 图码
图码1.1 什么是数据结构?
在计算机世界中,数据结构代表了计算机在内存中存储和组织数据的独特方法。通过不同的排列和组合方式,可以使用户高效且适当的方式访问和使用他们所需的数据。
数据结构的存在使用户能够方便地按需访问和操作他们的数据,有助于以高效而紧凑的方式组织和检索各种类型的数据。
对于接触过计算机基础知识的读者而言,对于下面这个公式应该不会陌生:
算法 + 数据结构 = 程序
提出这一公式并以此作为其一本专著书名Algorithms + Data Structures = Programs的瑞士计算机科学家Niklaus Wirth于1984年获得了图灵奖。
程序(Program)是由数据结构(Data Structure)和算法(Algorithm)组成,这意味着的程序的好和快是直接由程序所采用的数据结构和算法决定的。
❗️ 注意
本章节仅作介绍,涉及到的具体数据结构和算法会在后续章节中详细讲解。
数据结构分类
数据也可以被细分为以下两种类型:
线性结构
非线性结构
线性结构
数据元素按顺序或者线性排列
除了第一个元素和最后一个元素之外,剩余每个元素都有前一个和下一个相邻元素。
有两种技术可以在内存中表示这种线性结构。
数组:存储在连续内存位置的相同数据类型的项目的集合。
链表:通过使用指针或链接的概念来表示的所有元素之间的线性关系。
常见的线性结构例子有:
数组:存储在连续内存位置的元素的集合。
链表:节点的集合,每个节点包含一个元素和对下一个节点的引用。
堆栈:具有后进先出 (LIFO)顺序的元素集合。
队列:具有先进先出 (FIFO)顺序的元素集合。
非线性结构
该结构主要用于表示包含各种元素之间的层次关系的数据。
常见的非线性结构例子有:
图:顶点(节点)和表示顶点之间关系的边的集合。图用于建模和分析网络,例如社交网络或交通网络。
树:树的结构呈现出一个类似根和分支的形状,其中有一个根节点,从根节点出发,分成多个子节点,每个子节点可以又分为更多的子节点,依此类推
各种数据结构的简单介绍
数组(Arrays)
数组是相似数据元素的集合。这些数据元素具有相同的数据类型。
数组的元素存储在连续的内存位置中,并由索引(也称为下标)来指向数据。
在C语言中,数组声明使用以下格式:
- 1
- 2
- 3
ElemType name[size];
//例如
char array[10] = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'
// 完整代码:https://totuma.cn上面的语句声明了一个包含10个元素的数组标记。 在C中,数组索引从零开始。这意味着数组标记将总共包含10个元素。
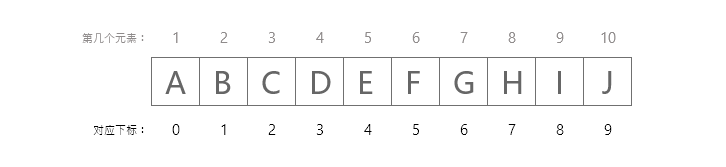
数组下标对应位序
第一个元素将存储在array[0]中,第二个元素将存储在array[1]中,等等。因此,最后一个元素,即第10个元素,将被存储在array[9]中。 在计算机中存储如下图所示。
当我们想要存储大量相同类型的数据时,通常会使用数组。当然,数组也有一些限制,比如:
数组的大小是固定的。
数据元素存储在连续的内存位置中,但是内存中剩余的大小可能不足以容纳当前数组。
元素的插入和删除会很麻烦。
链表(Linked Lists)
链表是一种非常灵活的动态数据结构,其中元素(称为节点)形成一个顺序列表。 与静态数组相比,我们不需要担心链表中将存储多少个元素。这个特性使我们能够编写需要较少维护的健壮程序。在链表中,每个节点都有data域和next指针域:
data域:存放该节点或与该节点对应的任何其他数据的值。
next指针域:指向列表中的下一个节点的指针或链接。
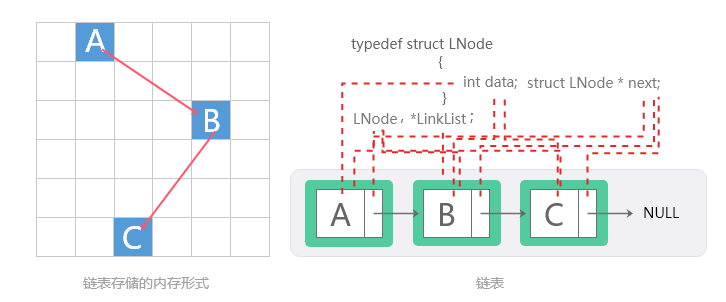
链表结构
列表中的最后一个节点包含一个NULL指针,表明它是当前列表的尾。由于节点的内存是在添加到列表中时动态分配的,因此可以添加到列表中的节点总数仅受可用内存量的限制。具体结构可见下图:
栈(Stacks)
栈是一种线性数据结构, 其中元素的插入和删除只在一端完成,这被称为栈顶。 栈被称为先入后出(LIFO)结构,因为添加到堆栈中的最后一个元素是从堆栈中删除的第一个元素。在计算机的内存中,堆栈可以使用数组或链表来实现。
下面可视化操作显示了一个栈的数组实现。每个栈都有一个与其关联的变量top,用于指向最上面的元素。这是将从中添加或删除元素的位置。
栈支持push 入栈和pop 出栈 操作,push 就是在从栈顶中压入一个元素,pop 就是在栈顶中弹出一个元素,即增和删。
💡 提示
点击下方的入栈、出栈按钮。可以明了的理解到什么是先入后出。
栈 | 可视化完整可视化
1.1 ¿Qué es una estructura de datos? - Tutorial de Estructuras de Datos Visualiza tu código con animaciones

Estructuras de Datos Lineales: Tabla Lineal, Pila y Tabla Secuencial
Bienvenido al mundo de las estructuras de datos. Si estás aprendiendo algoritmos y estructuras de datos, seguramente te has topado con términos como tabla lineal, pila y tabla secuencial. Estos conceptos son fundamentales para organizar la información en la memoria de una computadora. En este artículo te explicaremos de forma clara y sencilla qué son, cómo funcionan, dónde se aplican y cómo puedes visualizarlos paso a paso usando nuestra plataforma de visualización de estructuras de datos.
¿Qué es una estructura de datos lineal?
Una estructura de datos lineal organiza los elementos uno detrás de otro, formando una secuencia. Cada elemento tiene un predecesor y un sucesor (excepto el primero y el último). Los ejemplos más comunes son la lista lineal, la pila y la cola. La tabla secuencial (también llamada arreglo o array) es la forma más básica de implementar una lista lineal. En este artículo nos centraremos en la tabla lineal, la pila y la tabla secuencial, y cómo se relacionan entre sí.
Tabla Secuencial (Arreglo o Array)
Una tabla secuencial es una colección de elementos almacenados en posiciones contiguas de memoria. Cada elemento se accede mediante un índice numérico. Por ejemplo, si tienes un arreglo de enteros de tamaño 5, puedes acceder al primer elemento con índice 0, al segundo con índice 1, y así sucesivamente.
