 图码
图码2.1 顺序表
💡 让我们以一个现实世界的例子来描述计算机中的数组。
想象你在一个图书馆,这个图书馆里有很多书架,每个书架上都有一排排的书。每本书都有一个特定的位置,你可以通过书架的编号和书的位置找到它。
在计算机中,数组就像这个图书馆中的书架一样。它是一个存储相同类型数据元素的数据结构。每个数据元素都有一个唯一的索引或位置,通过这个索引,你可以访问或修改特定位置的数据元素。
在计算机内存中,数组的元素是依次存储的,就像书架上的书一样。这样,计算机可以通过简单的数学运算来计算出元素的内存地址,从而快速访问数组中的任何元素。
数组是一种有效存储和访问大量相似数据的方式,就像图书馆中的书架一样可以帮助你组织和查找大量书籍。
数组是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。
数组中的元素存储在连续的内存位置中,并由一个索引(也称为下标)引用。下标是一个用于标识数组中的元素位置的序号。
2.1.1 数组的声明
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cnElemType:是我们要存放的数组元素的类型,类型可以是int, float,,double, char,或者其他可以使用的数据类型;
name:是用来表示数组的,称为数组名;
size:当前数组可以存放的最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn❗ 注意:
在本文后续中提到的所有
索引或下标 都是从 0 开始计数。
位序或第几个 都是从 1 开始计数。
在C 或者 C++ 中,数组索引从零开始。
第一个元素存储在array[0]中,第二个元素存储在array[1]中,以此类推。
因此,最后一个元素,即第6个元素,被存储在array[5]中。
在内存中,数组将如图所示进行存储。注意,方括号内写的0、1、2、3、4、5是下标。
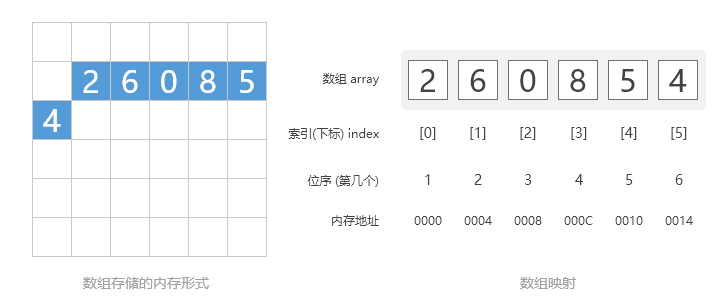
数组及内存结构
1 内存地址的计算
一个int类型的大小在内存中为4bytes。由于数组将其所有数据元素存储在连续的存储器位置中, 因此只需要知道数组首地址,即数组中第一个元素的地址就可以计算出该数组中其他元素的内存地址。
$$公式为:array[index] = base\_address + data\_type\_size \times index$$
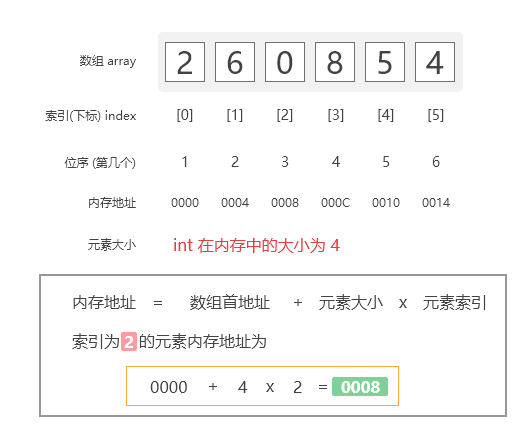
数组内存映射计算
由于数组元素是连续存储在内存的中的,所以我们可以很方便的访问任意一个元素。
就像你在图书馆的书架上查找一本特定的书时,如果你知道它的编号或位置,你可以直接走到该位置,而不必按顺序检查每本书。
在数组中访问元素是非常高效的,可以在$O(1)$时间内随机访问数组中的任意一个元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn在实际编码过程中,我们无需手动计算内存地址,因为每个元素占用大小相同的内存空间,数组元素的起始位置对于计算机也是已知的。 当我们在使用数组的下标来访问元素时,计算机可以通过上述的内存地址计算方法进行计算。
2 修改数组元素
需求:我们将index = 2即第 3 个元素的值修改为3。
操作步骤:
先找到$array[2]$的内存地址,使用上述公式:
$$\begin{split} array[2] &= base\_address + index \times data\_type\_size \\ \Rightarrow array[2] &= 0000 + 2 \times 4\\ \Rightarrow array[2] &= 0008 \end{split}$$
注意上面是计算内存地址,不是赋值
将内存地址为0xFFFF0008的值修改为3。
代码实现比较简单,计算机已自动帮助我们计算内存地址,我们只需提供对应的索引(index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn整个操作的时间复杂度为$O(1)$。
2.1.2 顺序表的介绍
💡 提示:
数组是一种数据结构,用于存储相同类型的元素的集合。
数组是一种顺序存储结构,元素在内存中按照一定的顺序依次存储。
那么数组和线性表的关系是什么呢?
