 图码
图码2.1 顺序表
💡 让我们以一个现实世界的例子来描述计算机中的数组。
想象你在一个图书馆,这个图书馆里有很多书架,每个书架上都有一排排的书。每本书都有一个特定的位置,你可以通过书架的编号和书的位置找到它。
在计算机中,数组就像这个图书馆中的书架一样。它是一个存储相同类型数据元素的数据结构。每个数据元素都有一个唯一的索引或位置,通过这个索引,你可以访问或修改特定位置的数据元素。
在计算机内存中,数组的元素是依次存储的,就像书架上的书一样。这样,计算机可以通过简单的数学运算来计算出元素的内存地址,从而快速访问数组中的任何元素。
数组是一种有效存储和访问大量相似数据的方式,就像图书馆中的书架一样可以帮助你组织和查找大量书籍。
数组是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。
数组中的元素存储在连续的内存位置中,并由一个索引(也称为下标)引用。下标是一个用于标识数组中的元素位置的序号。
2.1.1 数组的声明
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cnElemType:是我们要存放的数组元素的类型,类型可以是int, float,,double, char,或者其他可以使用的数据类型;
name:是用来表示数组的,称为数组名;
size:当前数组可以存放的最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn❗ 注意:
在本文后续中提到的所有
索引或下标 都是从 0 开始计数。
位序或第几个 都是从 1 开始计数。
在C 或者 C++ 中,数组索引从零开始。
第一个元素存储在array[0]中,第二个元素存储在array[1]中,以此类推。
因此,最后一个元素,即第6个元素,被存储在array[5]中。
在内存中,数组将如图所示进行存储。注意,方括号内写的0、1、2、3、4、5是下标。
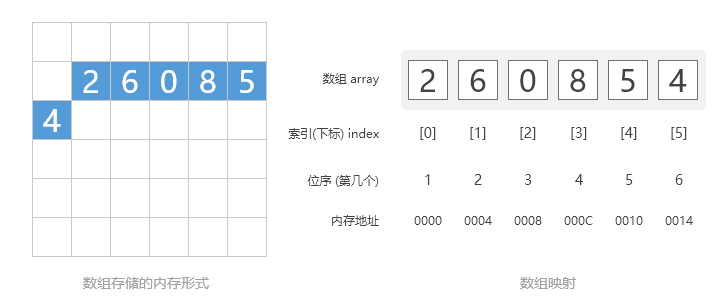
数组及内存结构
1 内存地址的计算
一个int类型的大小在内存中为4bytes。由于数组将其所有数据元素存储在连续的存储器位置中, 因此只需要知道数组首地址,即数组中第一个元素的地址就可以计算出该数组中其他元素的内存地址。
$$公式为:array[index] = base\_address + data\_type\_size \times index$$
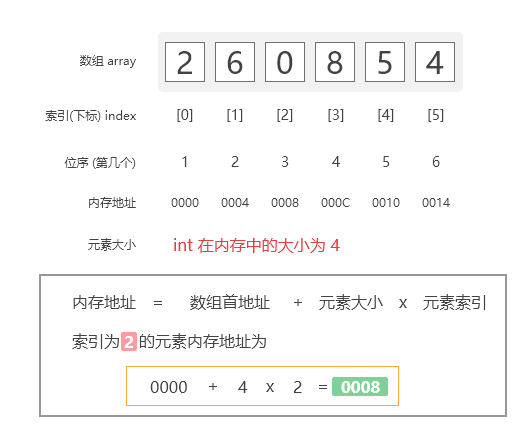
数组内存映射计算
由于数组元素是连续存储在内存的中的,所以我们可以很方便的访问任意一个元素。
就像你在图书馆的书架上查找一本特定的书时,如果你知道它的编号或位置,你可以直接走到该位置,而不必按顺序检查每本书。
在数组中访问元素是非常高效的,可以在$O(1)$时间内随机访问数组中的任意一个元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn在实际编码过程中,我们无需手动计算内存地址,因为每个元素占用大小相同的内存空间,数组元素的起始位置对于计算机也是已知的。 当我们在使用数组的下标来访问元素时,计算机可以通过上述的内存地址计算方法进行计算。
2 修改数组元素
需求:我们将index = 2即第 3 个元素的值修改为3。
操作步骤:
先找到$array[2]$的内存地址,使用上述公式:
$$\begin{split} array[2] &= base\_address + index \times data\_type\_size \\ \Rightarrow array[2] &= 0000 + 2 \times 4\\ \Rightarrow array[2] &= 0008 \end{split}$$
注意上面是计算内存地址,不是赋值
将内存地址为0xFFFF0008的值修改为3。
代码实现比较简单,计算机已自动帮助我们计算内存地址,我们只需提供对应的索引(index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn整个操作的时间复杂度为$O(1)$。
2.1.2 顺序表的介绍
💡 提示:
数组是一种数据结构,用于存储相同类型的元素的集合。
数组是一种顺序存储结构,元素在内存中按照一定的顺序依次存储。
那么数组和线性表的关系是什么呢?
