem Array) gespeichert werden. Die Position eines Elements wird durch einen Index bestimmt. Man spricht auch von einer array-basierten Liste.
Prinzip: Die Elemente werden nacheinander im Speicher abgelegt. Der Zugriff auf ein Element über seinen Index ist sehr schnell (O(1)). Das Einfügen oder Löschen von Elementen in der Mitte erfordert jedoch das Verschieben vieler Elemente (O(n)).
Eigenschaften: Feste oder dynamische Größe (bei dynamischen Arrays wie in C++ oder Python). Wahlfreier Zugriff ist sehr effizient. Das Einfügen und Löschen am Ende ist ebenfalls effizient (O(1)).
Anwendungsbereiche: Sequenzielle Listen werden verwendet, wenn ein schneller Zugriff auf Elemente über den Index benötigt wird, z. B. für Tabellen, Matrizen oder als Grundlage für andere Datenstrukturen wie Heaps. Sie sind ideal für Situationen, in denen die Größe der Liste bekannt ist oder sich nur selten ändert.
Vergleich der drei Datenstrukturen
Alle drei Datenstrukturen sind linear, unterscheiden sich aber in ihren Eigenschaften. Die lineare Liste ist der Oberbegriff. Der Stapel ist eine spezielle Form mit eingeschränktem Zugriff (nur oben). Die sequenzielle Liste ist eine spezielle Implementierung der linearen Liste. Die Wahl hängt von der Anwendung ab: Braucht man schnellen Zugriff auf beliebige Elemente? Dann ist die sequenzielle Liste gut. Braucht man eine strikte LIFO-Ordnung? Dann ist der Stapel die richtige Wahl. Braucht man dynamisches Einfügen und Löschen an beliebigen Positionen? Dann ist eine verkettete Liste (eine andere Form der linearen Liste) besser geeignet.
Warum eine visuelle Lernplattform nutzen?
Das Verständnis von Datenstrukturen und Algorithmen kann abstrakt sein. Eine Datenstruktur-Visualisierungsplattform hilft Ihnen, diese Konzepte Schritt für Schritt zu sehen. Sie können sehen, wie Elemente in einer Liste eingefügt werden, wie ein Stapel wächst und schrumpft oder wie eine sequenzielle Liste bei Einfügeoperationen Elemente verschiebt. Dies macht das Lernen interaktiv und intuitiv.
Funktionen und Vorteile der Plattform
Unsere Plattform bietet eine Reihe von Funktionen, die speziell für Lernende entwickelt wurden:
- Interaktive Visualisierung: Sie können die Datenstrukturen in Echtzeit sehen. Jede Operation wird animiert dargestellt.
- Schritt-für-Schritt-Ausführung: Sie können Algorithmen in Ihrem eigenen Tempo durchgehen. Jeder Schritt wird erklärt.
- Code-Beispiele: Zu jeder Datenstruktur gibt es Code-Beispiele in verschiedenen Programmiersprachen (z. B. Python, Java, C++).
- Übungen und Quizze: Testen Sie Ihr Wissen mit interaktiven Aufgaben.
- Anpassbare Geschwindigkeit: Passen Sie die Animationsgeschwindigkeit an Ihr Lerntempo an.
- Keine Installation nötig: Die Plattform läuft direkt im Browser.
Wie Sie die Plattform nutzen können
Die Nutzung ist einfach. Besuchen Sie die Website und wählen Sie die gewünschte Datenstruktur aus, z. B. "Stapel". Sie sehen dann eine grafische Darstellung des Stapels. Sie können die Operationen "push" und "pop" ausführen, indem Sie auf die entsprechenden Schaltflächen klicken. Die Plattform zeigt Ihnen sofort, wie sich der Stapel verändert. Sie können auch eigene Sequenzen von Operationen eingeben, um komplexe Abläufe zu simulieren.
Für die sequenzielle Liste können Sie Elemente an bestimmten Indizes einfügen oder löschen und beobachten, wie die Elemente im Array verschoben werden. Für die lineare Liste können Sie zwischen der sequenziellen und der verketteten Implementierung wechseln und die Unterschiede direkt sehen.
Praktische Beispiele für den Einsatz
Um die Konzepte zu festigen, hier einige praktische Beispiele:
Beispiel 1: Klammerpaare prüfen mit einem Stapel. Sie haben einen Ausdruck wie "({[]})". Mit einem Stapel können Sie überprüfen, ob die Klammern korrekt geschachtelt sind. Die Visualisierung zeigt Ihnen, wie jede öffnende Klammer auf den Stapel gelegt und jede schließende Klammer mit dem obersten Element verglichen wird.
Beispiel 2: Warteschlange mit einer sequenziellen Liste. Eine Warteschlange (FIFO) kann mit einer sequenziellen Liste implementiert werden. Die Visualisierung zeigt, wie Elemente am Ende hinzugefügt und am Anfang entfernt werden. Sie sehen, wie sich die Indizes verschieben.
Beispiel 3: Rückgängig-Funktion mit einem Stapel. Jede Aktion wird auf einen Stapel gelegt. Wenn Sie "Rückgängig" drücken, wird die letzte Aktion vom Stapel genommen. Die Visualisierung macht diesen Prozess greifbar.
Vertiefung der Konzepte
Die Plattform bietet auch erweiterte Themen. Sie können lernen, wie man einen Stapel mit einer sequenziellen Liste oder einer verketteten Liste implementiert. Sie können die Vor- und Nachteile der verschiedenen Implementierungen vergleichen. Für die sequenzielle Liste können Sie das Konzept des dynamischen Arrays erkunden, bei dem die Größe bei Bedarf verdoppelt wird. Die Visualisierung zeigt Ihnen, wie ein neues Array erstellt und die Elemente kopiert werden.
Häufige Fragen (FAQ)
Frage: Was ist der Unterschied zwischen einer sequenziellen Liste und einem Array?
Antwort: Ein Array ist ein grundlegender Speicherbereich. Eine sequenzielle Liste ist eine Datenstruktur, die ein Array verwendet, aber auch Methoden zum Einfügen, Löschen und Suchen bereitstellt. Die sequenzielle Liste ist also eine Abstraktion eines Arrays.
Frage: Kann ein Stapel auch mit einer sequenziellen Liste implementiert werden?
Antwort: Ja, das ist üblich. Man verwendet die sequenzielle Liste und beschränkt die Operationen auf das Ende (push und pop). Die Visualisierung zeigt dies deutlich.
Frage: Ist die lineare Liste dasselbe wie die sequenzielle Liste?
Antwort: Nein. Die lineare Liste ist der Oberbegriff. Die sequenzielle Liste ist eine spezielle Implementierung. Eine andere Implementierung ist die verkettete Liste.
Fazit
Lineare Datenstrukturen wie die lineare Liste, der Stapel und die sequenzielle Liste sind fundamentale Bausteine der Informatik. Ein tiefes Verständnis dieser Konzepte ist entscheidend für jeden, der Algorithmen und Programmierung lernt. Eine visuelle Lernplattform kann diesen Lernprozess erheblich beschleunigen, indem sie abstrakte Konzepte greifbar macht. Nutzen Sie die interaktiven Visualisierungen, um die Dynamik dieser Datenstrukturen zu erleben und Ihr Wissen zu festigen. Beginnen Sie noch heute mit der Erkundung und verbessern Sie Ihre Fähigkeiten in der Datenstrukturanalyse und Algorithmenentwicklung.
Hinweis: Dieser Artikel ist für Suchmaschinen optimiert, um Lernenden zu helfen, die nach Informationen über lineare Datenstrukturen, Stapel, sequenzielle Listen und visuelle Lernplattformen suchen.