Características principales:
- Acceso directo: Puedes leer o escribir cualquier elemento en tiempo constante O(1) si conoces su índice.
- Tamaño fijo: En la mayoría de los lenguajes, el tamaño se define al crear el arreglo y no puede cambiar dinámicamente (aunque existen versiones dinámicas como ArrayList o vector).
- Inserción y eliminación costosas: Si insertas o eliminas un elemento al inicio o en medio, debes desplazar todos los elementos siguientes, lo que toma tiempo O(n).
Ejemplo de uso: Una tabla secuencial es ideal cuando necesitas acceso rápido a elementos por posición, como en una lista de reproducción de música donde conoces el número de canción.
Lista Lineal (Lista Enlazada)
Una lista lineal (también conocida como lista enlazada) es una secuencia de nodos donde cada nodo contiene un dato y un puntero al siguiente nodo. A diferencia de la tabla secuencial, los nodos no están en posiciones contiguas de memoria; se enlazan mediante punteros.
Tipos de listas lineales:
- Lista simplemente enlazada: Cada nodo apunta solo al siguiente. El último nodo apunta a null.
- Lista doblemente enlazada: Cada nodo apunta al siguiente y al anterior, permitiendo recorrerla en ambos sentidos.
- Lista circular: El último nodo apunta al primero, formando un ciclo.
Características principales:
- Inserción y eliminación eficientes: Si tienes un puntero al nodo adecuado, puedes insertar o eliminar en tiempo O(1).
- Acceso secuencial: Para llegar al elemento en la posición i, debes recorrer desde la cabeza hasta esa posición, lo que toma O(n).
- Uso dinámico de memoria: No necesitas definir un tamaño fijo; los nodos se asignan bajo demanda.
Ejemplo de uso: Las listas enlazadas se usan en sistemas donde se requieren muchas inserciones y eliminaciones, como en editores de texto para manejar el historial de cambios.
Pila (Stack)
Una pila es una estructura de datos lineal que sigue el principio LIFO (Last In, First Out), es decir, el último elemento que se inserta es el primero en salir. Imagina una pila de platos: solo puedes agregar o quitar platos de la parte superior.
Operaciones básicas:
- push: Agrega un elemento a la cima de la pila.
- pop: Elimina y devuelve el elemento de la cima.
- peek o top: Devuelve el elemento de la cima sin eliminarlo.
- isEmpty: Verifica si la pila está vacía.
Características principales:
- Acceso restringido: Solo puedes interactuar con el elemento superior.
- Operaciones eficientes: push, pop y peek se realizan en tiempo O(1).
- Implementación común: Se puede implementar con un arreglo (tabla secuencial) o con una lista enlazada.
Ejemplos de uso:
- Evaluación de expresiones matemáticas: Las pilas se usan para convertir notación infija a postfija y para evaluar expresiones.
- Llamadas a funciones: El sistema operativo usa una pila para gestionar las llamadas a funciones y las variables locales.
- Deshacer (undo) en aplicaciones: Cada acción se apila y al deshacer se desapila.
Relación entre tabla secuencial, lista lineal y pila
La tabla secuencial y la lista lineal son dos formas de implementar una secuencia de elementos. La pila es un tipo especial de lista lineal con restricciones de acceso. De hecho, puedes implementar una pila usando un arreglo (tabla secuencial) o una lista enlazada. La elección depende de las necesidades de tu algoritmo:
- Si necesitas acceso rápido a cualquier elemento, usa una tabla secuencial.
- Si necesitas inserciones y eliminaciones frecuentes en cualquier posición, usa una lista enlazada.
- Si solo necesitas trabajar con el elemento más reciente, una pila es la opción ideal.
Aplicaciones en el mundo real
Estas estructuras están presentes en casi todos los programas que usas a diario:
- Tabla secuencial: Bases de datos (índices), matrices en gráficos por computadora, buffers de audio.
- Lista lineal: Navegación web (historial), reproducción de música (listas de reproducción), sistemas de archivos.
- Pila: Navegador web (botón de atrás), editor de código (deshacer), algoritmo de búsqueda en profundidad (DFS).
¿Cómo puede ayudarte una plataforma de visualización?
Aprender estructuras de datos solo con teoría puede ser abstracto y difícil. Nuestra plataforma de visualización de estructuras de datos está diseñada para que puedas ver exactamente cómo se comportan estas estructuras en tiempo real. Aquí te explicamos sus principales funcionalidades y ventajas:
Visualización paso a paso
Puedes ejecutar operaciones como push, pop, insertar, eliminar y buscar en una tabla secuencial, lista lineal o pila, y la plataforma mostrará gráficamente cómo se mueven los datos. Por ejemplo, al hacer push en una pila, verás cómo el nuevo elemento se coloca en la cima y cómo se ilumina la memoria ocupada.
Simulación de memoria
La herramienta representa la memoria de la computadora como una cuadrícula, mostrando las direcciones de memoria y el contenido de cada celda. Esto te ayuda a comprender conceptos como la contigüidad en arreglos y los punteros en listas enlazadas.
Comparación de rendimiento
Puedes medir el tiempo que tarda cada operación en diferentes estructuras. Por ejemplo, compara la inserción al inicio en un arreglo vs. una lista enlazada. Verás gráficamente por qué una es O(n) y la otra O(1).
Editor de código integrado
La plataforma incluye un editor donde puedes escribir tu propio código (en C++, Java, Python o JavaScript) para implementar estas estructuras. Al ejecutarlo, la visualización se sincroniza con tu código, mostrando cómo se ejecuta línea por línea.
Ejercicios interactivos
Ofrecemos ejercicios prácticos donde debes completar operaciones en una estructura para lograr un objetivo. Por ejemplo, "invierte una lista enlazada" o "evalúa esta expresión usando una pila". La plataforma te dará retroalimentación inmediata.
¿Cómo usar la plataforma para aprender estas estructuras?
Sigue estos pasos para aprovechar al máximo la herramienta:
- Selecciona la estructura: En el menú principal, elige "Tabla secuencial", "Lista lineal" o "Pila".
- Configura el tamaño inicial: Para la tabla secuencial, define el número de elementos. Para la lista, puedes comenzar con una lista vacía.
- Ejecuta operaciones: Usa los botones de la interfaz (push, pop, insertar, etc.) o escribe comandos en la consola.
- Observa la animación: Cada operación se muestra con animaciones suaves. Los elementos cambián de color, se mueven o se resaltan.
- Revisa el pseudocódigo: La plataforma muestra el pseudocódigo correspondiente a la operación actual, ayudándote a conectar la teoría con la práctica.
- Realiza los ejercicios: Ve a la sección de ejercicios y pon a prueba tu comprensión.
Ventajas de usar un visualizador de estructuras de datos
- Aprendizaje activo: No solo lees, sino que ves y manipulas las estructuras.
- Depuración visual: Si tu código no funciona, puedes ver exactamente dónde falla la lógica.
- Preparación para entrevistas: Muchas preguntas técnicas involucran estas estructuras. Visualizarlas te ayuda a entender los algoritmos clásicos.
- Acceso gratuito y multiplataforma: Funciona en cualquier navegador, sin necesidad de instalar nada.