线性表是一种数据结构,其中元素排列成一条线一样的顺序。
这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继。
线性表包括顺序表(数组实现)和链表等。
数组是一种实现线性表的方式之一。线性表可以通过数组来实现,也可以通过链表等其他结构来实现。
因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一。
通过数组实现的线性表称为顺序表。
1 顺序表的定义
线性表的顺序存储类型结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn定义了一个结构体SqList,包含两个成员变量:data和length。
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素。
2 顺序表的初始化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn这个函数的作用是将传入的顺序表 L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
2 在顺序表中插入元素
在顺序表中插入元素分为以下几种情况:
情况一:顺序表未满:插入在末尾
这种情况比较简单,我们只需要在当前最后一个元素的位置+1处直接赋值
例如:下面可视化窗口中的顺序表被声明为最大容量为10个元素,目前它存储了8个元素
步骤:
在末尾插入的位置为:9下标为:8 插入值5。
继续在末尾位置插入值:10
顺序表未满:插入末尾 | 可视化完整可视化
情况二:顺序表已满:不能再插入元素
上面可视化动画在插入了两个元素以后,顺序表总共有10个元素,那么我们将不能再向它添加元素,这种情况我们是不能进行插入的。
情况三:顺序表未满:插入在中间
如果想要在顺序表中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,给要插入的元素腾出位置,之后再把元素赋值给该索引。
步骤:
当前顺序表中已有8个元素,我们在下标为5位序为6处插入值10
注意代码中 i 为位序,不是下标
数组未满:插入在中间 | 可视化完整可视化
时间复杂度:
最好情况:如果插入操作发生在顺序表的末尾,并且顺序表有足够的空间,那么插入操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接在末尾添加元素不需要移动其他元素。
最坏情况:如果插入操作发生在顺序表的开头,需要将所有元素向后移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况: 平均情况下,需要移动插入位置后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
4 删除顺序表中的元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单。 我们只需要在当前存放元素的长度 -1 (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
步骤:
下面可视化面板中给出了最大容量为10的顺序表。
此时的顺序表内元素为{ 2, 6, 0, 8, 5, 4, 9, 8 },我们把下标为:3,位序为:4的元素删除掉。
❗ 注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它。
删除顺序表元素 | 可视化完整可视化
时间复杂度:
最好情况:如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素。
最差情况:如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况:平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序。
查找顺序表中的值 | 可视化完整可视化
2.1 Explication détaillée de la liste séquentielle - Tutoriel sur les listes linéaires Visualisez votre code avec des animations

Comprendre la structure de données linéaire : la liste séquentielle (tableau dynamique)
Bienvenue dans cet article dédié aux structures de données linéaires, et plus précisément à la liste séquentielle (appelée aussi tableau dynamique ou array list en anglais). Si vous apprenez les structures de données et les algorithmes, vous avez sûrement entendu parler de la liste linéaire. C'est l'une des structures les plus fondamentales en informatique. Dans cet article, nous allons explorer en détail son principe, ses caractéristiques, ses avantages et inconvénients, ainsi que ses cas d'utilisation concrets. Et nous verrons comment notre plateforme de visualisation de structures de données peut vous aider à maîtriser ce concept de manière interactive.
Qu'est-ce qu'une structure de données linéaire ?