线性表是一种数据结构,其中元素排列成一条线一样的顺序。
这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继。
线性表包括顺序表(数组实现)和链表等。
数组是一种实现线性表的方式之一。线性表可以通过数组来实现,也可以通过链表等其他结构来实现。
因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一。
通过数组实现的线性表称为顺序表。
1 顺序表的定义
线性表的顺序存储类型结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn定义了一个结构体SqList,包含两个成员变量:data和length。
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素。
2 顺序表的初始化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn这个函数的作用是将传入的顺序表 L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
2 在顺序表中插入元素
在顺序表中插入元素分为以下几种情况:
情况一:顺序表未满:插入在末尾
这种情况比较简单,我们只需要在当前最后一个元素的位置+1处直接赋值
例如:下面可视化窗口中的顺序表被声明为最大容量为10个元素,目前它存储了8个元素
步骤:
在末尾插入的位置为:9下标为:8 插入值5。
继续在末尾位置插入值:10
顺序表未满:插入末尾 | 可视化完整可视化
情况二:顺序表已满:不能再插入元素
上面可视化动画在插入了两个元素以后,顺序表总共有10个元素,那么我们将不能再向它添加元素,这种情况我们是不能进行插入的。
情况三:顺序表未满:插入在中间
如果想要在顺序表中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,给要插入的元素腾出位置,之后再把元素赋值给该索引。
步骤:
当前顺序表中已有8个元素,我们在下标为5位序为6处插入值10
注意代码中 i 为位序,不是下标
数组未满:插入在中间 | 可视化完整可视化
时间复杂度:
最好情况:如果插入操作发生在顺序表的末尾,并且顺序表有足够的空间,那么插入操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接在末尾添加元素不需要移动其他元素。
最坏情况:如果插入操作发生在顺序表的开头,需要将所有元素向后移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况: 平均情况下,需要移动插入位置后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
4 删除顺序表中的元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单。 我们只需要在当前存放元素的长度 -1 (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
步骤:
下面可视化面板中给出了最大容量为10的顺序表。
此时的顺序表内元素为{ 2, 6, 0, 8, 5, 4, 9, 8 },我们把下标为:3,位序为:4的元素删除掉。
❗ 注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它。
删除顺序表元素 | 可视化完整可视化
时间复杂度:
最好情况:如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素。
最差情况:如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况:平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序。
查找顺序表中的值 | 可视化完整可视化
2.1 Explicación detallada de la lista secuencial - Tutorial de Listas Lineales Visualiza tu código con animaciones

¿Qué es una Lista Lineal y una Tabla de Secuencia en Estructuras de Datos?
En el mundo de la programación y la informática, las estructuras de datos son fundamentales para organizar y gestionar la información de manera eficiente. Una de las estructuras más básicas y esenciales es la lista lineal, y dentro de ella, la tabla de secuencia (también conocida como lista secuencial o array dinámico). Para los estudiantes de algoritmos y estructuras de datos, comprender estos conceptos es el primer paso para dominar temas más complejos como pilas, colas y listas enlazadas.