队列(Queues)
队列是一种先进先出(FIFO)的数据结构,其中首先插入的元素是第一个要取出的元素。 队列中的元素在队尾添加,然后在队头删除。 与栈一样,队列也可以通过使用数组或链表来实现。 每个队列都有队头和队尾,分别指向可以进行删除和插入的位置。
队列 | 可视化完整可视化
1.1 Was ist eine Datenstruktur? - Tutorial zur Datenstruktur Visualisiere deinen Code mit Animationen
队列 (Queue) 与顺序表 (Sequential List) 在数据结构可视化学习中的完整指南
在数据结构与算法的学习过程中,队列(Queue)和顺序表(Sequential List)是两个最基础且最重要的概念。对于使用德语学习数据结构的初学者来说,理解这两种数据结构的原理、特点以及它们在实际编程中的应用场景,是构建扎实计算机科学知识体系的关键一步。本文将详细解释队列和顺序表的核心概念,并介绍如何通过数据结构可视化学习平台更高效地掌握这些知识。
什么是队列 (Queue)?—— 先进先出 (FIFO) 的基本原则
队列是一种特殊的线性数据结构,它遵循先进先出(First In, First Out,简称FIFO)的原则。这意味着最早进入队列的元素将最先被移除。你可以将队列想象成一个现实生活中的排队场景:在超市收银台前排队结账的顾客,第一个到达的人会第一个被服务并离开队伍,而最后到达的人则必须等待所有前面的人完成服务后才能轮到。
在计算机科学中,队列被广泛应用于需要按顺序处理任务的场景。例如,操作系统的任务调度、打印任务的排队处理、网络数据包的传输顺序控制等,都离不开队列这种数据结构。队列的基本操作包括入队(enqueue,将元素添加到队列尾部)和出队(dequeue,从队列头部移除元素)。此外,常见的操作还包括查看队首元素(peek或front)以及检查队列是否为空(isEmpty)。
什么是顺序表 (Sequential List)?—— 连续内存存储的线性结构
顺序表是一种基于连续内存空间存储数据的线性表。在顺序表中,所有元素按照逻辑顺序依次存放在一段连续的存储单元中。这意味着每个元素在内存中的物理地址是相邻的,因此可以通过下标直接访问任意位置的元素,时间复杂度为O(1)。这正是顺序表最显著的优势之一:随机访问速度极快。
顺序表通常使用数组来实现。在编程语言中,例如C语言的数组、Java的ArrayList、Python的list,都是顺序表的典型实现。顺序表的常见操作包括插入、删除、查找和修改元素。需要注意的是,在顺序表中间插入或删除元素时,需要移动大量后续元素以保持连续存储,因此这些操作的时间复杂度为O(n)。
队列与顺序表的关系:如何用顺序表实现队列
在实际编程中,队列可以通过多种方实现,其中最常见的方式之一就是使用顺序表(数组)来实现。这种实现方式通常称为顺序队列。在顺序队列中,我们使用一个数组来存储队列中的元素,并维护两个指针:一个指向队首(front),另一个指向队尾(rear)。入队操作将元素添加到rear指向的位置,然后rear指针后移;出队操作则从front指向的位置取出元素,然后front指针后移。
然而,简单的顺序队列存在一个严重的问题:假溢出(false overflow)。当rear指针到达数组末尾时,即使数组前部还有空闲空间,也无法再添加新元素。为了解决这个问题,计算机科学家引入了循环队列(Circular Queue)的概念。循环队列通过将数组视为一个环状结构,使得rear指针在到达数组末尾时可以循环回到数组开头,从而充分利用所有存储空间。这种设计在操作系统和网络通信等领域有着广泛的应用。
队列的核心特点与应用场景详解
队列作为一种基础数据结构,具有以下核心特点:首先,它严格遵循FIFO原则,保证了数据处理的公平性;其次,队列的操作仅限于两端,只能在队尾添加元素,在队首移除元素,这种限制简化了数据管理;最后,队列可以动态增长或缩小,适应不同规模的数据处理需求。
队列在实际应用中的场景非常丰富。在计算机系统中,CPU的任务调度队列确保所有进程都能获得执行机会;在打印机管理中,打印任务队列保证文档按提交顺序被打印;在网络通信中,数据包队列用于缓冲和排序传输中的数据;在广度优先搜索(BFS)算法中,队列是遍历图或树的必备工具;在消息队列系统中,队列实现了不同组件之间的异步通信和解耦。
顺序表的核心特点与典型应用场景
顺序表的主要特点包括:首先,随机访问效率极高,通过下标可以在常数时间内访问任意元素;其次,内存利用率高,因为元素连续存储,没有额外的指针开销;第三,缓存友好性良好,由于数据在内存中连续分布,CPU缓存命中率高;第四,插入和删除操作效率较低,特别是在表中间位置进行操作时。
顺序表的典型应用场景包括:当需要频繁访问元素而很少进行插入和删除操作时,顺序表是最佳选择。例如,存储静态数据集合、实现查找表、作为哈希表的底层存储结构、在科学计算中存储矩阵数据等。此外,顺序表也是实现栈、队列等其他数据结构的基础组件。
队列与顺序表的性能对比分析
对于学习者来说,理解队列和顺序表的性能差异至关重要。在时间复杂度方面,顺序表的随机访问为O(1),而队列的随机访问通常不被支持,因为队列的设计初衷就是限制访问方式。在插入和删除操作方面,顺序表在末尾插入和删除为O(1),但在中间位置为O(n);队列的入队和出队操作均为O(1),这是队列的一大优势。
在空间复杂度方面,顺序表需要预先分配固定大小的内存空间,可能造成浪费或需要动态扩容;队列(特别是链式队列)可以动态分配内存,更加灵活。在内存布局方面,顺序表数据连续存储,缓存友好;而队列的链式实现则数据分散存储,缓存性能较差。
数据结构可视化学习平台的优势与功能
对于许多学习者来说,仅通过文字和静态图片来理解数据结构的动态行为是困难的。这正是数据结构可视化学习平台的价值所在。一个优秀的数据结构可视化平台能够将抽象的概念转化为直观的动画和交互式演示,极大地降低学习门槛。
我们的数据结构可视化学习平台专门为德语用户设计,提供了以下核心功能:
第一,交式动画演示。用户可以通过点击按钮,一步一步地观察队列的入队和出队过程,或者观察顺序表的插入和删除操作如何影响内存布局。每一步操作都配有详细的德语文字说明,帮助用户理解正在发生的变化。
第二,代码与可视化同步。平台不仅展示数据结构的动态变化,还同步显示对应的代码执行过程。用户可以看到每一行代码如何影响数据结构的状态,这种代码与可视化的对应关系是理解算法实现的关键。
第三,自定义操作与测试。用户可以根据自己的学习进度,自定义输入数据,并观察不同操作对数据结构的影响。例如,用户可以创建一个队列,然后执行一系列入队和出队操作,观察队列状态的变化。
第四,性能分析工具。平台内置了性能分析模块,可以展示不同操作的时间复杂度和空间复杂度,帮助用户从理论层面理解数据结构的效率特性。
第五,错误模拟与调试。平台允许用户模拟常见的编程错误,例如队列溢出或顺序表越界访问,并通过可视化方式展示错误发生的原因和后果,从而加对确使用方法的理解。
如何使用可视化平台学习队列与顺序表
为了充分利用可视化学习平台,我们建议学习者按照以下步骤进行:
第一步,从基础概念开始。首先使用平台的演示模式,观察队列和顺序表的基本操作过程。注意观察队列的FIFO特性如何体现在动画中,以及顺序表的随机访问如何通过下标实现。
第二步,动手实践。切换到交互模式,自己执行一系列操作。例如,先创建一个空队列,然后依次入队5个元素,再出队3个元素,观察队首和队尾指针的变化。对于顺序表,尝试在表头、表尾和中间位置插入元素,观察内存中元素的移动过程。
第三步,对比学习。使用平台同时展示队列和顺序表的操作过程,对比它们的异同。特别注意对比队列的入队/出队与顺序表的插入/删除在时间开销上的差异。
第四步,挑战进阶内容。在掌握基础操作后,尝试学习循环队列、双端队列(Deque)等进阶内容。平台提供了这些高级数据结构的可视化演示,帮助用户理解它们如何解决基本队列的局限性。
第五步,结合编程练习。平台提供了与可视化对应的代码模板,用户可以在平台上直接编写和测试代码,实现自己的列或顺序表程序。代码运行结果会立即在可视化界面中反映出来,形成即时反馈的学习循环。
常见问题与学习建议(FAQ)
在学习队列和顺序表的过程中,许多德语学习者会遇到一些常见问题。以下是我们整理的典型问题及解答:
问题一:为什么队列的入队和出队操作都是O(1)时间复杂度?答案:因为队列只允许在两端进行操作,不需要移动其他元素。入队时直接在队尾添加,出队时直接从队首移除,这两个操作都不涉及元素移动。
问题二:顺序表为什么在中间插入元素很慢?答案:因为顺序表要求元素连续存储,在中间插入元素时,需要将插入位置之后的所有元素向后移动一个位置,这涉及到大量的内存复制操作,因此时间复杂度为O(n)。
问题三:循环队列如何解决假溢出问题?答案:循环队列将数组视为环状,当rear指针到达数组末尾时,如果数组开头还有空闲空间,rear指针会循环回到数组开头继续存储。通过取模运算可以实现这种循环效果。
问题四:什么情况下应该使用队列而不是顺序表?答案:当需要严格按照FIFO顺序处理数据时,应该使用队列。例如任务调度、消息传递、广度优先搜索等场景。如果主要操作是随机访问元素,则应该选择顺序表。
学习建议:我们建议学习者每天花15-20分钟在可视化平台上操作一种数据结构,坚持一周即可牢固掌握。不要急于求成,先理解基本操作,再逐步学习复杂应用。利用平台的记录功能,回顾自己的操作历史,分析错误操作的原因。
