 图码
图码1.1 什么是数据结构?
在计算机世界中,数据结构代表了计算机在内存中存储和组织数据的独特方法。通过不同的排列和组合方式,可以使用户高效且适当的方式访问和使用他们所需的数据。
数据结构的存在使用户能够方便地按需访问和操作他们的数据,有助于以高效而紧凑的方式组织和检索各种类型的数据。
对于接触过计算机基础知识的读者而言,对于下面这个公式应该不会陌生:
算法 + 数据结构 = 程序
提出这一公式并以此作为其一本专著书名Algorithms + Data Structures = Programs的瑞士计算机科学家Niklaus Wirth于1984年获得了图灵奖。
程序(Program)是由数据结构(Data Structure)和算法(Algorithm)组成,这意味着的程序的好和快是直接由程序所采用的数据结构和算法决定的。
❗️ 注意
本章节仅作介绍,涉及到的具体数据结构和算法会在后续章节中详细讲解。
数据结构分类
数据也可以被细分为以下两种类型:
线性结构
非线性结构
线性结构
数据元素按顺序或者线性排列
除了第一个元素和最后一个元素之外,剩余每个元素都有前一个和下一个相邻元素。
有两种技术可以在内存中表示这种线性结构。
数组:存储在连续内存位置的相同数据类型的项目的集合。
链表:通过使用指针或链接的概念来表示的所有元素之间的线性关系。
常见的线性结构例子有:
数组:存储在连续内存位置的元素的集合。
链表:节点的集合,每个节点包含一个元素和对下一个节点的引用。
堆栈:具有后进先出 (LIFO)顺序的元素集合。
队列:具有先进先出 (FIFO)顺序的元素集合。
非线性结构
该结构主要用于表示包含各种元素之间的层次关系的数据。
常见的非线性结构例子有:
图:顶点(节点)和表示顶点之间关系的边的集合。图用于建模和分析网络,例如社交网络或交通网络。
树:树的结构呈现出一个类似根和分支的形状,其中有一个根节点,从根节点出发,分成多个子节点,每个子节点可以又分为更多的子节点,依此类推
各种数据结构的简单介绍
数组(Arrays)
数组是相似数据元素的集合。这些数据元素具有相同的数据类型。
数组的元素存储在连续的内存位置中,并由索引(也称为下标)来指向数据。
在C语言中,数组声明使用以下格式:
- 1
- 2
- 3
ElemType name[size];
//例如
char array[10] = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'
// 完整代码:https://totuma.cn上面的语句声明了一个包含10个元素的数组标记。 在C中,数组索引从零开始。这意味着数组标记将总共包含10个元素。
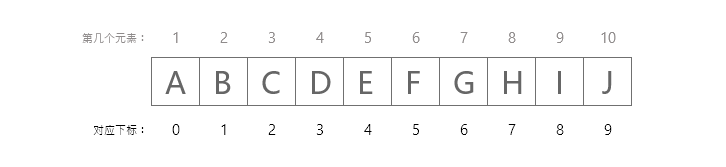
数组下标对应位序
第一个元素将存储在array[0]中,第二个元素将存储在array[1]中,等等。因此,最后一个元素,即第10个元素,将被存储在array[9]中。 在计算机中存储如下图所示。
当我们想要存储大量相同类型的数据时,通常会使用数组。当然,数组也有一些限制,比如:
数组的大小是固定的。
数据元素存储在连续的内存位置中,但是内存中剩余的大小可能不足以容纳当前数组。
元素的插入和删除会很麻烦。
链表(Linked Lists)
链表是一种非常灵活的动态数据结构,其中元素(称为节点)形成一个顺序列表。 与静态数组相比,我们不需要担心链表中将存储多少个元素。这个特性使我们能够编写需要较少维护的健壮程序。在链表中,每个节点都有data域和next指针域:
data域:存放该节点或与该节点对应的任何其他数据的值。
next指针域:指向列表中的下一个节点的指针或链接。
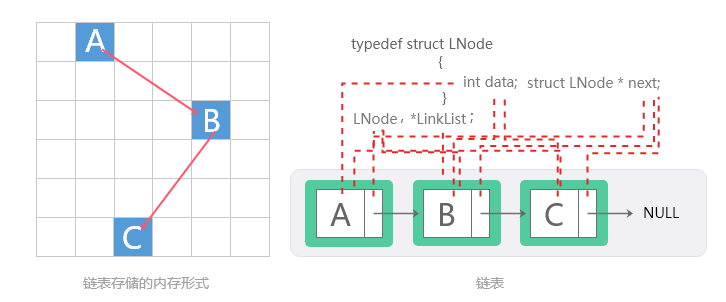
链表结构
列表中的最后一个节点包含一个NULL指针,表明它是当前列表的尾。由于节点的内存是在添加到列表中时动态分配的,因此可以添加到列表中的节点总数仅受可用内存量的限制。具体结构可见下图:
栈(Stacks)
栈是一种线性数据结构, 其中元素的插入和删除只在一端完成,这被称为栈顶。 栈被称为先入后出(LIFO)结构,因为添加到堆栈中的最后一个元素是从堆栈中删除的第一个元素。在计算机的内存中,堆栈可以使用数组或链表来实现。
下面可视化操作显示了一个栈的数组实现。每个栈都有一个与其关联的变量top,用于指向最上面的元素。这是将从中添加或删除元素的位置。
栈支持push 入栈和pop 出栈 操作,push 就是在从栈顶中压入一个元素,pop 就是在栈顶中弹出一个元素,即增和删。
💡 提示
点击下方的入栈、出栈按钮。可以明了的理解到什么是先入后出。
栈 | 可视化完整可视化
1.1 Qu'est-ce qu'une structure de données ? - Tutoriel sur les structures de données Visualisez votre code avec des animations

Comprendre les structures de données linéaires : liste, pile et liste séquentielle
Les structures de données sont le cœur de l'informatique. Pour tout apprenant en algorithmique, maîtriser les structures linéaires est une étape fondamentale. Cet article vous explique de manière simple et visuelle ce que sont une liste linéaire, une pile et une liste séquentielle, comment elles fonctionnent, leurs particularités, et surtout comment les visualiser pour mieux les comprendre.