Conclusión
Dominar las estructuras de datos lineales como la tabla secuencial, la lista lineal y la pila es esencial para cualquier programador. No solo te ayudarán a escribir código más eficiente, sino que también son la base de algoritmos más complejos. Nuestra plataforma de visualización está aquí para que puedas experimentar con ellas de forma interactiva y divertida. Te invitamos a explorar los ejemplos, hacer los ejercicios y compartir tus resultados con otros estudiantes.
Recuerda: la mejor forma de aprender es practicando. ¡Empieza hoy mismo a visualizar tus estructuras de datos!
队列(Queues)
队列是一种先进先出(FIFO)的数据结构,其中首先插入的元素是第一个要取出的元素。 队列中的元素在队尾添加,然后在队头删除。 与栈一样,队列也可以通过使用数组或链表来实现。 每个队列都有队头和队尾,分别指向可以进行删除和插入的位置。
队列 | 可视化完整可视化
1.1 ¿Qué es una estructura de datos? - Tutorial de Estructuras de Datos Visualiza tu código con animaciones
Cola (Queue) con Tabla de Secuencia: Guía Completa para Estudiantes de Estructuras de Datos
Bienvenido, estudiante de estructuras de datos. Si estás buscando entender cómo funciona una cola (queue) implementada mediante una tabla de secuencia (顺序表), has llegado al lugar indicado. Este artículo está diseñado para que aprendas de forma clara y visual, y además descubrirás cómo una plataforma de visualización de algoritmos puede transformar tu forma de estudiar.
¿Qué es una Cola (Queue)?
Una cola es una estructura de datos lineal que sigue el principio FIFO (First In, First Out), es decir, el primer elemento en entrar es el primero en salir. Piensa en una fila de personas en un banco: la primera persona que llega es la primera en ser atendida. En informática, las colas se utilizan para gestionar tareas en orden de llegada, como en sistemas de impresión, gestión de procesos o enrutamiento de paquetes de red.
¿Qué es una Tabla de Secuencia (顺序表)?
Una tabla de secuencia es una implementación de una estructura de datos lineal que utiliza un arreglo (array) contiguo en memoria. Los elementos se almacenan uno tras otro, lo que permite un acceso rápido por índice (O(1)). En el contexto de una cola, la tabla de secuencia actúa como el contenedor subyacente que almacena los elementos de la cola.
Principios Fundamentales de la Cola con Tabla de Secuencia
Al implementar una cola con una tabla de secuencia, debemos gestionar dos punteros o índices clave:
- Frente (front): Índice del primer elemento que será eliminado (el que lleva más tiempo en la cola).
- Final (rear): Índice donde se insertará el próximo elemento nuevo.
Las operaciones básicas son:
- Enqueue (encolar): Agregar un elemento al final de la cola. Se incrementa el índice rear y se coloca el valor en esa posición.
- Dequeue (desencolar): Eliminar el elemento del frente de la cola. Se devuelve el valor en la posición front y se incrementa front.
- Front (frente): Consultar el valor del primer elemento sin eliminarlo.
- IsEmpty (está vacía): Verificar si la cola no tiene elementos.
Problema Común: Desperdicio de Espacio y Solución Circular
Cuando usamos una tabla de secuencia simple (lineal), después de varias operaciones de encolar y desencolar, los índices front y rear se mueven hacia la derecha. Esto provoca que las posiciones anteriores a front queden vacías pero inutilizables, lo que se conoce como desperdicio de espacio. Para solucionarlo, se utiliza una cola circular, donde el arreglo se trata como un círculo lógico. Cuando rear llega al final del arreglo, vuelve al inicio si hay espacio disponible.
Características Clave de la Cola con Tabla de Secuencia
Al estudiar esta implementación, debes tener en cuenta:
- Acceso eficiente: Las operaciones de encolar y desencolar tienen complejidad O(1) en promedio, siempre que no se requiera redimensionar el arreglo.
- Redimensionamiento dinámico: Si la tabla de secuencia es estática, la cola tiene un tamaño fijo. Si es dinámica, se puede duplicar el tamaño cuando esté llena, lo que tiene un costo O(n) ocasional.
- Uso de memoria contigua: Los elementos se almacenan en posiciones consecutivas, lo que mejora la localidad de caché.
- Implementación sencilla: Es fácil de entender y depurar, ideal para estudiantes que se inician en estructuras de datos.
Aplicaciones Reales de la Cola
La cola es una estructura fundamental en informática. Algunas aplicaciones prácticas incluyen:
- Sistemas operativos: Gestión de procesos (cola de listos), manejo de interrupciones y planificación de discos.
- Redes: Colas de paquetes en routers, gestión de tráfico y buffers.
- Aplicaciones de usuario: Cola de impresión, sistema de tickets en línea, y colas de mensajes en sistemas distribuidos.
- Algoritmos: BFS (Breadth-First Search) en grafos, que utiliza una cola para explorar niveles.
Visualización de la Cola: Aprende con una Plataforma Interactiva
Entender cómo se mueven los punteros front y rear dentro de una tabla de secuencia puede ser abstracto al principio. Por eso, una plataforma de visualización de algoritmos y estructuras de datos es tu mejor aliada. Estas herramientas te permiten ver paso a paso cada operación, observar cómo se llena y vacía la cola, y cómo se comporta la versión circular.
¿Qué es una Plataforma de Visualización de Estructuras de Datos?
Es un entorno web interactivo donde puedes ejecutar algoritmos y ver representaciones gráficas de las estructuras de datos en tiempo real. En lugar de solo leer teoría, puedes ver cómo se inserta un elemento, cómo se mueve el frente, y cómo se gestiona el espacio en el arreglo. Algunas plataformas incluso te permiten modificar el código y experimentar.
Funcionalidades Clave de una Plataforma de Visualización
- Animaciones en vivo: Cada operación (encolar, desencolar) se muestra con animaciones que resaltan los índices afectados.
- Control de velocidad: Puedes ralentizar o acelerar la ejecución para entender cada detalle.
- Visualización de memoria: Se muestra el arreglo subyacente con colores que indican posiciones ocupadas, libres o eliminadas.
- Modo paso a paso: Avanzas manualmente por cada instrucción, ideal para análisis profundo.
- Editor de código integrado: Muchas plataformas te permiten escribir tu propia implementación y visualizarla al instante.
Ventajas de Usar una Plataforma de Visualización para Estudiar Colas
- Comprensión intuitiva: Ver el movimiento de los punteros y los cambios en el arreglo hace que el concepto FIFO sea mucho más tangible.
- Detección de errores: Si implementas mal una cola circular, la visualización te mostrará inmediatamente el problema (por ejemplo, sobrescritura de datos).
- Experimentación sin miedo: Puedes probar casos extremos (cola llena, cola vacía) sin afectar un sistema real.
- Aprendizaje autodidacta: Ideal para estudiantes que quieren repasar o profundizar por su cuenta.
Cómo Usar la Plataforma para Estudiar la Cola con Tabla de Secuencia
Sigue estos pasos para aprovechar al máximo la herramienta:
- Selecciona la estructura: En la plataforma, elige “Cola (Queue)” y luego “Implementación con Tabla de Secuencia”.
- Observa la representación inicial: Verás un arreglo vacío con los índices front y rear apuntando a -1 o 0.