Una lista lineal es una colección ordenada de elementos donde cada elemento tiene un predecesor (excepto el primero) y un sucesor (excepto el último). La tabla de secuencia es una implementación concreta de una lista lineal que utiliza un bloque contiguo de memoria para almacenar los datos. Esto significa que los elementos se colocan uno al lado del otro en la memoria RAM, lo que permite un acceso directo y rápido a cualquier posición mediante un índice.
Para los aprendices de habla hispana, es crucial entender que la tabla de secuencia es la base de estructuras como los arrays en Java, las listas en Python o los vectores en C++. Su simplicidad la convierte en la primera opción cuando se necesita almacenar datos de forma ordenada y acceder a ellos frecuentemente por su posición.
Principios Fundamentales de la Tabla de Secuencia
El principio operativo de una tabla de secuencia se basa en tres pilares: contigüidad física, acceso aleatorio y tamaño fijo o dinámico. La contigüidad física implica que todos los elementos se almacenan en direcciones de memoria consecutivas. Por ejemplo, si el primer elemento está en la dirección 1000, el segundo estará en 1004 (suponiendo que cada elemento ocupa 4 bytes), el tercero en 1008, y así sucesivamente.
El acceso aleatorio significa que podemos acceder directamente al elemento en la posición i sin necesidad de recorrer los elementos anteriores. Esto se logra mediante un simple cálculo: dirección_base + (i * tamaño_del_elemento). Esta característica hace que las operaciones de lectura y escritura por índice tengan una complejidad temporal de O(1), es decir, son instantáneas independientemente del tamaño de la lista.
En cuanto al tamaño, existen dos variantes principales: la tabla de secuencia estática, que tiene un tamaño fijo definido al crearla, y la dinámica, que puede crecer o reducirse durante la ejecución del programa. La versión dinámica es más flexible y se implementa comúnmente duplicando el tamaño del array subyacente cuando se llena, aunque esta operación de redimensionamiento tiene un costo de O(n).
Características y Propiedades Esenciales
Las tablas de secuencia poseen propiedades que las distinguen de otras estructuras de datos lineales. La localidad de referencia es una de sus ventajas más importantes: como los elementos están en posiciones contiguas de memoria, el procesador puede cachearlos eficientemente, mejorando el rendimiento en operaciones de recorrido.
Otra característica clave es la simplicidad de implementación. Con solo un array y un contador de tamaño, podemos gestionar una lista completa. Las operaciones básicas incluyen: insertar (al final, al inicio o en una posición específica), eliminar, buscar y actualizar. Sin embargo, es importante notar que insertar o eliminar elementos al inicio o en medio de la tabla requiere desplazar todos los elementos posteriores, lo que tiene un costo de O(n).
La eficiencia en memoria es otra propiedad destacable. A diferencia de las listas enlazadas, que requieren almacenar punteros adicionales para cada nodo, la tabla de secuencia solo almacena los datos reales, minimizando la sobrecarga de memoria. Esto la hace ideal para aplicaciones donde el espacio es crítico.
Aplicaciones Prácticas de la Tabla de Secuencia
Las tablas de secuencia son omnipresentes en el desarrollo de software. Una de sus aplicaciones más comunes es la implementación de listas de contactos en aplicaciones móviles, donde se necesita acceso rápido por índice para mostrar la lista completa. También se utilizan en sistemas de gestión de inventarios donde los productos se almacenan en orden y se accede a ellos por su código de posición.
En el ámbito de los videojuegos, las tablas de secuencia se usan para gestionar sprites, animaciones y listas de objetos en pantalla. La capacidad de acceder rápidamente a cualquier elemento por su índice permite renderizar escenas complejas de manera eficiente. Los compiladores también las emplean para almacenar tablas de símbolos, donde cada variable tiene una posición fija en memoria.