总结:掌握队列与顺序表是数据结构学习的关键一步
队列和顺序表作为数据结构与算法的基础组成部分,是每个计算机科学学习者必须掌握的核心概念。队列以其FIFO特性在任务调度、网络通信等领域发挥着重要作用,而顺序表则以其高效的随机访问能力成为许多高级数据结构的构建基础。理解这两种数据结构的原理、特点和应用场景,对于后续学习更复杂的数据结构(如树、图、哈希表等)至关重要。
通过使用数据结构可视化学习平台,德语学习者可以克服语言障碍,以直观、互动的方式深入理解这些抽象概念。平台提供的动画演示、代码同步、自定义操作和性能分析等功能,能够帮助学习者从多个维度掌握知识,将理论学习与实操作紧密结合。
我们鼓励所有数据结构学习者充分利用可视化工具的优势,将抽象的概念转化为可视化的认知。记住,数据结构不仅仅是理论知识,更是解决实际问题的强大工具。通过可视化平台的辅助,您将能够更快、更深入地掌握队列和顺序表的精髓,为未来的编程和算法学习打下坚实的基础。
立即开始您的数据结构可视化学习之旅,探索队列与顺序表的奥秘,开启计算机科学学习的全新体验!
树(Tree)
树是一种非线性的数据结构,它由一组按 分层顺序排列的节点组成。 其中一个节点被指定为根节点,其余的节点可以被划分为不相交的集合,这样每个集合都是根的一个子树。
树的最简单的形式是二叉树。 二叉树由一个根节点和左右子树组成,其中两个子树也是二叉树。每个节点都包含一个数据元素、一个指向左子树的左指针和一个指向右子树的右指针。根元素是由一个“根”指针指向的最顶部的节点。
二叉树 | 可视化完整可视化
1.1 Was ist eine Datenstruktur? - Tutorial zur Datenstruktur Visualisiere deinen Code mit Animationen
Einführung in Bäume, binäre Suche und verkettete Listen für die Datenstruktur-Visualisierung
Willkommen zu diesem umfassenden Leitfaden über drei fundamentale Konzepte der Informatik: Bäume, binäre Suche und verkettete Listen. Dieser Artikel richtet sich an alle, die Datenstrukturen und Algorithmen lernen und verstehen möchten. Wir erklären die Prinzipien, Eigenschaften und Anwendungsszenarien dieser Strukturen auf eine leicht verständliche Weise. Besonders hilfreich ist der Einsatz eines Datenstruktur-Visualisierungsplattform, die abstrakte Konzepte in greifbare, interaktive Darstellungen verwandelt. Lassen Sie uns gemeinsam in die Welt der Bäume, der binären Suche und der verketteten Listen eintauchen.
Was sind Datenstrukturen und warum sind sie wichtig?
Datenstrukturen sind spezielle Methoden, um Daten auf einem Computer zu organisieren und zu speichern. Sie ermöglichen es uns, Daten effizient zu verwalten, abzurufen und zu modifizieren. Ohne geeignete Datenstrukturen wären selbst einfache Programme langsam und ineffizient. Für jeden Lernenden der Informatik ist das Verständnis von Datenstrukturen wie Bäumen, verketteten Listen und Suchalgorithmen wie der binären Suche unerlässlich. Eine gute Visualisierungsplattform kann den Lernprozess erheblich beschleunigen, indem sie zeigt, wie diese Strukturen in Echtzeit arbeiten.
Bäume (Trees) – Eine hierarchische Datenstruktur
Ein Baum ist eine nicht-lineare Datenstruktur, die aus Knoten (Nodes) besteht, die durch Kanten (Edges) verbunden sind. Er modelliert hierarchische Beziehungen, ähnlich wie ein Stammbaum oder eine Ordnerstruktur auf Ihrem Computer. Der oberste Knoten wird als Wurzel (Root) bezeichnet. Jeder Knoten kann null oder mehr Kindknoten haben. Knoten ohne Kinder heißen Blätter (Leaves).
Prinzip und Eigenschaften von Bäumen
Das grundlegende Prinzip eines Baums ist die rekursive Struktur: Jeder Teilbaum ist selbst wieder ein Baum. Bäume haben keine Zyklen, was bedeutet, dass es genau einen Pfad zwischen zwei beliebigen Knoten gibt. Wichtige Eigenschaften sind die Tiefe (Tiefe eines Knotens) und die Höhe (Höhe des Baums). Bäume können in verschiedenen Formen auftreten, wie binäre Bäume, AVL-Bäume oder Rot-Schwarz-Bäume. Ein binärer Baum ist ein spezieller Baum, bei dem jeder Knoten maximal zwei Kinder hat, die als linkes und rechtes Kind bezeichnet werden.
Anwendungsszenarien von Bäumen
Bäume werden in vielen Bereichen der Informatik eingesetzt. Sie sind die Grundlage für Dateisysteme, Datenbankindizes, Compiler (Syntaxbäume), Netzwerkprotokolle und künstliche Intelligenz (Entscheidungsbäume). Im Web werden Bäume für das Document Object Model (DOM) verwendet. Wenn Sie eine Webseite besuchen, wird der HTML-Code als Baumstruktur dargestellt. Auch in Algorithmen wie der Tiefensuche (DFS) und Breitensuche (BFS) spielen Bäume eine zentrale Rolle.
Binäre Suche (Binary Search) – Ein effizienter Suchalgorithmus
Die binäre Suche ist ein Algorithmus, der in einer sortierten Liste oder einem sortierten Array nach einem bestimmten Element sucht. Im Gegensatz zur linearen Suche, die jedes Element einzeln überprüft, teilt die binäre Suche den Suchraum bei jedem Schritt in zwei Hälften. Dies macht sie extrem effizient, besonders bei großen Datenmengen.
Wie funktioniert die binäre Suche?