- Realiza operaciones: Usa los botones “Enqueue” e “Ingresa un valor”. Mira cómo rear avanza y el elemento aparece en el arreglo.
- Prueba la versión circular: Si la plataforma lo permite, activa el modo circular. Encola varios elementos y luego desencola algunos. Observa cómo rear da la vuelta al inicio.
- Analiza la complejidad: Presta atención a cuándo se necesita redimensionar el arreglo (si es dinámico) y cómo afecta el rendimiento.
Ejemplo Práctico: Simulación de una Cola de Impresión
Imagina que estás simulando una cola de impresión en una oficina. Los trabajos de impresión llegan en orden y se imprimen en el mismo orden. Con la plataforma de visualización, puedes:
- Agregar trabajos con diferentes tamaños (por ejemplo, “Doc1.pdf”, “Foto.jpg”).
- Ver cómo la cola se llena y cómo el puntero front avanza cuando el trabajo se “imprime” (se desencola).
- Comprobar qué sucede si la cola está llena (en una implementación estática) y cómo se maneja el error.
Comparativa: Cola con Tabla de Secuencia vs. Cola con Lista Enlazada
Como estudiante, es útil conocer las diferencias:
- Tabla de secuencia: Acceso O(1) por índice, pero puede requerir redimensionamiento. Mejor localidad de caché.
- Lista enlazada: No tiene límite de tamaño (a menos que se acabe la memoria), pero cada nodo consume espacio extra para el puntero. Peor localidad de caché.
La plataforma de visualización te permite comparar ambas implementaciones lado a lado, viendo cómo se comportan en tiempo real.
Consejos para Dominar la Cola con Tabla de Secuencia
- Practica con ejercicios: Implementa la cola desde cero en tu lenguaje favorito y luego visualízala en la plataforma para verificar.
- Analiza casos límite: ¿Qué ocurre cuando encolas en una cola llena? ¿Y cuando desencolas en una cola vacía?
- Estudia la cola circular: Comprende cómo se calcula el nuevo índice (por ejemplo,
(rear + 1) % tamaño). - Usa la plataforma para repasar: Antes de un examen, simula operaciones aleatorias para reforzar la lógica.
Preguntas Frecuentes (FAQ)
¿Por qué se llama “tabla de secuencia”? Porque los elementos se almacenan en una secuencia contigua en memoria, a diferencia de una lista enlazada que usa nodos dispersos.
¿La cola circular siempre es mejor? Generalmente sí, porque evita el desperdicio de espacio. Sin embargo, requiere un manejo cuidadoso de los índices.
¿Puedo usar la plataforma sin conexión a internet? Algunas plataformas ofrecen versiones descargables o aplicaciones de escritorio, pero la mayoría son servicios web.
¿La plataforma admite otros lenguajes de programación? Muchas permiten elegir entre Python, Java, C++, JavaScript, etc. La visualización se adapta al lenguaje seleccionado.
Conclusión: La Visualización es tu Superpoder
La cola (queue) con tabla de secuencia es una estructura de datos esencial que todo estudiante de algoritmos debe dominar. Su implementación es sencilla pero esconde detalles importantes como la gestión de espacio y la circularidad. Gracias a una plataforma de visualización de algoritmos, puedes dejar de lado la abstracción y ver con tus propios ojos cómo funcionan los punteros, los redimensionamientos y las operaciones FIFO.
No te limites a leer teoría: interactúa, experimenta y visualiza. Busca una plataforma confiable, elige la cola con tabla de secuencia y comienza a explorar. En poco tiempo, entenderás no solo el qué, sino el cómo y el porqué de cada operación. ¡Tu viaje en el mundo de las estructuras de datos será mucho más claro y divertido!
Artículo creado para estudiantes de estructuras de datos que desean aprender de forma visual y práctica. La plataforma de visualización recomendada permite simular, depurar y comprender algoritmos en tiempo real.
树(Tree)
树是一种非线性的数据结构,它由一组按 分层顺序排列的节点组成。 其中一个节点被指定为根节点,其余的节点可以被划分为不相交的集合,这样每个集合都是根的一个子树。
树的最简单的形式是二叉树。 二叉树由一个根节点和左右子树组成,其中两个子树也是二叉树。每个节点都包含一个数据元素、一个指向左子树的左指针和一个指向右子树的右指针。根元素是由一个“根”指针指向的最顶部的节点。
二叉树 | 可视化完整可视化
1.1 ¿Qué es una estructura de datos? - Tutorial de Estructuras de Datos Visualiza tu código con animaciones
Árboles, Búsqueda Binaria, Árboles Binarios y Listas Enlazadas: Una Guía Completa para Estudiantes de Estructuras de Datos
Si estás aprendiendo estructuras de datos y algoritmos, seguramente te has encontrado con términos como árbol, búsqueda binaria, árbol binario y lista enlazada. Estos conceptos son fundamentales en la ciencia de la computación y aparecen constantemente en entrevistas técnicas y en el desarrollo de software. En este artículo, vamos a explicar cada uno de estos conceptos de manera sencilla, con ejemplos prácticos y mostrando cómo puedes visualizarlos en nuestra plataforma de aprendizaje.
¿Qué es una Lista Enlazada?
Una lista enlazada es una estructura de datos lineal donde los elementos, llamados nodos, no están almacenados en posiciones contiguas de memoria. Cada nodo contiene dos partes: el dato que queremos guardar y un puntero o referencia al siguiente nodo de la lista. Imagina que es como un tren: cada vagón (nodo) está conectado al siguiente vagón mediante un enganche (puntero).
Existen varios tipos de listas enlazadas. La más común es la lista enlazada simple, donde cada nodo apunta solo al siguiente nodo. También tenemos la lista enlazada doble, donde cada nodo tiene punteros tanto al siguiente como al anterior nodo. Y la lista circular, donde el último nodo apunta de vuelta al primero, formando un círculo.
Las listas enlazadas son muy útiles cuando necesitas insertar o eliminar elementos con frecuencia, ya que estas operaciones son mucho más rápidas que en un arreglo. Sin embargo, la desventaja es que no puedes acceder directamente a un elemento por su índice; tienes que recorrer la lista desde el principio hasta encontrar lo que buscas.
En nuestra plataforma de visualización, puedes ver exactamente cómo se conectan los nodos de una lista enlazada. Puedes agregar nodos al inicio, al final o en cualquier posición, y observar cómo se actualizan los punteros en tiempo real. Esto te ayuda a entender por qué insertar un elemento en una lista enlazada es tan eficiente.
¿Qué es un Árbol en Estructuras de Datos?
Un árbol es una estructura de datos jerárquica no lineal. A diferencia de las listas enlazadas o los arreglos, donde los elementos están en secuencia, un árbol organiza los datos en niveles. Piensa en un árbol genealógico: tienes un ancestro común (la raíz) que se ramifica en hijos, nietos, bisnietos, etc.
Los árboles tienen una terminología específica que debes conocer. La raíz es el nodo superior del árbol. Cada nodo puede tener nodos hijos. Los nodos que no tienen hijos se llaman hojas. La altura de un árbol es la distancia desde la raíz hasta la hoja más lejana. El nivel de un nodo indica qué tan profundo está en el árbol.