Une structure de données linéaire organise les éléments de manière séquentielle, c'est-à-dire un à un à la suite. Chaque élément (sauf le premier et le dernier) a un prédécesseur et un successeur. La liste séquentielle est une implémentation concrète de cette structure abstraite. Elle stocke les éléments dans un bloc contigu de mémoire, ce qui permet un accès direct aux éléments via un index. Par exemple, une liste d'entiers [10, 20, 30, 40] est stockée dans des cases mémoire adjacentes. L'élément à l'index 2 est 30, et on peut y accéder instantanément.
Principe de fonctionnement de la liste séquentielle
La liste séquentielle repose sur un tableau de taille fixe ou dynamique. En réalité, la plupart des langages modernes (comme Python avec sa liste, Java avec ArrayList, C++ avec vector) utilisent un tableau dynamique. Cela signifie que la structure gère automatiquement la mémoire : quand le tableau est plein, elle alloue un nouveau tableau plus grand, copie les éléments, puis libère l'ancien. Ce mécanisme assure une flexibilité tout en conservant un accès rapide. Voici les opérations de base :
Insertion : Pour insérer un élément à une position donnée, il faut décaler tous les éléments suivants d'une case vers la droite. Dans le pire des cas (insertion au début), cela nécessite de décaler tous les éléments, soit une complexité O(n).
Suppression : Pour supprimer un élément, on décale les éléments suivants vers la gauche. Encore une fois, la suppression au début est coûteuse (O(n)).
Accès : L'accès par index est très rapide : O(1). C'est le principal avantage de la liste séquentielle.
Recherche : La recherche d'une valeur spécifique nécessite de parcourir la liste, soit O(n) dans le pire des cas (sauf si la liste est triée et qu'on utilise une recherche dichotomique, mais cela dépasse le cadre de la structure de base).
Caractéristiques et propriétés importantes
La liste séquentielle possède plusieurs propriétés clés :
Contiguïté mémoire : Les éléments sont stockés dans des emplacements mémoire adjacents. Cela améliore la localité des données et donc les performances du cache processeur.
Taille dynamique : Contrairement aux tableaux statiques, la liste séquentielle peut grandir ou rétrécir selon les besoins. Cette flexibilité est essentielle dans de nombreux algorithmes.
Complexité spatiale : Elle nécessite un espace mémoire supplémentaire pour la capacité réservée (souvent 50% de plus que le nombre d'éléments). Cela peut être un inconvénient si la mémoire est limitée.
Opérations de décalage : Les insertions et suppressions en milieu de liste sont coûteuses car elles impliquent de déplacer de nombreux éléments. C'est pourquoi on préfère utiliser d'autres structures (comme les listes chaînées) pour des opérations fréquentes au milieu.
Avantages et inconvénients de la liste séquentielle
Avantages :
- Accès aléatoire extrêmement rapide (O(1)).
- Faible surcoût mémoire par élément (pas de pointeurs supplémentaires).
- Bonne performance de cache due à la contiguïté mémoire.
- Facilité d'implémentation et de compréhension.
Inconvénients :
- Insertions et suppressions en début ou au milieu sont lentes (O(n)).
- Redimensionnement coûteux (copie de tous les éléments) quand la capacité est atteinte.
- Gaspillage mémoire potentiel (capacité inutilisée).
- Pas adaptée aux données de taille inconnue à l'avance si les opérations d'insertion/suppression sont fréquentes.
Applications courantes de la liste séquentielle
La liste séquentielle est partout. Voici quelques exemples concrets :
1. Gestion de listes d'éléments : Une liste de tâches, une liste de contacts, un historique de navigation. Dans ces cas, on accède souvent aux éléments par leur position (exemple : le troisième élément).
2. Implémentation de piles et de files : Une pile (LIFO) ou une file (FIFO) peut être facilement implémentée avec une liste séquentielle. Les opérations d'ajout et de retrait en fin de liste sont très efficaces (O(1) amorti).
3. Algorithmes de tri : Les algorithmes comme le tri rapide, le tri fusion, ou le tri par insertion utilisent souvent des listes séquentielles pour stocker et réorganiser les données.
4. Bases de données : Les index de bases de données peuvent utiliser des tableaux dynamiques pour stocker des clés ou des pointeurs.
5. Applications graphiques : Stockage de pixels, de sommets, ou de polygones dans un tableau pour un rendu rapide.
6. Systèmes embarqués : Quand la mémoire est limitée mais que l'accès rapide est crucial, la liste séquentielle est souvent privilégiée.