Der Algorithmus beginnt mit der Mitte der sortierten Liste. Wenn der gesuchte Wert kleiner ist als der Wert in der Mitte, wird die Suche in der linken Hälfte fortgesetzt. Ist er größer, wird in der rechten Hälfte weitergesucht. Dieser Vorgang wiederholt sich, bis der Wert gefunden wurde oder der Suchraum leer ist. Die binäre Suche hat eine Zeitkomplexität von O(log n), was bedeutet, dass die Anzahl der benötigten Schritte logarithmisch mit der Größe der Daten wächst. Bei einer Liste mit 1.000 Elementen benötigt die binäre Suche im schlimmsten Fall nur 10 Schritte, während die lineare Suche 1.000 Schritte benötigen würde.
Anwendungsszenarien der binären Suche
Die binäre Suche wird überall dort eingesetzt, wo Daten sortiert vorliegen. Sie ist die Grundlage für viele Datenbankabfragen, Suchmaschinen, Wörterbücher und Algorithmen in der Computergrafik. In der Praxis wird sie oft in Kombination mit Bäumen verwendet, wie zum Beispiel bei binären Suchbäumen (Binary Search Trees, BST). Ein binärer Suchbaum ist ein binärer Baum, bei dem für jeden Knoten gilt: Alle Werte im linken Teilbaum sind kleiner, und alle Werte im rechten Teilbaum sind größer als der Knotenwert. Dies ermöglicht eine sehr effiziente Suche, Einfügung und Löschung von Daten.
Verkettete Listen (Linked Lists) – Eine dynamische lineare Datenstruktur
Eine verkettete Liste ist eine lineare Datenstruktur, bei der Elemente (Knoten) nicht wie in einem Array an zusammenhängenden Speicherstellen gespeichert werden. Stattdessen enthält jeder Knoten einen Datenwert und einen oder mehrere Zeiger (Pointer), die auf den nächsten (und manchmal vorherigen) Knoten verweisen. Es gibt einfach verkettete Listen (Singly Linked List), doppelt verkettete Listen (Doubly Linked List) und zirkuläre verkettete Listen (Circular Linked List).
Prinzip und Eigenschaften von verketteten Listen
Das Hauptmerkmal einer verketteten Liste ist ihre Dynamik. Sie kann während der Laufzeit wachsen und schrumpfen, ohne dass eine Neuzuweisung des Speichers erforderlich ist, wie es bei Arrays der Fall ist. Das Einfügen und Löschen von Elementen am Anfang oder in der Mitte der Liste ist sehr effizient, da nur die Zeiger aktualisiert werden müssen. Der Nachteil ist, dass der Zugriff auf ein bestimmtes Element (z. B. das dritte Element) linear erfolgt, da man die Liste von Anfang an durchlaufen muss. Im Gegensatz dazu erlaubt ein Array einen direkten Zugriff über den Index.
Anwendungsszenarien von verketteten Listen
Verkettete Listen werden häufig in Szenarien eingesetzt, in denen die Größe der Daten unbekannt ist oder sich häufig ändert. Sie sind die Grundlage für Stapel (Stacks) und Warteschlangen (Queues). Auch in der Speicherverwaltung von Betriebssystemen, in Musikplayern (für Playlists) und in der Implementierung von Graphen (Adjazenzlisten) kommen verkettete Listen zum Einsatz. In vielen Programmiersprachen werden sie intern für die Implementierung von Datenstrukturen wie Listen oder Maps verwendet.
Die Verbindung zwischen Bäumen, binärer Suche und verketteten Listen
Diese drei Konzepte sind eng miteinander verbunden. Ein binärer Suchbaum (BST) kombiniert die hierarchische Struktur eines Baums mit der Effizienz der binären Suche. Verkettete Listen werden oft verwendet, um die Kinder eines Knotens in einem Baum zu speichern, insbesondere wenn die Anzahl der Kinder variabel ist. In der Praxis werden Bäume häufig mit Hilfe von verketteten Listen implementiert. Das Verständnis aller drei Konzepte ist entscheidend, um komplexe Algorithmen und Datenstrukturen zu meistern.
Herausforderungen beim Lernen von Datenstrukturen und Algorithmen
Viele Lernende haben Schwierigkeiten, abstrakte Konzepte wie Bäume oder die binäre Suche zu verstehen, wenn sie nur in Textform oder mit statischen Diagrammen präsentiert werden. Die dynamische Natur dieser Strukturen – wie sich ein Baum beim Einfügen eines neuen Knotens verändert oder wie die binäre Suche den Suchraum schrittweise halbiert – ist schwer zu erfassen. Genau hier kommt eine Datenstruktur-Visualisierungsplattform ins Spiel.
Was ist eine Datenstruktur-Visualisierungsplattform?
Eine Datenstruktur-Visualisierungsplattform ist ein interaktives Online-Tool, das es Benutzern ermöglicht, Datenstrukturen und Algorithmen in Echtzeit zu sehen und zu manipulieren. Sie bietet eine grafische Oberfläche, auf der Bäume, Listen, Arrays und andere Strukturen als animierte Diagramme dargestellt werden. Benutzer können Operationen wie Einfügen, Löschen, Suchen und Sortieren ausführen und sofort sehen, wie sich die Struktur verändert. Dies macht abstrakte Konzepte greifbar und verständlich.
Funktionen einer Datenstruktur-Visualisierungsplattform
Eine gute Visualisierungsplattform bietet eine Vielzahl von Funktionen. Dazu gehören Schritt-für-Schritt-Animationen, die zeigen, wie ein Algorithmus arbeitet. Benutzer können die Geschwindigkeit der Animation steuern, Pausen einlegen und einzelne Schritte vor- und zurückgehen. Viele Plattformen erlauben es, eigene Daten einzugeben oder vordefinierte Beispiele zu verwenden. Sie bieten auch Code-Beispiele in verschiedenen Programmiersprachen, die die Visualisierung mit dem tatsächlichen Code verbinden. Einige Plattformen haben sogar integrierte Übungen und Quizfragen, um das Gelernte zu testen.
Vorteile der Verwendung einer Visualisierungsplattform
Der größte Vorteil ist die verbesserte Verständlichkeit. Visuelles Lernen ist oft effektiver als reines Textlernen. Durch die Interaktivität können Lernende selbst experimentieren und ein tieferes Verständnis entwickeln. Die Plattform hilft, häufige Fehler zu vermeiden, indem sie zeigt, warum eine bestimmte Operation fehlschlägt (z. B. das Einfügen eines doppelten Werts in einen binären Suchbaum). Darüber hinaus fördert die Plattform das algorithmische Denken, da Benutzer sehen, wie Algorithmen Probleme Schritt für Schritt lösen. Für die Prüfungsvorbereitung und das Selbststudium ist eine solche Plattform ein unschätzbares Werkzeug.
Wie man eine Visualisierungsplattform für Bäume nutzt
Um Bäume zu lernen, können Sie auf der Plattform einen binären Baum erstellen und Knoten hinzufügen. Sie werden sehen, wie der Baum wächst und wie die Hierarchie entsteht. Sie können dann verschiedene Traversierungsmethoden wie Preorder, Inorder und Postorder ausführen und beobachten, wie der Algorithmus durch den Baum navigiert. Für binäre Suchbäume können Sie Werte einfügen und die binäre Suche visualisieren. Die Plattform zeigt Ihnen genau, wie der Algorithmus den Baum durchläuft, um einen bestimmten Wert zu finden. Sie werden verstehen, warum ein balancierter Baum effizienter ist als ein entarteter Baum.