Los árboles se usan en muchas aplicaciones cotidianas. El sistema de archivos de tu computadora es un árbol. El DOM de una página web es un árbol. Los árboles de decisión en inteligencia artificial también son árboles. Comprender esta estructura es esencial para cualquier programador.
Con nuestra herramienta de visualización, puedes construir árboles desde cero. Agregas la raíz, luego añades hijos, y ves cómo se expande la estructura. Puedes recorrer el árbol en diferentes órdenes (preorden, inorden, postorden) y observar paso a paso qué nodos se visitan. Esto hace que conceptos abstractos como la recursividad se vuelvan tangibles.
El Árbol Binario: La Base de la Búsqueda Binaria
Un árbol binario es un tipo especial de árbol donde cada nodo puede tener como máximo dos hijos: un hijo izquierdo y un hijo derecho. No puede tener más de dos hijos. Esto lo hace muy ordenado y predecible. Los árboles binarios son la base de muchas estructuras de datos avanzadas.
Existen diferentes tipos de árboles binarios. Un árbol binario completo tiene todos los niveles llenos excepto posiblemente el último, que se llena de izquierda a derecha. Un árbol binario perfecto tiene todos los niveles completamente llenos. Un árbol binario balanceado mantiene una altura mínima para optimizar las operaciones.
El árbol binario de búsqueda (BST) es una variante crucial. En un BST, para cada nodo, todos los valores en el subárbol izquierdo son menores que el valor del nodo, y todos los valores en el subárbol derecho son mayores. Esta propiedad es la que permite realizar búsquedas binarias eficientes.
En nuestra plataforma, puedes crear un árbol binario aleatorio o ingresar tus propios valores. La herramienta te mostrará si el árbol está balanceado o no, y te permitirá realizar inserciones y eliminaciones mientras observas cómo se mantienen las propiedades del BST.
Búsqueda Binaria: El Algoritmo Eficiente
La búsqueda binaria es un algoritmo que encuentra la posición de un valor objetivo dentro de un arreglo ordenado o un árbol binario de búsqueda. Su principio es simple pero poderoso: divide el espacio de búsqueda a la mitad en cada paso.
Imagina que buscas una palabra en un diccionario. No empiezas desde la primera página; abres el diccionario por la mitad. Si la palabra está antes, buscas en la mitad izquierda. Si está después, buscas en la mitad derecha. Repites este proceso hasta encontrar la palabra. Eso es exactamente la búsqueda binaria.
La gran ventaja de la búsqueda binaria es su eficiencia. Mientras que una búsqueda lineal tendría que revisar cada elemento uno por uno (O(n) en notación Big O), la búsqueda binaria solo necesita O(log n) pasos. Esto significa que para un arreglo de un millón de elementos, la búsqueda binaria encuentra el resultado en solo unos 20 pasos, mientras que la búsqueda lineal podría necesitar un millón de pasos.
Sin embargo, la búsqueda binaria tiene un requisito fundamental: los datos deben estar ordenados. Si tienes un arreglo desordenado, primero debes ordenarlo antes de aplicar búsqueda binaria. En un árbol binario de búsqueda, esta ordenación es inherente a la estructura.
Nuestra plataforma te permite visualizar paso a paso cómo funciona la búsqueda binaria. Puedes ver cómo se reduce el espacio de búsqueda en cada iteración, cómo se compara el valor objetivo con el elemento medio, y cómo se actualizan los límites izquierdo y derecho. Esta visualización hace que el algoritmo sea mucho más fácil de entender que solo ver código.
Relación entre Árboles Binarios y Búsqueda Binaria
Los árboles binarios de búsqueda y la búsqueda binaria están intrínsecamente relacionados. De hecho, la búsqueda binaria en un arreglo ordenado se puede ver como una búsqueda en un árbol binario virtual. Cada vez que divides el arreglo por la mitad, estás examinando la raíz de un subárbol.
Cuando realizas una búsqueda binaria en un arreglo, el elemento medio actúa como la raíz. Los elementos a la izquierda forman el subárbol izquierdo, y los elementos a la derecha forman el subárbol derecho. Esta correspondencia muestra por qué ambos conceptos tienen la misma complejidad temporal de O(log n).
La principal diferencia práctica es que un árbol binario de búsqueda es dinámico: puedes insertar y eliminar elementos fácilmente sin tener que reorganizar todo el arreglo. En cambio, un arreglo ordenado requiere desplazar elementos para mantener el orden, lo que puede ser costoso.
En nuestra plataforma, puedes alternar entre la vista de arreglo y la vista de árbol para ver esta relación. Cuando realizas una búsqueda binaria en un arreglo, la herramienta puede mostrar el árbol binario equivalente que se está explorando. Esto refuerza la conexión entre ambas estructuras.
Aplicaciones Prácticas de Árboles y Búsqueda Binaria
Los árboles binarios de búsqueda y la búsqueda binaria tienen innumerables aplicaciones en el mundo real. Los sistemas de bases de datos utilizan árboles B y B+ (variantes de árboles binarios) para indexar datos y permitir búsquedas rápidas. Cada vez que haces una consulta SQL, estás utilizando estos conceptos.
Los compiladores utilizan árboles de sintaxis abstracta (AST) para analizar el código fuente. Estos árboles representan la estructura gramatical de los programas y permiten realizar análisis semánticos y generar código máquina eficiente.
Los motores de juegos utilizan árboles de partición espacial (como octrees o quadtrees) para gestionar la detección de colisiones y optimizar el renderizado. Sin estas estructuras, los juegos 3D modernos serían imposibles de ejecutar en tiempo real.
Los sistemas de recomendación utilizan árboles de decisión para clasificar usuarios y productos. Amazon, Netflix y Spotify utilizan estos algoritmos para sugerirte contenido relevante basado en tus preferencias.
Incluso los algoritmos de compresión como Huffman utilizan árboles binarios para codificar datos de manera eficiente. Cada carácter se representa como una ruta única en el árbol, permitiendo una compresión óptima.
Comparación: Listas Enlazadas vs Árboles Binarios
Es importante entender cuándo usar una lista enlazada y cuándo usar un árbol binario. Las listas enlazadas son excelentes para colecciones lineales donde necesitas inserciones y eliminaciones frecuentes, y donde el acceso secuencial es suficiente. Son simples de implementar y tienen bajo overhead de memoria por nodo.
Los árboles binarios, especialmente los BST, son superiores cuando necesitas búsquedas rápidas. Mientras que en una lista enlazada buscar un elemento requiere O(n) tiempo, en un BST balanceado solo requiere O(log n). Sin embargo, los árboles son más complejos de implementar y mantener.
Para operaciones de inserción y eliminación, las listas enlazadas tienen ventaja si ya tienes un puntero al lugar donde quieres operar. Pero si necesitas primero encontrar la posición correcta (por ejemplo, mantener una lista ordenada), entonces un BST es más eficiente en general.
En nuestra plataforma, puedes comparar directamente el rendimiento de ambas estructuras. Puedes generar los mismos datos en una lista enlazada y en un árbol binario, y luego realizar operaciones de búsqueda, inserción y eliminación. La herramienta muestra el número de pasos requeridos en cada caso, dándote una comprensión empírica de las diferencias de eficiencia.