Otra aplicación importante es en sistemas embebidos y microcontroladores, donde la memoria es limitada y se requiere un control preciso sobre la disposición de los datos. Aquí, las tablas de secuencia estáticas son preferidas por su previsibilidad y bajo consumo de recursos. Incluso en inteligencia artificial, los vectores de características (feature vectors) son esencialmente tablas de secuencia que almacenan datos numéricos para algoritmos de machine learning.
Ventajas y Desventajas de las Tablas de Secuencia
Como toda estructura de datos, las tablas de secuencia tienen fortalezas y debilidades que todo estudiante debe conocer. Entre sus ventajas destacan:
- Acceso O(1) a cualquier elemento mediante su índice, ideal para aplicaciones que requieren consultas frecuentes por posición.
- Bajo consumo de memoria al no necesitar almacenar metadatos adicionales como punteros.
- Alta velocidad de recorrido gracias a la localidad de referencia y el cacheo del procesador.
- Implementación sencilla que reduce la probabilidad de errores en el código.
Sin embargo, también presentan desventajas significativas:
- Inserción y eliminación costosas (O(n)) en posiciones que no sean el final, debido al desplazamiento de elementos.
- Tamaño fijo en la versión estática, lo que puede llevar a desperdicio de memoria si se reserva demasiado espacio, o a desbordamiento si se reserva muy poco.
- Redimensionamiento costoso en la versión dinámica, ya que copiar todos los elementos a un nuevo array tiene un costo lineal.
- Fragmentación interna en la versión dinámica, donde puede haber espacio no utilizado si el array es más grande que la cantidad de elementos almacenados.
Cómo Aprender Tablas de Secuencia con un Visualizador de Estructuras de Datos
Para los estudiantes de habla hispana que están aprendiendo estructuras de datos, una herramienta visual puede marcar la diferencia entre la confusión y la comprensión profunda. Un visualizador de estructuras de datos es una plataforma interactiva que permite ver en tiempo real cómo se comportan las tablas de secuencia cuando realizamos operaciones como inserciones, eliminaciones y búsquedas.
Nuestra plataforma de visualización ofrece una representación gráfica de la memoria, mostrando cada elemento de la tabla de secuencia como un bloque numerado. Cuando insertas un elemento en medio de la lista, puedes observar cómo todos los elementos posteriores se desplazan una posición hacia la derecha, moviéndose físicamente en la pantalla. Esta animación ayuda a internalizar el costo computacional de O(n) de esta operación.
Además, el visualizador muestra el cálculo de direcciones de memoria en tiempo real. Al seleccionar un índice, la plataforma resalta la posición exacta en el array subyacente y muestra la fórmula dirección_base + (índice * tamaño) aplicada paso a paso. Esto es especialmente útil para estudiantes que están aprendiendo sobre gestión de memoria y punteros en lenguajes como C o C++.
Funcionalidades Clave de Nuestro Visualizador para Tablas de Secuencia
Nuestra plataforma de visualización de algoritmos y estructuras de datos está diseñada específicamente para facilitar el aprendizaje de conceptos complejos. Para las tablas de secuencia, ofrecemos las siguientes funcionalidades:
1. Modo paso a paso: Puedes ejecutar cada operación (insertar, eliminar, buscar) paso a paso, observando cómo cambia el estado de la tabla después de cada instrucción. Esto es ideal para seguir el flujo del algoritmo y entender exactamente qué sucede en cada momento.
2. Control de velocidad: Ajusta la velocidad de las animaciones para que puedas seguir el proceso a tu propio ritmo. Los principiantes pueden ralentizar las animaciones para no perderse ningún detalle, mientras que los más avanzados pueden acelerarlas para repasar rápidamente.
3. Visualización de memoria: La plataforma muestra una representación detallada de la memoria RAM, incluyendo las direcciones de memoria reales (simuladas) de cada elemento. Esto ayuda a comprender el concepto de contigüidad física y cómo se calculan las direcciones.
4. Comparación de complejidades: Para cada operación, el visualizador muestra la complejidad temporal en notación Big O y la compara con otras estructuras como listas enlazadas. Por ejemplo, al insertar al inicio, verás que la tabla de secuencia tiene O(n) mientras que la lista enlazada tiene O(1).