Wie man eine Visualisierungsplattform für die binäre Suche nutzt
Wählen Sie auf der Plattform die binäre Suche aus. Sie sehen ein sortiertes Array. Starten Sie die Animation und beobachten Sie, wie der Algorithmus die Mitte des Arrays markiert und den Suchraum halbiert. Sie können die Geschwindigkeit verlangsamen, um jeden Schritt genau zu verfolgen. Die Plattform zeigt Ihnen auch die Zeitkomplexität in Echtzeit. Experimentieren Sie mit verschiedenen Arrays und Suchwerten. Sie werden schnell verstehen, warum die binäre Suche so effizient ist und warum die Daten sortiert sein müssen.
Wie man eine Visualisierungsplattform für verkettete Listen nutzt
Erstellen Sie eine einfach oder doppelt verkettete Liste auf der Plattform. Fügen Sie Knoten am Anfang, in der Mitte und am Ende hinzu. Beobachten Sie, wie die Zeiger aktualisiert werden. Löschen Sie Knoten und sehen Sie, wie die Liste wieder zusammengefügt wird. Die Plattform visualisiert die Zeiger als Pfeile, die von einem Knoten zum nächsten zeigen. Sie können auch Operationen wie das Suchen eines Elements oder das Umkehren der Liste durchführen. Dies hilft Ihnen, die dynamische Natur der verketteten Liste zu verstehen und zu sehen, warum das Einfügen in einer Liste effizienter ist als in einem Array.
Praktische Beispiele für die Nutzung der Plattform
Ein typisches Beispiel ist das Einfügen der Werte 5, 3, 7, 2, 4, 6, 8 in einen binären Suchbaum. Auf der Plattform sehen Sie, wie der Baum Schritt für Schritt aufgebaut wird. Sie können dann die binäre Suche nach dem Wert 4 durchführen und beobachten, wie der Algorithmus von der Wurzel (5) nach links zu 3 und dann nach rechts zu 4 geht. Ein weiteres Beispiel ist das Erstellen einer verketteten Liste mit den Werten "A", "B", "C" und das Einfügen von "D" zwischen "B" und "C". Die Plattform zeigt Ihnen, wie der Zeiger von B auf D und von D auf C umgeleitet wird. Diese visuellen Beispiele sind viel einprägsamer als reiner Code.
Integration der Plattform in den Lernprozess
Die Visualisierungsplattform sollte nicht isoliert, sondern als Ergänzung zu Lehrbüchern, Online-Kursen und Programmierübungen verwendet werden. Beginnen Sie mit der Lektüre der theoretischen Konzepte in einem Buch oder Skript. Gehen Sie dann zur Plattform, um die Konzepte visuell zu erleben. Versuchen Sie, die Algorithmen selbst zu implementieren, nachdem Sie sie visualisiert haben. Die Plattform kann Ihnen auch helfen, Fehler in Ihrem eigenen Code zu finden, indem Sie die erwartete Visualisierung mit Ihrer Implementierung vergleichen. Wiederholen Sie die Übungen, bis Sie die Konzepte vollständig verstanden haben.
Die Rolle der Plattform bei der Prüfungsvorbereitung
Für Studierende, die sich auf Prüfungen in Datenstrukturen und Algorithmen vorbereiten, ist die Visualisierungsplattform ein ideales Werkzeug. Sie können alle wichtigen Operationen wiederholen, ohne ein komplettes Programm schreiben zu müssen. Die Plattform bietet eine schnelle und effektive Möglichkeit, Ihr Wissen zu testen. Sie können sich selbst herausfordern, indem Sie versuchen, die nächsten Schritte eines Algorithmus vorherzusagen, bevor die Animation sie zeigt. Dies schärft Ihr Verständnis und bereitet Sie auf typische Prüfungsfragen vor.
Zukünftige Entwicklungen in der Datenstruktur-Visualisierung
Die Technologie der Datenstruktur-Visualisierung entwickelt sich ständig weiter. Moderne Plattformen nutzen künstliche Intelligenz, um personalisierte Lernpfade zu erstellen. Sie können Fehler analysieren und gezielte Übungen vorschlagen. Virtual Reality (VR) und Augmented Reality (AR) könnten in Zukunft verwendet werden, um Datenstrukturen in einem dreidimensionalen Raum darzustellen. Auch die Integration mit integrierten Entwicklungsumgebungen (IDEs) wird verbessert, sodass Entwickler ihre eigenen Algorithmen direkt in der IDE visualisieren können. Die Grundidee bleibt jedoch gleich: Abstrakte Konzepte durch Visualisierung zugänglich zu machen.
Warum Sie jetzt mit der Visualisierung beginnen sollten
Wenn Sie Datenstrukturen und Algorithmen lernen, zögern Sie nicht, eine Visualisierungsplattform zu nutzen. Der Zeitaufwand lohnt sich. Sie werden Konzepte schneller verstehen und besser behalten. Die Plattform macht das Lernen nicht nur effektiver, sondern auch unterhaltsamer. Sie werden sehen, wie Algorithmen "leben" und wie Datenstrukturen sich dynamisch verändern. Dies wird Ihre Begeisterung für die Informatik wecken und vertiefen. Starten Sie noch heute mit der Erkundung von Bäumen, binären Suchalgorithmen und verketteten Listen auf einer Visualisierungsplattform.
Zusammenfassung der wichtigsten Punkte
In diesem Artikel haben wir die drei grundlegenden Konzepte Bäume, binäre Suche und verkettete Listen ausführlich behandelt. Bäume sind hierarchische Strukturen, die für die Organisation von Daten in Ebenen verwendet werden. Die binäre Suche ist ein effizienter Algorithmus zum Finden von Elementen in sortierten Daten. Verkettete Listen sind dynamische lineare Strukturen, die sich durch effizientes Einfügen und Löschen auszeichnen. Alle drei Konzepte sind eng miteinander verbunden und bilden die Grundlage für viele komplexe Algorithmen. Eine Datenstruktur-Visualisierungsplattform ist das ideale Werkzeug, um diese Konzepte zu verstehen, zu üben und zu meistern. Sie bietet interaktive Animationen, Schritt-für-Schritt-Anleitungen und praktische Übungen.
Häufig gestellte Fragen (FAQ)
Frage: Was ist der Unterschied zwischen einem binären Baum und einem binären Suchbaum? Antwort: Ein binärer Baum hat nur die Regel, dass jeder Knoten maximal zwei Kinder hat. Ein binärer Suchbaum hat zusätzlich die Ordnungsregel, dass alle Werte im linken Teilbaum kleiner und alle Werte im rechten Teilbaum größer als der Knotenwert sind. Dies ermöglicht die effiziente binäre Suche.
Frage: Warum ist die binäre Suche so schnell? Antwort: Die binäre Suche halbiert bei jedem Schritt den Suchraum. Dies führt zu einer logarithmischen Zeitkomplexität O(log n). Bei großen Datenmengen ist dies wesentlich schneller als die lineare Suche mit O(n).
Frage: Wann sollte ich eine verkettete Liste anstelle eines Arrays verwenden? Antwort: Verwenden Sie eine verkettete Liste, wenn Sie häufig Elemente einfügen oder löschen müssen, insbesondere am Anfang oder in der Mitte. Verwenden Sie ein Array, wenn Sie häufig auf Elemente über ihren Index zugreifen müssen und die Größe der Daten bekannt und stabil ist.
Frage: Kann ich die Visualisierungsplattform auch ohne Programmierkenntnisse nutzen? Antwort: Ja, die meisten Plattformen sind so gestaltet, dass sie auch ohne tiefgehende Programmierkenntnisse genutzt werden können. Sie bieten vorgefertigte Beispiele und intuitive Bedienelemente. Dennoch ist es hilfreich, grundlegende Programmierkonzepte zu kennen.