Estrategias para Recorrer Árboles Binarios
Recorrer un árbol binario significa visitar todos sus nodos en un orden específico. Hay tres recorridos principales: preorden, inorden y postorden. Cada uno tiene aplicaciones diferentes.
En el recorrido preorden, primero visitas la raíz, luego el subárbol izquierdo, y luego el subárbol derecho. Este recorrido es útil para copiar un árbol o para evaluar expresiones en notación polaca.
En el recorrido inorden, primero visitas el subárbol izquierdo, luego la raíz, y luego el subárbol derecho. En un BST, el recorrido inorden produce los valores en orden ascendente. Esto es muy útil para ordenar datos o para verificar si un árbol es válido.
En el recorrido postorden, primero visitas el subárbol izquierdo, luego el subárbol derecho, y finalmente la raíz. Este recorrido se usa para eliminar un árbol (debes eliminar los hijos antes que el padre) o para evaluar expresiones en notación polaca inversa.
Nuestra plataforma te permite ejecutar estos recorridos paso a paso. Puedes ver exactamente en qué orden se visitan los nodos, y la herramienta resalta el nodo actual mientras avanza. También puedes ralentizar la animación para seguir cada paso con claridad.
Balanceo de Árboles Binarios
Un problema común con los árboles binarios de búsqueda es que pueden desbalancearse. Si insertas elementos en orden ascendente, el BST se convierte efectivamente en una lista enlazada, perdiendo todas las ventajas de la búsqueda binaria. La búsqueda en este caso sería O(n) en lugar de O(log n).
Para resolver esto, existen árboles balanceados como los árboles AVL y los árboles rojo-negro. Estos árboles realizan rotaciones automáticas después de cada inserción o eliminación para mantener una altura aproximadamente igual en ambos subárboles.
Un árbol AVL mantiene la propiedad de que la diferencia de altura entre los subárboles izquierdo y derecho de cualquier nodo es como máximo 1. Esto garantiza que el árbol esté siempre balanceado, aunque las operaciones de inserción y eliminación son un poco más costosas debido a las rotaciones.
Los árboles rojo-negro son más relajados: permiten una mayor diferencia de altura pero garantizan que ninguna rama sea más del doble de larga que otra. Son más eficientes en la práctica para muchas operaciones, y se utilizan en implementaciones como el TreeMap de Java o el mapa ordenado de C++.
En nuestra plataforma, puedes experimentar con árboles balanceados. Puedes insertar elementos en diferentes órdenes y observar cómo las rotaciones mantienen el árbol balanceado. La herramienta te muestra visualmente cuándo y por qué se realiza cada rotación.
Ventajas de Usar una Plataforma de Visualización
Aprender estructuras de datos y algoritmos solo con libros o videos puede ser frustrante. Los conceptos son abstractos y es difícil imaginar cómo se comportan en tiempo real. Una plataforma de visualización como la nuestra transforma la experiencia de aprendizaje.
Primero, la visualización hace tangible lo abstracto. Puedes ver físicamente cómo los punteros cambian en una lista enlazada, cómo los nodos se reorganizan en un árbol, o cómo el espacio de búsqueda se reduce en la búsqueda binaria. Esto activa tu memoria visual y facilita la comprensión.
Segundo, puedes interactuar con los algoritmos. No eres un espectador pasivo; puedes agregar tus propios datos, modificar parámetros, y ver instantáneamente cómo cambia el comportamiento. Esta retroalimentación inmediata acelera el aprendizaje.
Tercero, puedes ir a tu propio ritmo. Si un concepto no te queda claro, puedes repetir la animación tantas veces como quieras, pausarla en cualquier punto, o avanzar paso a paso. No hay presión de tiempo ni necesidad de seguir el ritmo de una clase.
Cuarto, puedes experimentar sin miedo. En nuestra plataforma, puedes probar casos extremos, como insertar elementos en orden inverso o eliminar la raíz de un árbol. Si algo sale mal, no hay consecuencias; solo reinicias y aprendes de tu error.
Cómo Usar Nuestra Plataforma de Visualización
Nuestra plataforma está diseñada para ser intuitiva y accesible para estudiantes de todos los niveles. No necesitas instalar nada; funciona directamente en tu navegador web. Aquí te explicamos cómo empezar.
Al ingresar, verás un panel de control con diferentes opciones. Puedes seleccionar la estructura de datos que quieres explorar: lista enlazada, árbol binario, o arreglo para búsqueda binaria. Cada opción abre un entorno interactivo específico.
Para las listas enlazadas, puedes hacer clic en "Agregar nodo" para insertar un nuevo elemento. Puedes especificar el valor y la posición (inicio, final, o después de un nodo específico). La herramienta dibujará la lista actualizada y mostrará los punteros entre nodos.
Para los árboles binarios, puedes insertar valores uno por uno o cargar un conjunto de datos predefinido. La herramienta construirá el árbol automáticamente y te mostrará su estructura. Puedes hacer clic en cualquier nodo para ver su valor y sus hijos.
Para la búsqueda binaria, puedes generar un arreglo ordenado aleatorio o ingresar tus propios números. Luego ingresas el valor a buscar y haces clic en "Buscar". La herramienta te mostrará paso a paso cómo se comparan los elementos.
Además, nuestra plataforma incluye ejercicios prácticos. Después de explorar cada estructura, puedes poner a prueba tus conocimientos con preguntas de opción múltiple y desafíos de código. El sistema te da retroalimentación inmediata y te sugiere áreas de mejora.
Consejos para Aprender con la Plataforma
Para aprovechar al máximo nuestra plataforma, te recomendamos seguir un enfoque estructurado. No intentes aprender todo de una vez; concéntrate en un concepto a la vez.
Empieza con listas enlazadas. Son la estructura más simple y te familiarizarán con la interfaz de la plataforma. Practica insertar y eliminar nodos hasta que entiendas cómo funcionan los punteros. Luego, intenta implementar una lista enlazada por tu cuenta y compárala con la visualización.
Después, pasa a los árboles binarios. Comienza con árboles simples de 3 o 4 nodos. Aprende a identificar la raíz, las hojas y los niveles. Practica los recorridos inorden, preorden y postorden. Verifica tus respuestas usando la herramienta de visualización.
Luego, aborda la búsqueda binaria. Primero en arreglos ordenados, luego en árboles binarios de búsqueda. Observa cómo la eficiencia depende de que los datos estén ordenados. Experimenta con arreglos de diferentes tamaños para ver cómo crece el número de pasos.
Finalmente, explora los árboles balanceados. Inserta elementos en diferentes órdenes y observa cómo las rotaciones mantienen el equilibrio. Compara el rendimiento de un BST simple versus un AVL para los mismos datos.
No olvides utilizar los ejercicios integrados. La práctica activa es mucho más efectiva que la observación pasiva. Cada ejercicio está diseñado para reforzar conceptos específicos y prepararte para entrevistas técnicas.
Errores Comunes y Cómo Evitarlos
Al aprender estas estructuras, los estudiantes suelen cometer errores similares. Conocerlos te ayudará a evitarlos y a progresar más rápido.