5. Ejemplos predefinidos: Incluimos casos de uso comunes, como la implementación de una pila o una cola usando una tabla de secuencia, con animaciones que muestran cómo se comporta la estructura en cada escenario.
Ventajas de Usar un Visualizador Interactivo para Estudiar Estructuras de Datos
Los métodos tradicionales de aprendizaje, como leer libros de texto o ver diagramas estáticos, tienen limitaciones cuando se trata de comprender procesos dinámicos. Un visualizador interactivo ofrece ventajas que aceleran significativamente la curva de aprendizaje:
Retroalimentación inmediata: Cuando cometes un error al implementar un algoritmo, el visualizador te muestra exactamente dónde falló la lógica y cómo afectó a la estructura de datos. Esto es mucho más efectivo que depurar código ciegamente.
Comprensión multinivel: Puedes alternar entre ver la tabla de secuencia a nivel abstracto (como una lista de elementos) y a nivel de memoria (con direcciones y bytes). Esto ayuda a conectar conceptos teóricos con su implementación práctica.
Aprendizaje autodirigido: Puedes experimentar libremente, probando operaciones en diferentes órdenes y observando los resultados. Esta exploración activa fomenta un entendimiento más profundo que la simple lectura pasiva.
Visualización de casos límite: La plataforma te permite probar situaciones extremas, como insertar en una tabla llena, eliminar el último elemento o buscar un elemento inexistente. Ver cómo se manejan estos casos te prepara para escribir código robusto.
Cómo Usar Nuestra Plataforma para Dominar las Tablas de Secuencia
Para aprovechar al máximo nuestro visualizador de estructuras de datos, te recomendamos seguir este flujo de aprendizaje estructurado:
Paso 1: Explora la interfaz - Familiarízate con los controles básicos: botones de insertar, eliminar, buscar y mostrar. Observa cómo se representa la tabla de secuencia en la pantalla principal y cómo se actualiza la información de memoria en el panel lateral.
Paso 2: Sigue los tutoriales guiados - Nuestra plataforma incluye tutoriales interactivos que te llevan paso a paso por las operaciones fundamentales. Comienza con "Insertar al final" y progresa hasta "Insertar en medio" para entender el desplazamiento de elementos.
Paso 3: Experimenta libremente - Una vez que entiendas los conceptos básicos, prueba tus propias secuencias de operaciones. Intenta crear una tabla de 10 elementos, luego elimina el tercero, inserta uno nuevo en la quinta posición y busca un valor específico. Observa cómo cambia la estructura en cada paso.
Paso 4: Compara con otras estructuras - Utiliza la función de comparación para ver cómo se comportaría la misma secuencia de operaciones en una lista enlazada. Notarás las diferencias en velocidad de inserción y acceso, lo que te ayudará a elegir la estructura adecuada para cada problema.
Paso 5: Resuelve problemas prácticos - La plataforma incluye ejercicios integrados donde debes implementar algoritmos usando tablas de secuencia. Por ejemplo, "Invertir una lista" o "Eliminar duplicados". El visualizador te guiará y verificará tu solución.
Aplicaciones del Mundo Real que Puedes Simular
Nuestro visualizador no solo enseña teoría, sino que también te permite simular aplicaciones del mundo real. Por ejemplo, puedes modelar un sistema de gestión de colas de un banco usando una tabla de secuencia. Cada cliente llega y se coloca al final de la cola (insertar al final), y cuando un cajero se libera, el primer cliente es atendido (eliminar al inicio). Verás cómo el desplazamiento de elementos afecta el rendimiento cuando la cola es larga.
Otra simulación útil es un historial de navegación web. Cuando visitas una página, se añade al final del historial. Cuando presionas "atrás", eliminas la última página. Pero si retrocedes y luego visitas una nueva página, el historial se trunca. Esta lógica se puede implementar fácilmente con una tabla de secuencia y visualizar en nuestra plataforma.
También puedes simular un buffer circular para transmisión de datos en redes, donde los paquetes se almacenan temporalmente en un array y se procesan en orden. Aunque el buffer circular usa una lógica diferente, entender primero la tabla de secuencia básica es esencial para comprender esta variante más avanzada.