Fazit und nächste Schritte
Das Verständnis von Bäumen, binärer Suche und verketteten Listen ist ein entscheidender Schritt auf dem Weg zum Informatiker oder zur Informatikerin. Diese Konzepte sind nicht nur theoretisch wichtig, sondern haben praktische Anwendungen in fast jedem Bereich der Softwareentwicklung. Nutzen Sie die verfügbaren Ressourcen, insbesondere Datenstruktur-Visualisierungsplattformen, um Ihr Wissen zu vertiefen. Experimentieren Sie, machen Sie Fehler und lernen Sie daraus. Die Plattform wird Ihnen dabei helfen, abstrakte Ideen in greifbare Realität zu verwandeln. Beginnen Sie noch heute mit Ihrer Lernreise und entdecken Sie die faszinierende Welt der Algorithmen und Datenstrukturen. Viel Erfolg!
Weiterführende Ressourcen und Links
Um Ihr Wissen weiter zu vertiefen, empfehlen wir Ihnen, zusätzliche Tutorials, Online-Kurse und Fachbücher zu konsultieren. Viele Universitäten bieten kostenlose Vorlesungsmaterialien an. Auch auf Plattformen wie YouTube finden Sie hervorragende Erklärvideos. Die Kombination aus theoretischem Studium und praktischer Visualisierung ist der Schlüssel zum Erfolg. Vergessen Sie nicht, regelmäßig zu üben und Ihr Wissen in kleinen Projekten anzuwenden. Die Datenstruktur-Visualisierungsplattform wird Sie dabei unterstützen, ein solides Fundament in der Informatik aufzubauen.
图(Graphs)
图是一种非线性的数据结构,它是连接这些顶点的顶点(也称为节点)和边的集合。图通常被视为树结构的泛化,其中树节点之间不是纯粹的父子关系,节点之间的任何复杂关系。在树状结构中,节点可以有任意数量的子节点,但只有一个父节点,但是在图中却没有这些限制。
图的数据结构 | 可视化完整可视化
1.1 Was ist eine Datenstruktur? - Tutorial zur Datenstruktur Visualisiere deinen Code mit Animationen
Graph-Datenstruktur: Speicherstrukturen für die algorithmische Visualisierung
Die Graph-Datenstruktur ist eine der fundamentalen und zugleich vielseitigsten Datenstrukturen in der Informatik. Für Lernende der Datenstrukturen und Algorithmen ist das Verständnis der Speicherstrukturen von Graphen essenziell, da sie die Grundlage für zahlreiche komplexe Algorithmen wie Dijkstra, Kruskal oder Tiefensuche bilden. In diesem Artikel werden wir die Prinzipien, Eigenschaften und Anwendungsszenarien von Graph-Speicherstrukturen detailliert erläutern und zeigen, wie eine Datenstruktur-Visualisierungsplattform den Lernprozess revolutionieren kann.
Was ist eine Graph-Datenstruktur?
Ein Graph ist eine abstrakte mathematische Struktur, die aus einer Menge von Knoten (Vertices) und einer Menge von Kanten (Edges) besteht, die diese Knoten verbinden. Formal wird ein Graph als G = (V, E) dargestellt, wobei V die Knotenmenge und E die Kantenmenge ist. Graphen können gerichtet (Digraph) oder ungerichtet sein, gewichtet oder ungewichtet. Diese Flexibilität macht sie zur idealen Wahl für die Modellierung komplexer Beziehungen in Netzwerken, sozialen Medien, Transportwegen und vielen anderen Bereichen.
Für Algorithmen-Lernende ist es wichtig zu verstehen, dass die Wahl der Speicherstruktur eines Graphen direkten Einfluss auf die Effizienz der darauf operierenden Algorithmen hat. Die beiden häufigsten Speicherstrukturen sind die Adjazenzmatrix und die Adjazenzliste, aber es gibt auch fortgeschrittene Varianten wie Kantenlisten oder Inzidenzmatrizen.
Adjazenzmatrix: Prinzip und Eigenschaften
Die Adjazenzmatrix ist eine quadratische Matrix der Größe |V| × |V|, wobei |V| die Anzahl der Knoten ist. Für einen ungewichteten Graphen enthält die Matrix an Position (i, j) eine 1, wenn eine Kante zwischen Knoten i und Knoten j existiert, andernfalls eine 0. Bei gewichteten Graphen wird das Gewicht der Kante anstelle der 1 eingetragen. Bei ungerichteten Graphen ist die Matrix symmetrisch, da eine Kante von i nach j gleichzeitig eine Kante von j nach i darstellt.
Die Adjazenzmatrix hat den Vorteil, dass die Abfrage, ob eine Kante zwischen zwei Knoten existiert, in konstanter Zeit O(1) erfolgt. Dies ist besonders nützlich für dichte Graphen, bei denen die Anzahl der Kanten nahe an |V|² liegt. Der Speicherbedarf beträgt O(|V|²), was bei großen Graphen mit vielen Knoten problematisch sein kann. Für Algorithmen wie den Floyd-Warshall-Algorithmus, der die kürzesten Pfade zwischen allen Knotenpaaren berechnet, ist die Adjazenzmatrix jedoch die natürliche Wahl.
Ein weiterer Nachteil der Adjazenzmatrix ist die ineffiziente Iteration über alle Nachbarn eines Knotens, da hierfür O(|V|) Zeit benötigt wird, selbst wenn der Knoten nur wenige Nachbarn hat. Für dünn besetzte Graphen (sparse graphs) ist dies suboptimal.
Adjazenzliste: Prinzip und Eigenschaften
Die Adjazenzliste ist die wohl am häufigsten verwendete Speicherstruktur für Graphen in der Praxis. Für jeden Knoten wird eine Liste seiner Nachbarn gespeichert. In der Regel wird ein Array von Listen verwendet, wobei der Index des Arrays dem Knoten entspricht. Bei gewichteten Graphen werden zusätzlich die Kantengewichte in der Liste gespeichert.
Der Speicherbedarf der Adjazenzliste beträgt O(|V| + |E|), was für dünn besetzte Graphen deutlich effizienter ist als die Adjazenzmatrix. Die Iteration über alle Nachbarn eines Knotens erfolgt in O(degree(v)) Zeit, wobei degree(v) die Anzahl der Nachbarn des Knotens ist. Dies macht die Adjazenzliste ideal für Algorithmen wie die Breitensuche (BFS) und Tiefensuche (DFS), die häufig auf die Nachbarn eines Knotens zugreifen müssen.
Die Abfrage, ob eine Kante zwischen zwei Knoten existiert, erfordert im schlimmsten Fall O(degree(v)) Zeit, da die Liste des Startknotens durchsucht werden muss. In ungerichteten Graphen kann dies optimiert werden, indem die Kanten in beiden Richtungen gespeichert werden. Die Adjazenzliste ist besonders geeignet für dynamische Graphen, bei denen häufig Knoten oder Kanten hinzugefügt oder entfernt werden.
Kantenliste: Prinzip und Eigenschaften
Die Kantenliste ist eine einfache, aber effektive Speicherstruktur, bei der alle Kanten des Graphen in einer Liste gespeichert werden. Jede Kante wird als Tupel (u, v) oder (u, v, w) für gewichtete Graphen dargestellt. Der Speicherbedarf beträgt O(|E|), was für sehr dünn besetzte Graphen optimal ist.
Die Kantenliste wird häufig in Algorithmen verwendet, die über alle Kanten iterieren müssen, wie der Kruskal-Algorithmus zur Berechnung des minimalen Spannbaums. Der Nachteil ist, dass die Abfrage der Nachbarn eines Knotens ineffizient ist, da die gesamte Kantenliste durchsucht werden muss, was O(|E|) Zeit erfordert. Daher ist die Kantenliste für Algorithmen, die häufige Nachbarschaftsabfragen benötigen, weniger geeignet.
Eine Variante der Kantenliste ist die komprimierte Kantenliste, die für bestimmte Anwendungen wie Graphen in der Computer Vision oder in der numerischen Simulation optimiert ist. Diese Variante speichert die Kanten in einem kompakten Format, das den Speicherbedarf weiter reduziert.