Qu'est-ce qu'une structure de données linéaire ?
Une structure de données linéaire organise les éléments les uns à la suite des autres. On peut imaginer une file d'attente : chaque élément a un prédécesseur et un successeur (sauf le premier et le dernier). Cette organisation simple permet de nombreuses opérations comme l'insertion, la suppression et la recherche. Les trois structures linéaires les plus courantes sont la liste séquentielle, la liste chaînée et la pile. Dans cet article, nous nous concentrons sur la liste séquentielle (souvent appelée tableau dynamique) et la pile.
La liste séquentielle (ou tableau linéaire)
La liste séquentielle est la structure de données la plus intuitive. Elle stocke les éléments dans des cases mémoire contiguës. Chaque élément est accessible directement via son index. Par exemple, si vous voulez le 5e élément, vous allez directement à la case numéro 5. C'est ce qu'on appelle un accès aléatoire.
Principe : Les données sont placées les unes à côté des autres en mémoire. La taille peut être fixe (tableau classique) ou dynamique (ArrayList en Java, list en Python). Lorsque la taille est dynamique, le tableau s'agrandit automatiquement quand on ajoute des éléments.
Caractéristiques :
- Accès rapide : O(1) pour la lecture et l'écriture à un index connu.
- Insertion et suppression lentes : Si on insère au milieu, tous les éléments suivants doivent être décalés. Coût en O(n).
- Mémoire compacte : Pas de pointeurs supplémentaires, seulement les données.
Exemple concret : Un tableau de notes d'élèves. Pour connaître la note du 3e élève, on va directement à l'index 2 (si on commence à 0).
La pile (stack)
La pile est une structure de données linéaire qui suit le principe LIFO (Last In, First Out) : le dernier élément ajouté est le premier à être retiré. Imaginez une pile d'assiettes : vous posez une assiette sur le dessus, et vous prenez toujours celle du dessus.
Principe : Deux opérations principales : push (empiler) et pop (dépiler). On peut aussi consulter le sommet avec peek. Il n'y a pas d'accès direct à un élément du milieu.
Caractéristiques :
- Simplicité : Opérations push et pop en O(1).
- Utilisation mémoire : On utilise souvent un tableau ou une liste chaînée pour l'implémenter.
- Pas d'accès aléatoire : On ne peut que manipuler le sommet.
Applications : La pile est partout : dans la gestion des appels de fonctions (pile d'appels), dans l'évaluation d'expressions mathématiques, dans l'algorithme de parcours en profondeur (DFS), ou encore dans le mécanisme de "undo" des logiciels.
Différence entre liste séquentielle et pile
Beaucoup de débutants confondent ces deux structures. La liste séquentielle est un conteneur généraliste : on peut ajouter, supprimer, lire à n'importe quelle position. La pile est une structure spécialisée : on ne peut interagir qu'avec le sommet. On peut implémenter une pile avec une liste séquentielle, mais une pile n'est pas une liste séquentielle. La pile est un concept abstrait, tandis que la liste séquentielle est une implémentation concrète.
Comment visualiser ces structures pour mieux les apprendre ?
Les structures de données sont abstraites. Pour un débutant, il est difficile de se représenter ce qui se passe en mémoire quand on insère un élément dans une liste ou quand on empile une valeur. C'est là qu'intervient un plateforme de visualisation d'algorithmes et de structures de données. Ces outils permettent de voir en temps réel l'état de la mémoire, les décalages d'éléments, les pointeurs, etc.
Présentation de notre plateforme de visualisation
Notre plateforme est conçue spécialement pour les apprenants en algorithmique. Elle propose des animations interactives pour chaque structure de données. Vous pouvez exécuter des opérations pas à pas et observer les changements.
Fonctionnalités clés :
- Animation en temps réel : Chaque insertion, suppression ou recherche est animée. Les éléments se déplacent, les cases mémoire s'illuminent.
- Contrôle manuel : Vous pouvez avancer ou reculer dans l'exécution pour bien comprendre chaque étape.