Errores Comunes al Trabajar con Tablas de Secuencia y Cómo Evitarlos
Nuestra plataforma de visualización está diseñada para ayudarte a identificar y corregir errores comunes. Uno de los más frecuentes es el desbordamiento de índice, cuando intentas acceder a una posición que no existe (por ejemplo, índice 10 en una tabla de 5 elementos). El visualizador te mostrará inmediatamente un error visual, resaltando el índice inválido y explicando por qué es incorrecto.
Otro error típico es olvidar desplazar elementos al insertar en medio. Si simplemente sobrescribes la posición sin mover los elementos posteriores, perderás datos. La plataforma detecta esta situación y te alerta, mostrando cómo los elementos se superponen incorrectamente.
El desperdicio de memoria es otro problema común en tablas de secuencia estáticas. Nuestro visualizador te muestra gráficamente la diferencia entre el tamaño reservado y el tamaño utilizado, ayudándote a entender por qué es importante elegir un tamaño adecuado o usar una implementación dinámica.
Consejos para Profundizar en el Estudio de Tablas de Secuencia
Una vez que domines los conceptos básicos usando nuestro visualizador, te recomendamos explorar temas avanzados. Estudia la tabla de secuencia dinámica y cómo se implementa el redimensionamiento. Observa en la plataforma cómo se duplica el tamaño cuando la tabla se llena y cómo se copian todos los elementos al nuevo array.
Investiga también las variantes especializadas como la tabla de secuencia ordenada, donde los elementos se mantienen siempre en orden ascendente. Nuestro visualizador incluye un modo especial para esto, mostrando cómo la inserción requiere encontrar la posición correcta mediante búsqueda binaria (O(log n)) y luego desplazar elementos (O(n)).
Finalmente, practica la implementación en diferentes lenguajes de programación. Nuestra plataforma te permite ver el código equivalente en Python, Java, C++ y JavaScript para cada operación que realices visualmente. Esto te ayudará a conectar la teoría con la práctica de programación real.
Conclusión: La Tabla de Secuencia como Fundamento de tu Aprendizaje
La tabla de secuencia es mucho más que una simple estructura de datos; es la base sobre la que se construyen conceptos más avanzados como árboles, grafos y tablas hash. Dominarla te dará una comprensión sólida de cómo se organiza la memoria y cómo optimizar el acceso a los datos en tus programas.
Nuestro visualizador de estructuras de datos está diseñado para acompañarte en este viaje de aprendizaje, ofreciéndote una experiencia interactiva que ningún libro de texto puede igualar. Al ver las operaciones en acción, comprenderás no solo el "qué" sino también el "cómo" y el "por qué" de cada algoritmo.
Te invitamos a explorar nuestra plataforma y comenzar tu aprendizaje hoy mismo. Con práctica constante y el uso de herramientas visuales, pronto podrás resolver problemas complejos de programación con confianza y eficiencia. Recuerda que cada gran programador comenzó dominando los fundamentos, y la tabla de secuencia es uno de los más importantes.
时间复杂度:
最好情况:要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为$O(1)$,即常数时间复杂度。
最坏情况:要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中。在这种情况下,时间复杂度为$O(n)$,其中$n$是顺序表中元素的个数。
平均情况:平均情况的时间复杂度通常是$O(\frac n 2)$,因为平均而言,我们可以认为要查找的元素在顺序表的中间位置。但是在大$O$表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是$O(n)$。
2.1.3 顺序表数组实现的优点与缺点
1 优点
随机访问速度快:由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 $O(1)$。这使得数组在需要频繁随机访问元素的情况下非常高效。
节约空间:相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间。
缓存友好:由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势。
2 缺点
固定大小:数组的大小是固定的,一旦创建后就不能动态改变。如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销。
插入和删除操作效率低:在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 $O(n)$。这使得数组在频繁插入和删除操作的场景下效率较低。
不适合存储变长数据:由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求。