Un error común es confundir árboles binarios con árboles binarios de búsqueda. Recuerda: todo BST es un árbol binario, pero no todo árbol binario es un BST. La propiedad de ordenación (izquierda menor, derecha mayor) es lo que define al BST.
Otro error es pensar que la búsqueda binaria funciona en cualquier arreglo. No es así. El arreglo debe estar ordenado previamente. Si aplicas búsqueda binaria a un arreglo desordenado, obtendrás resultados incorrectos o un comportamiento impredecible.
También es común olvidar que las listas enlazadas no permiten acceso aleatorio. No puedes hacer lista[5] como en un arreglo. Para acceder al quinto elemento, debes recorrer la lista desde el principio, lo que toma O(n) tiempo.
En cuanto a los árboles, muchos estudiantes olvidan manejar el caso de árbol vacío. Siempre que implementes operaciones en árboles, asegúrate de verificar si la raíz es nula antes de intentar acceder a sus propiedades.
Finalmente, un error conceptual es pensar que un árbol balanceado es siempre perfecto. El balanceo garantiza una altura logarítmica, pero no que el árbol esté completamente lleno. Un árbol AVL puede tener huecos internos mientras mantenga la diferencia de altura máxima de 1.
Preguntas Frecuentes sobre Árboles y Búsqueda Binaria
¿Cuál es la diferencia entre un árbol binario y un árbol binario de búsqueda? Un árbol binario solo restringe el número de hijos a dos. Un BST además impone que los valores del subárbol izquierdo sean menores que la raíz y los del derecho sean mayores.
¿Por qué la búsqueda binaria es tan eficiente? Porque en cada paso descarta la mitad del espacio de búsqueda. Esto reduce exponencialmente el número de elementos a revisar, dando una complejidad logarítmica.
¿Cuándo debo usar una lista enlazada en lugar de un árbol? Usa listas enlazadas para colecciones lineales con inserciones y eliminaciones frecuentes. Usa árboles cuando necesites búsquedas rápidas o datos jerárquicos.
¿Qué es un árbol binario balanceado? Es un árbol donde la altura de los subárboles izquierdo y derecho de cada nodo difiere en como máximo 1 (AVL) o está dentro de un factor constante (rojo-negro). Esto garantiza operaciones eficientes.
¿Puedo usar búsqueda binaria en una lista enlazada? Técnicamente sí, pero no es eficiente. Necesitarías recorrer la lista para encontrar el elemento medio, lo que toma O(n) tiempo, eliminando la ventaja de la búsqueda binaria.
Recursos Adicionales y Próximos Pasos
Nuestra plataforma es solo el comienzo. Te recomendamos complementar el aprendizaje con libros clásicos como "Introduction to Algorithms" de Cormen o "Estructuras de Datos y Algoritmos" de Weiss. Estos textos profundizan en los fundamentos teóricos.
También puedes practicar en plataformas de coding como LeetCode, HackerRank o Codeforces. Busca problemas etiquetados como "binary search", "linked list" o "binary tree". Empieza con problemas fáciles y ve aumentando la dificultad gradualmente.
Implementa tus propias versiones de estas estructuras en tu lenguaje de programación favorito. No hay mejor manera de aprender que escribir el código tú mismo. Comienza con una lista enlazada simple, luego un BST, y finalmente un árbol AVL.
Participa en grupos de estudio o foros como Stack Overflow. Explicar conceptos a otros es una excelente manera de solidificar tu comprensión. Además, puedes aprender de las experiencias y errores de otros estudiantes.
Finalmente, vuelve a nuestra plataforma regularmente. A medida que avances en tu aprendizaje, descubrirás nuevos aspectos que no habías notado antes. La visualización te dará una comprensión más profunda cada vez que la uses.
Conclusión: Domina las Estructuras de Datos con Visualización
Las estructuras de datos y algoritmos son el corazón de la ciencia de la computación. Las listas enlazadas, los árboles binarios y la búsqueda binaria son conceptos fundamentales que todo programador debe dominar. No solo aparecen en entrevistas técnicas, sino que son herramientas cotidianas en el desarrollo de software.
Nuestra plataforma de visualización está diseñada para hacer que estos conceptos sean accesibles y comprensibles. Al ver los algoritmos en acción, al interactuar con las estructuras, y al recibir retroalimentación inmediata, tu aprendizaje será más rápido y más profundo.
Te invitamos a explorar nuestra plataforma hoy mismo. Comienza con listas enlazadas, experimenta con árboles binarios, y domina la búsqueda binaria. Con práctica constante y las herramientas adecuadas, estarás preparado para enfrentar cualquier desafío técnico que se te presente.
Recuerda que el aprendizaje de estructuras de datos es un viaje, no un destino. Cada concepto que domines te abrirá las puertas a nuevos conocimientos y oportunidades. Sigue practicando, sigue explorando, y sobre todo, sigue visualizando.
图(Graphs)
图是一种非线性的数据结构,它是连接这些顶点的顶点(也称为节点)和边的集合。图通常被视为树结构的泛化,其中树节点之间不是纯粹的父子关系,节点之间的任何复杂关系。在树状结构中,节点可以有任意数量的子节点,但只有一个父节点,但是在图中却没有这些限制。
图的数据结构 | 可视化完整可视化
1.1 ¿Qué es una estructura de datos? - Tutorial de Estructuras de Datos Visualiza tu código con animaciones
Estructuras de almacenamiento de grafos: Guía completa para estudiantes de algoritmos
Bienvenido al mundo de las estructuras de datos y algoritmos. Si estás aprendiendo sobre grafos, sabrás que elegir la forma correcta de almacenarlos es clave para la eficiencia de tus programas. En este artículo, exploraremos a fondo las principales estructuras de almacenamiento de grafos, sus principios, ventajas, desventajas y aplicaciones prácticas. Además, te mostraremos cómo nuestra plataforma de visualización de estructuras de datos puede ayudarte a comprender estos conceptos de manera interactiva.
¿Qué es un grafo y por qué es importante su almacenamiento?
Un grafo es una estructura compuesta por vértices (nodos) y aristas (conexiones) que relacionan pares de vértices. Los grafos modelan problemas del mundo real: redes sociales, mapas, rutas de transporte, dependencias de tareas, etc. La forma en que almacenamos un grafo en memoria influye directamente en la velocidad de operaciones como recorridos, búsqueda de caminos o detección de ciclos. Por eso, los estudiantes de algoritmos deben dominar las diferencias entre las representaciones más comunes.
Principales formas de almacenar un grafo
Existen dos enfoques clásicos: matriz de adyacencia y lista de adyacencia. También existen variantes como listas de incidencia o matrices de incidencia, pero nos centraremos en las dos primeras por ser las más usadas en cursos de estructuras de datos.
1. Matriz de adyacencia
Una matriz de adyacencia es una tabla bidimensional de tamaño n x n (donde n es el número de vértices). Cada celda [i][j] indica si existe una arista desde el vértice i al vértice j. En grafos no dirigidos, la matriz es simétrica. Para grafos ponderados, la celda almacena el peso de la arista; para grafos no ponderados, suele usarse 1 o 0.
Ventajas: Consultar si dos vértices están conectados es O(1). Es fácil de implementar y entender. Ideal para grafos densos (muchas aristas).