Inzidenzmatrix: Prinzip und Eigenschaften
Die Inzidenzmatrix ist eine Matrix der Größe |V| × |E|, wobei jede Spalte einer Kante und jede Zeile einem Knoten entspricht. Für einen ungerichteten Graphen enthält die Matrix an Position (i, j) eine 1, wenn Knoten i mit Kante j inzidiert. Für gerichtete Graphen wird häufig eine -1 für den Startknoten und eine 1 für den Endknoten verwendet.
Die Inzidenzmatrix wird seltener verwendet als die Adjazenzmatrix oder Adjazenzliste, hat aber spezielle Anwendungen in der Netzwerktheorie und bei der Analyse von bipartiten Graphen. Der Speicherbedarf beträgt O(|V| × |E|), was für große Graphen schnell prohibitiv wird. Die Inzidenzmatrix ist nützlich für Algorithmen, die Kantenoperationen in den Vordergrund stellen, wie die Berechnung von Schnitten oder Flüssen in Netzwerken.
Vergleich der Speicherstrukturen
Die Wahl der geeigneten Speicherstruktur hängt von mehreren Faktoren ab: der Dichte des Graphen, den auszuführenden Operationen und den Speicherbeschränkungen. Für dichte Graphen mit vielen Kanten ist die Adjazenzmatrix aufgrund der konstanten Abfragezeit oft die beste Wahl. Für dünn besetzte Graphen ist die Adjazenzliste in der Regel effizienter, sowohl in Bezug auf den Speicherverbrauch als auch auf die Iterationszeit.
Die Kantenliste ist ideal für Algorithmen, die über alle Kanten iterieren, während die Inzidenzmatrix für spezielle Anwendungen in der Netzwerktheorie reserviert ist. In der Praxis wird die Adjazenzliste am häufigsten verwendet, da sie eine gute Balance zwischen Speicherverbrauch und Zugriffszeit bietet und für die meisten Algorithmen geeignet ist.
Anwendungsszenarien von Graph-Speicherstrukturen
Graph-Speicherstrukturen finden in zahlreichen Bereichen Anwendung. In der Netzwerktechnologie werden sie zur Modellierung von Computernetzwerken verwendet, wobei die Adjazenzliste die bevorzugte Speicherstruktur für Routing-Algorithmen wie OSPF ist. In sozialen Netzwerken werden Graphen zur Darstellung von Freundschaftsbeziehungen genutzt, wobei die Adjazenzliste aufgrund der dünn besetzten Natur dieser Graphen ideal ist.
In der Bioinformatik werden Graphen zur Modellierung von Protein-Interaktionsnetzwerken verwendet, wobei die Adjazenzmatrix für die Analyse von dichten Subnetzen eingesetzt wird. In der Logistik und im Transportwesen werden Graphen zur Berechnung kürzester Wege in Straßennetzen verwendet, wobei die Kantenliste für den Kruskal-Algorithmus und die Adjazenzliste für den Dijkstra-Algorithmus genutzt wird.
In der knstlichen Intelligenz und im maschinellen Lernen werden Graphen für die Modellierung von Wissensgraphen und Empfehlungssystemen verwendet. Hier kommen häufig spezialisierte Speicherstrukturen wie die komprimierte Adjazenzliste oder die CSR-Format (Compressed Sparse Row) zum Einsatz, die für große Graphen mit Millionen von Knoten optimiert sind.
Fortgeschrittene Speicherstrukturen: CSR und CSCR
Das CSR-Format (Compressed Sparse Row) ist eine optimierte Variante der Adjazenzliste, die in der numerischen linearen Algebra und in Graphdatenbanken weit verbreitet ist. Es speichert die Nachbarn in einem flachen Array und verwendet zwei Hilfsarrays für die Zeiger und die Spaltenindizes. Dies reduziert den Speicher-Overhead und ermöglicht eine cache-effiziente Iteration über die Nachbarn eines Knotens.
Das CSCR-Format (Compressed Sparse Column Row) ist eine Erweiterung des CSR-Formats für gerichtete Graphen, die sowohl die eingehenden als auch die ausgehenden Kanten effizient speichert. Diese Speicherstruktur wird in Graph-Verarbeitungssystemen wie GraphX oder Pregel verwendet, die auf verteilten Systemen laufen.
Für Lernende ist es wichtig zu verstehen, dass die Wahl der Speicherstruktur nicht nur von theoretischen Überlegungen abhängt, sondern auch von praktischen Faktoren wie der Cache-Lokalität, der Speicherhierarchie und der Parallelisierbarkeit. Eine Datenstruktur-Visualisierungsplattform kann hier helfen, diese Konzepte durch interaktive Animationen und Echtzeit-Analysen besser zu verstehen.
Datenstruktur-Visualisierungsplattform: Funktionen und Vorteile
Eine spezialisierte Datenstruktur-Visualisierungsplattform bietet Lernenden die Möglichkeit, Graph-Speicherstrukturen in einer interaktiven Umgebung zu erkunden. Die Plattform ermöglicht es, Graphen visuell zu erstellen, zu bearbeiten und zu analysieren, wobei die zugrundeliegende Speicherstruktur in Echtzeit aktualisiert wird. Dies ist besonders wertvoll für visuelle Lerner, die abstrakte Konzepte besser verstehen, wenn sie sie in Aktion sehen können.
Die Plattform bietet eine Reihe von Funktionen, die speziell auf die Bedürfnisse von Algorithmen-Lernenden zugeschnitten sind. Dazu gehören die schrittweise Ausführung von Algorithmen mit detaillierten Erklärungen, die farbliche Hervorhebung von besuchten Knoten und Kanten, sowie die Anzeige von Metriken wie Zeitkomplexität und Speicherverbrauch in Echtzeit. Die Plattform unterstützt mehrere Speicherstrukturen gleichzeitig, sodass Lernende die Unterschiede zwischen Adjazenzmatrix, Adjazenzliste und Kantenliste direkt vergleichen können.
Ein weiterer Vorteil der Plattform ist die Möglichkeit, benutzerdefinierte Graphen zu erstellen und mit verschiedenen Algorithmen zu experimentieren. Lernende können beispielsweise einen Graphen mit der Adjazenzliste speichern und dann sehen, wie der Dijkstra-Algorithmus auf dieser Speicherstruktur arbeitet. Sie können dann zur Adjazenzmatrix wechseln und die Unterschiede in der Laufzeit und im Speicherverbrauch beobachten.
Die Plattform bietet auch eine Bibliothek vordefinierter Graphen aus der Praxis, wie Straßennetze, soziale Netzwerke oder Molekülstrukturen. Diese Beispiele helfen Lernenden, die Relevanz von Graph-Speicherstrukturen in der realen Welt zu verstehen. Darüber hinaus können Lernende eigene Algorithmen implementieren und testen, wobei die Plattform automatisch die Speicherstruktur anpasst und Optimierungsvorschläge macht.
Wie die Visualisierungsplattform das Lernen von Graph-Speicherstrukturen verbessert
Die Visualisierung von Graph-Speicherstrukturen hat mehrere pädagogische Vorteile. Erstens macht sie abstrakte Konzepte greifbar, indem sie zeigt, wie Daten tatsächlich im Speicher angeordnet sind. Lernende können sehen, dass die Adjazenzmatrix ein zusammenhängender Speicherblock ist, während die Adjazenzliste aus mehreren verstreuten Speicherblöcken besteht. Dies hilft, Konzepte wie Speicherlokalität und Cache-Effizienz zu verstehen.