Pourquoi utiliser une plateforme de visualisation pour apprendre les listes séquentielles ?
Comprendre le décalage des éléments lors d'une insertion ou d'une suppression peut être abstrait. C'est là qu'intervient notre plateforme de visualisation de structures de données et algorithmes. Elle vous permet de voir littéralement comment la mémoire est organisée, comment les éléments se déplacent, et comment la capacité évolue. Voici les fonctionnalités clés :
Animation en temps réel : Chaque opération (insertion, suppression, recherche) est animée. Vous voyez les cases mémoire, les indices, et les décalages se produire sous vos yeux. Cela rend l'apprentissage intuitif.
Contrôle du pas à pas : Vous pouvez exécuter l'algorithme étape par étape, ou le mettre en pause à tout moment. Parfait pour observer les détails.
Visualisation de la mémoire : Nous affichons un schéma de la mémoire contiguë, avec les adresses (simulées) et les valeurs. Vous comprenez immédiatement pourquoi l'accès est rapide.
Comparaison avec d'autres structures : Vous pouvez basculer entre une liste séquentielle et une liste chaînée pour voir les différences de performance en termes de déplacement mémoire.
Exercices interactifs : La plateforme propose des défis : insérer un élément à une position donnée, supprimer un élément, ou rechercher une valeur. Vous devez cliquer sur les bonnes cases pour effectuer l'opération, ce qui renforce la compréhension.
Suivi de la complexité : Un compteur affiche le nombre d'opérations (décalages, comparaisons) effectuées, vous aidant à lier la théorie (O(n)) à la pratique.
Comment utiliser la plateforme pour apprendre la liste séquentielle ?
Voici un guide simple pour débuter :
Étape 1 : Rendez-vous sur la page d'accueil de notre plateforme et sélectionnez "Liste séquentielle" dans le menu des structures de données.
Étape 2 : Vous verrez une liste vide avec une capacité initiale (par exemple 5). Utilisez les boutons "Ajouter en fin", "Insérer à l'index", "Supprimer", ou "Rechercher".
Étape 3 : Observez l'animation. Par exemple, si vous insérez un élément à l'index 2, regardez comment les éléments à partir de l'index 2 se décalent vers la droite. La case libérée est ensuite remplie.
Étape 4 : Activez le mode "pas à pas" pour voir chaque étape individuellement. Notez le nombre de décalages affiché.
Étape 5 : Essayez de remplir la liste jusqu'à la capacité maximale. Vous verrez le redimensionnement : un nouveau tableau plus grand est créé, et tous les éléments sont copiés. C'est un moment clé pour comprendre le coût amorti.
Étape 6 : Utilisez le comparateur intégré pour voir comment une liste chaînée réagirait à la même opération. Vous constaterez que l'insertion au début est beaucoup plus rapide pour la liste chaînée, mais l'accès aléatoire est plus lent.
Étape 7 : Faites les exercices proposés. Par exemple : "Insérez 5 à l'index 0" ou "Supprimez l'élément à l'index 3". La plateforme valide votre action et vous donne un feedback immédiat.
Avantages de notre plateforme par rapport aux cours traditionnels
Les livres et les cours magistraux expliquent la théorie, mais la visualisation interactive comble le fossé entre l'abstrait et le concret. Voici pourquoi notre plateforme est un outil d'apprentissage puissant :
Engagement actif : Au lieu de lire passivement, vous interagissez avec la structure. La manipulation directe améliore la rétention.
Retour visuel immédiat : Vous voyez instantanément l'effet de chaque action. Si vous insérez un élément, vous voyez le décalage. Si vous dépassez la capacité, vous voyez le redimensionnement.
Adapté à tous les niveaux : Que vous soyez débutant ou avancé, vous pouvez ajuster la vitesse et vous concentrer sur les aspects qui vous intéressent.
Accessible partout : La plateforme est en ligne, sans installation. Vous pouvez apprendre sur votre ordinateur, tablette ou téléphone.
Gratuit et sans publicité : Nous croyons en l'éducation ouverte. Toutes les visualisations de base sont gratuites, sans interruption.