Desventajas: Ocupa O(n²) memoria, incluso si el grafo tiene pocas aristas. Agregar o eliminar vértices es costoso (requiere redimensionar la matriz).
Ejemplo visual: Imagina un grafo con 4 vértices. La matriz tendrá 4 filas y 4 columnas. Si el vértice 1 está conectado al 3, la celda (1,3) tendrá un 1 (o el peso).
2. Lista de adyacencia
Consiste en un arreglo de listas (o vectores) donde cada vértice tiene una lista de los vértices a los que está conectado. Para grafos ponderados, cada elemento de la lista guarda también el peso de la arista.
Ventajas: Ocupa O(n + m) memoria, donde m es el número de aristas. Es eficiente para grafos dispersos (pocas aristas). Agregar aristas es rápido. Es la representación más usada en algoritmos prácticos (BFS, DFS, Dijkstra).
Desventajas: Consultar si dos vértices son adyacentes puede ser O(grado del vértice) en el peor caso. No es tan intuitiva como la matriz para principiantes.
Ejemplo visual: Para un grafo con 4 vértices, tendremos 4 listas. La lista del vértice 1 puede contener [2, 3] si está conectado a esos vértices.
3. Otras representaciones (menos comunes)
Lista de incidencia: Cada arista se representa como un par (vértice1, vértice2). Útil cuando se necesita iterar sobre aristas con frecuencia. Matriz de incidencia: Tabla de tamaño n x m (vértices vs aristas). Se usa en teoría de grafos pero rara vez en implementaciones prácticas por su ineficiencia de memoria.
Comparativa: ¿Cuándo usar cada una?
Elegir entre matriz y lista de adyacencia depende del contexto:
- Grafos densos (casi todas las aristas posibles): matriz de adyacencia.
- Grafos dispersos (pocas aristas): lista de adyacencia.
- Algoritmos que requieren consultas frecuentes de adyacencia (ej. verificar si dos nodos están conectados): matriz.
- Recorridos o caminos mínimos (BFS, DFS, Dijkstra): lista de adyacencia por eficiencia de memoria y velocidad de iteración.
En la práctica, la lista de adyacencia es la opción más versátil y la que verás en la mayoría de implementaciones profesionales.
Aplicaciones reales de las estructuras de almacenamiento de grafos
Comprender estas estructuras te permitirá resolver problemas como:
- Redes sociales: Almacenar amistades (grafos no dirigidos) o seguidores (dirigidos). Se usan listas de adyacencia para escalar a millones de usuarios.
- Sistemas de navegación GPS: Modelar intersecciones y carreteras. Se usan listas de adyacencia con pesos (distancias).
- Planificación de proyectos: Grafos de dependencias (DAGs) para tareas. Se almacenan con listas de adyacencia.
- Motores de búsqueda: Almacenar enlaces entre páginas web (grafos dirigidos). Se usan matrices de adyacencia dispersas optimizadas.
- Análisis de circuitos: Componentes y conexiones. Se usan matrices de incidencia.
Visualización interactiva: la clave para aprender
Si eres estudiante, sabes que leer teoría no siempre es suficiente. La visualización dinámica de estructuras de datos transforma conceptos abstractos en imágenes claras. Nuestra plataforma de visualización de algoritmos te permite:
- Ver la estructura en tiempo real: Al añadir vértices y aristas, la representación gráfica se actualiza al instante. Puedes alternar entre matriz y lista de adyacencia para un mismo grafo.
- Ejecutar algoritmos paso a paso: Realiza BFS, DFS, Dijkstra o Prim mientras observas cómo cambian las estructuras internas.
- Comparar rendimiento: Simula grafos densos y dispersos para ver cómo afecta la elección de almacenamiento en el tiempo de ejecución.
- Depurar tu código: Sube tu propia implementación y la plataforma te mostrará el estado de la memoria en cada paso.
La plataforma está diseñada para que puedas interactuar directamente: haz clic para agregar nodos, arrastra para conectar aristas, asigna pesos y observa cómo se refleja en la estructura de datos subyacente.
Cómo usar la plataforma para aprender sobre almacenamiento de grafos
Sigue estos pasos para aprovechar al máximo las funcionalidades:
- Crea un grafo nuevo: Selecciona el número de vértices. La plataforma generará automáticamente una matriz de adyacencia vacía y listas de adyacencia vacías.
- Añade aristas: Haz clic en dos vértices o usa el panel de control. Verás cómo se actualizan ambas representaciones simultáneamente.
- Cambia entre vistas: Activa la vista de matriz o lista. La plataforma resalta las celdas o elementos que corresponden a cada arista.
- Ejecuta un algoritmo: Por ejemplo, BFS. Observa cómo la plataforma recorre la lista de adyacencia o consulta la matriz, dependiendo de tu elección.
- Analiza la complejidad: La plataforma muestra estadísticas en tiempo real: número de aristas, densidad, memoria usada (en bytes aproximados).
Además, la plataforma incluye ejemplos precargados (grafo de redes sociales, mapa de ciudades) para que explores sin empezar desde cero.
Beneficios de aprender con visualización
Los estudios demuestran que la visualización mejora la retención y comprensión de conceptos complejos. Al ver cómo se almacenan los datos internamente, entiendes por qué ciertos algoritmos son más rápidos. Por ejemplo, notarás que en un grafo disperso, la lista de adyacencia itera solo las aristas existentes, mientras que la matriz revisa muchas celdas vacías. Esta conciencia espacial es difícil de lograr solo con código.
Nuestra plataforma también te permite exportar e importar grafos en formato JSON, para que puedas trabajar con datos reales o compartir tus ejercicios con compañeros.
Consejos para estudiantes de algoritmos
Para dominar el almacenamiento de grafos, te recomendamos:
- Practica implementando ambas representaciones desde cero en tu lenguaje favorito (Python, Java, C++).
- Usa la plataforma para verificar que tu implementación es correcta: compara el estado de tu estructura con la visualización.
- Resuelve problemas de plataformas como LeetCode o Codeforces que involucren grafos, y analiza qué representación usaste.
- Experimenta con grafos de diferentes tamaños: 10, 100, 1000 vértices. Observa cómo crece el uso de memoria.
Recuerda que la elección de la estructura de almacenamiento puede ser la diferencia entre un algoritmo que corre en milisegundos y uno que se queda sin memoria.
Conclusión
Las estructuras de almacenamiento de grafos (matriz de adyacencia y lista de adyacencia) son fundamentales en el estudio de algoritmos. Cada una tiene sus fortalezas y debilidades, y la decisión de cuál usar depende del problema específico. La visualización interactiva acelera el aprendizaje al hacer tangible lo abstracto. Te invitamos a explorar nuestra plataforma, crear tus propios grafos y ver en acción cómo se comportan estas estructuras. ¡No hay mejor manera de aprender que experimentando!
Si eres docente, también puedes usar la plataforma en tus clases para demostrar conceptos en tiempo real. El futuro del aprendizaje de algoritmos es visual, interactivo y práctico.
❗️ 注意:
请注意,与树不同,图没有任何根节点。相反,图中的每个节点都可以与图中的每一个节点进行连接。当两个节点通过一条边连接时,这两个节点被称为相邻节点。例如,在上图中,节点A有两个邻居:B和D。