Zweitens ermöglicht die Plattform das Experimentieren mit verschiedenen Szenarien. Lernende können beispielsweise testen, wie sich die Hinzufügung eines neuen Knotens auf die verschiedenen Speicherstrukturen auswirkt. Sie werden sehen, dass die Adjazenzmatrix eine vollständige Neuzuweisung des Speichers erfordert, während die Adjazenzliste nur eine neue Liste hinzufügt. Diese praktischen Erfahrungen vertiefen das Verständnis für die Kompromisse zwischen den verschiedenen Speicherstrukturen.
Drittens bietet die Plattform eine Echtzeit-Analyse der Algorithmusleistung. Wenn ein Lernender einen Algorithmus auf einem Graphen ausführt, zeigt die Plattform an, wie viele Speicherzugriffe durchgeführt werden, wie viele Cache-Fehler auftreten und wie die Laufzeit mit der Größe des Graphen skaliert. Diese Metriken helfen, die theoretischen Konzepte der Zeit- und Raumkomplexität mit der praktischen Leistung zu verbinden.
Viertens fördert die Plattform das aktive Lernen durch interaktive Übungen und Quizfragen. Lernende können aufgefordert werden, die optimale Speicherstruktur für einen bestimmten Graphen und Algorithmus zu wählen, und erhalten sofortiges Feedback zu ihrer Entscheidung. Dies festigt das Verständnis und hilft, häufige Fehler zu vermeiden.
Praktische Anwendung: Auswahl der richtigen Speicherstruktur
Die Wahl der richtigen Speicherstruktur ist entscheidend für die Effizienz von Graph-Algorithmen. Ein Beispiel aus der Praxis: Ein Student arbeitet an einem Projekt zur Analyse von sozialen Netzwerken mit 10 Millionen Nutzern und durchschnittlich 100 Freunden pro Nutzer. Die Adjazenzmatrix würde 10 Millionen × 10 Millionen = 100 Billionen Einträge erfordern, was etwa 400 Terabyte Speicherplatz benötigt. Die Adjazenzliste hingegen würde nur 10 Millionen + 1 Milliarde Einträge benötigen, was etwa 8 Gigabyte Speicherplatz entspricht. Die Wahl der Adjazenzliste ist hier offensichtlich.
Ein weiteres Beispiel: Ein Student implementiert den Floyd-Warshall-Algorithmus zur Berechnung der kürzesten Pfade zwischen allen Knotenpaaren in einem dichten Graphen mit 1000 Knoten. Hier ist die Adjazenzmatrix die richtige Wahl, da der Algorithmus auf die Matrix zugreift und die konstanten Zugriffszeiten der Matrix die Gesamtlaufzeit von O(|V|³) optimal unterstützen.
Die Visualisierungsplattform kann solche Szenarien simulieren und den Lernenden zeigen, wie die Wahl der Speicherstruktur die Leistung beeinflusst. Durch die interaktive Darstellung können Lernende die Auswirkungen ihrer Entscheidungen in Echtzeit sehen und ein intuitives Verständnis für die Kompromisse entwickeln.
Integration der Visualisierungsplattform in den Lernprozess
Die Datenstruktur-Visualisierungsplattform kann auf verschiedene Weise in den Lernprozess integriert werden. Für Anfänger bietet sie eine geführte Einfhrung in die Grundlagen der Graph-Speicherstrukturen, mit Schritt-für-Schritt-Tutorials und interaktiven Beispielen. Fortgeschrittene Lernende können die Plattform nutzen, um komplexe Algorithmen zu implementieren und zu testen, wobei die Plattform automatisch die Speicherstruktur anpasst und Optimierungen vorschlägt.
Die Plattform unterstützt auch kollaboratives Lernen, indem sie es mehreren Benutzern ermöglicht, gleichzeitig an demselben Graphen zu arbeiten. Dies ist besonders nützlich für Gruppenprojekte und Peer-Learning-Szenarien. Darüber hinaus können Lernende ihre Arbeit speichern und teilen, was den Austausch von Ideen und Lösungen fördert.
Ein weiteres wichtiges Feature ist die Integration mit gängigen Programmiersprachen wie Python, Java und C++. Lernende können Algorithmen in ihrer bevorzugten Sprache schreiben und die Ausführung auf der Plattform visualisieren. Dies schließt die Lücke zwischen theoretischem Verständnis und praktischer Implementierung.
Zukünftige Entwicklungen und Trends
Die Speicherstrukturen für Graphen entwickeln sich ständig weiter, um den Anforderungen moderner Anwendungen gerecht zu werden. Neue Trends wie die Verarbeitung von Graph-Daten auf GPUs, die Verwendung von nicht-flüchtigen Speichern (NVM) und die Integration von Graph-Datenbanken in Cloud-Umgebungen stellen neue Herausforderungen und Chancen dar. Die Visualisierungsplattform wird kontinuierlich aktualisiert, um diese neuen Entwicklungen zu unterstützen und den Lernenden die aktuellsten Werkzeuge und Techniken zu bieten.
Ein vielversprechender Trend ist die Verwendung von hybriden Speicherstrukturen, die die Vorteile mehrerer Ansätze kombinieren. Beispielsweise kann ein Graph in einer Adjazenzliste gespeichert werden, während eine separate Adjazenzmatrix für häufig abgefragte Knotenpaare vorgehalten wird. Die Visualisierungsplattform kann solche hybriden Ansätze demonstrieren und ihre Vor- und Nachteile in verschiedenen Szenarien aufzeigen.
Ein weiterer Trend ist die Integration von maschinellem Lernen in die Graph-Analyse. Speicherstrukturen müssen für Algorithmen des maschinellen Lernens wie Graph Neural Networks (GNNs) optimiert werden, die spezielle Anforderungen an die Speicherzugriffsmuster haben. Die Visualisierungsplattform kann diese fortgeschrittenen Themen zugänglich machen, indem sie die zugrundeliegenden Speicherstrukturen und ihre Auswirkungen auf die Leistung von GNNs visualisiert.
Fazit
Die Wahl der richtigen Speicherstruktur für Graphen ist eine der wichtigsten Entscheidungen bei der Implementierung von Graph-Algorithmen. Adjazenzmatrix, Adjazenzliste, Kantenliste und Inzidenzmatrix haben jeweils ihre Stärken und Schwächen, die von der Dichte des Graphen, den auszuführenden Operationen und den verfügbaren Ressourcen abhängen. Eine fundierte Kenntnis dieser Speicherstrukturen ist für jeden, der Datenstrukturen und Algorithmen lernt, unerlässlich.
Die Datenstruktur-Visualisierungsplattform bietet eine einzigartige Möglichkeit, diese Konzepte durch interaktive Visualisierungen, Echtzeit-Analysen und praktische Übungen zu erlernen. Sie macht abstrakte Konzepte greifbar, fördert das aktive Lernen und hilft, die Lücke zwischen Theorie und Praxis zu schließen. Ob Sie ein Anfänger sind, der die Grundlagen erlernen möchte, oder ein Fortgeschrittener, der seine Kenntnisse vertiefen will – die Plattform bietet die Werkzeuge, die Sie benötigen, um Graph-Speicherstrukturen wirklich zu verstehen und effektiv anzuwenden.
Durch die Kombination von theoretischem Wissen mit praktischer Erfahrung auf der Visualisierungsplattform können Lernende ein tiefes und intuitives Verständnis für Graph-Speicherstrukturen entwickeln, das ihnen in ihrer weiteren Karriere als Softwareentwickler, Datenwissenschaftler oder Forscher von großem Nutzen sein wird. Die Plattform ist nicht nur ein Lernwerkzeug, sondern auch ein wertvolles Hilfsmittel für die tägliche Arbeit mit Graph-Algorithmen und -Datenstrukturen.
❗️ 注意:
请注意,与树不同,图没有任何根节点。相反,图中的每个节点都可以与图中的每一个节点进行连接。当两个节点通过一条边连接时,这两个节点被称为相邻节点。例如,在上图中,节点A有两个邻居:B和D。