Exemple détaillé : simulation d'insertion au début
Prenons un exemple concret. Supposons que notre liste séquentielle contienne [A, B, C, D] avec une capacité de 5. Nous voulons insérer "X" à l'index 0 (au début). Voici ce qui se passe :
1. La liste vérifie si la capacité est suffisante (oui, il reste une case libre).
2. Tous les éléments sont décalés d'une case vers la droite : D va à l'index 4, C à l'index 3, B à l'index 2, A à l'index 1.
3. La valeur "X" est placée à l'index 0.
4. La taille de la liste passe de 4 à 5.
Sur notre plateforme, vous verrez chaque élément se déplacer progressivement. Le compteur de décalages affichera 4. Vous comprendrez immédiatement pourquoi cette opération est en O(n).
Exemple de redimensionnement automatique
Si la liste a une capacité de 4 et contient [10, 20, 30, 40], et que vous ajoutez un élément à la fin, la liste doit s'agrandir. Notre visualisation montre :
1. Création d'un nouveau tableau de capacité 8 (généralement le double).
2. Copie de chaque élément (10, 20, 30, 40) vers le nouveau tableau.
3. Ajout du nouvel élément à l'index 4.
4. L'ancien tableau est libéré (ou marqué comme supprimé).
Vous voyez le coût de cette opération : 4 copies + 1 insertion. C'est ce qu'on appelle le coût amorti.
Comparaison avec d'autres structures linéaires
Pour bien maîtriser la liste séquentielle, il est utile de la comparer avec d'autres structures :
Liste chaînée : Pas de contiguïté mémoire, insertion/suppression rapide (O(1) si on a le pointeur), mais accès lent (O(n)).
Deque (double-ended queue) : Permet des insertions/suppressions efficaces aux deux extrémités, souvent implémentée avec un tableau circulaire.
Tableau statique : Taille fixe, pas de redimensionnement, mais pas de flexibilité.
Notre plateforme permet de basculer entre ces structures pour voir les différences en action.
Conseils pour les apprenants
Voici quelques conseils pour tirer le meilleur parti de cet article et de la plateforme :
1. Pratiquez régulièrement : La théorie seule ne suffit pas. Utilisez la visualisation pour faire au moins 10 insertions et suppressions à différentes positions.
2. Notez les complexités : Après chaque opération, regardez le compteur de décalages. Essayez de prédire combien de décalages auront lieu avant de cliquer.
3. Variez les scénarios : Testez des insertions au début, au milieu, à la fin. Observez comment la performance change.
4. Explorez le redimensionnement : Ajoutez des éléments jusqu'à dépasser la capacité. Regardez le nouveau tableau se créer.
5. Combinez avec d'autres structures : Après avoir maîtrisé la liste séquentielle, étudiez la liste chaînée et le tableau circulaire sur la même plateforme.
Conclusion
La liste séquentielle est une structure de données linéaire incontournable, offrant un accès rapide aux éléments mais des insertions/suppressions potentiellement lentes. Sa compréhension est essentielle pour tout développeur ou étudiant en informatique. Grâce à notre plateforme de visualisation interactive, vous pouvez non seulement lire ces concepts, mais aussi les voir et les manipuler en temps réel. Cela rend l'apprentissage plus profond, plus rapide et plus agréable. N'attendez plus : plongez dans le monde des structures de données et maîtrisez la liste séquentielle comme jamais auparavant.
Nous espérons que cet article vous a été utile. N'hésitez pas à partager la plateforme avec d'autres apprenants et à nous faire part de vos retours. Bon apprentissage !
时间复杂度:
最好情况:要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为$O(1)$,即常数时间复杂度。
最坏情况:要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中。在这种情况下,时间复杂度为$O(n)$,其中$n$是顺序表中元素的个数。
平均情况:平均情况的时间复杂度通常是$O(\frac n 2)$,因为平均而言,我们可以认为要查找的元素在顺序表的中间位置。但是在大$O$表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是$O(n)$。
2.1.3 顺序表数组实现的优点与缺点
1 优点
随机访问速度快:由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 $O(1)$。这使得数组在需要频繁随机访问元素的情况下非常高效。
节约空间:相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间。
缓存友好:由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势。
2 缺点
固定大小:数组的大小是固定的,一旦创建后就不能动态改变。如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销。
插入和删除操作效率低:在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 $O(n)$。这使得数组在频繁插入和删除操作的场景下效率较低。
不适合存储变长数据:由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求。