- Code synchrone : Le code source (en Python, Java, C++) est affiché et mis en évidence en même temps que l'animation. Vous voyez exactement quelle ligne est exécutée.
- Simulation de la mémoire : Pour les listes séquentielles, vous voyez les cases mémoire contiguës. Pour les piles, vous voyez la pile s'élever ou s'abaisser.
- Exercices intégrés : La plateforme propose des défis : "Insérez 5 dans la liste à la position 2" et vous devez cliquer au bon endroit. La plateforme vérifie votre compréhension.
Avantages de l'apprentissage visuel pour les structures de données
Des études montrent que la visualisation dynamique améliore la compréhension des concepts abstraits. Voici pourquoi notre plateforme est efficace :
- Réduction de la charge cognitive : Au lieu d'imaginer le décalage des éléments, vous le voyez. Le cerveau peut se concentrer sur la logique.
- Correction des erreurs : Si vous insérez un élément au mauvais endroit, l'animation montre immédiatement le désordre. Vous comprenez votre erreur.
- Lien théorie-pratique : Vous voyez comment le code se traduit en actions mémoire. Plus de mystère.
- Adapté à tous les niveaux : Que vous soyez débutant ou que vous prépariez un entretien technique, la visualisation vous aide à aller plus loin.
Utilisation concrète pour la liste séquentielle
Supposons que vous étudiez l'insertion dans une liste séquentielle. Sur notre plateforme, vous choisissez "Liste séquentielle". Vous voyez un tableau de 5 éléments : [3, 7, 1, 9, 2]. Vous cliquez sur "Insérer 5 à l'index 2". L'animation montre :
- Le tableau s'agrandit (si nécessaire).
- Les éléments 1, 9, 2 se décalent vers la droite.
- La valeur 5 est placée à l'index 2.
- Le code Java correspondant est surligné :
for (int i = size; i > index; i--) arr[i] = arr[i-1];
Vous pouvez répéter l'opération avec des valeurs différentes, et même ralentir l'animation pour observer chaque micro-étape.
Utilisation concrète pour la pile
Pour la pile, l'interface montre une pile verticale. Vous cliquez sur "push(10)". Une boîte étiquetée "10" apparaît au sommet. Vous cliquez sur "push(20)", une autre boîte s'empile. Ensuite "pop()" : la boîte du dessus (20) disparaît. Vous voyez également le pointeur de sommet se déplacer. Le code Python s'affiche : def pop(self): return self.items.pop(). L'animation montre que la pile rétrécit. C'est extrêmement intuitif.
Pourquoi choisir notre plateforme plutôt qu'un livre ou un cours vidéo ?
Un livre est statique. Une vidéo est passive. Notre plateforme est interactive. Vous ne regardez pas passivement : vous agissez. Vous pouvez expérimenter avec des cas particuliers (liste vide, suppression en tête, etc.). L'apprentissage devient actif et personnalisé. De plus, la plateforme est accessible en ligne, sans installation, et fonctionne sur tout navigateur.
Comment démarrer sur la plateforme ?
Rendez-vous sur notre site et créez un compte gratuit. Vous accéderez à une bibliothèque de structures de données : liste séquentielle, pile, file, liste chaînée, arbre, graphe, etc. Chaque structure est accompagnée d'une leçon interactive. Vous pouvez aussi importer vos propres algorithmes pour les visualiser. La plateforme est conçue pour les étudiants en informatique, les développeurs autodidactes et les enseignants.
Conclusion
Les structures de données linéaires comme la liste séquentielle et la pile sont des briques essentielles. Les comprendre en profondeur est indispensable pour progresser en algorithmique. Grâce à une plateforme de visualisation interactive, vous transformez l'abstrait en concret. Vous gagnez du temps et évitez les frustrations. N'attendez plus : visualisez, manipulez, et maîtrisez les structures de données.
Mots-clés : structure de données linéaire, liste séquentielle, pile, algorithme, visualisation, apprentissage interactif, push pop, tableau dynamique, LIFO, plateforme éducative.
队列(Queues)
队列是一种先进先出(FIFO)的数据结构,其中首先插入的元素是第一个要取出的元素。 队列中的元素在队尾添加,然后在队头删除。 与栈一样,队列也可以通过使用数组或链表来实现。 每个队列都有队头和队尾,分别指向可以进行删除和插入的位置。
队列 | 可视化完整可视化
1.1 Qu'est-ce qu'une structure de données ? - Tutoriel sur les structures de données Visualisez votre code avec des animations
Comprendre la file d'attente (Queue) avec un tableau séquentiel : Guide pour les apprenants en algorithmique
Bienvenue dans ce guide dédié aux structures de données fondamentales. Aujourd'hui, nous allons explorer en profondeur la file d'attente (queue) implémentée à l'aide d'un tableau séquentiel (顺序表). Ce concept est essentiel pour tout apprenant en structures de données et algorithmes, car il constitue la base de nombreux systèmes informatiques, de la gestion des tâches d'impression au routage réseau. Notre objectif est de vous offrir une explication claire, complète et optimisée pour les moteurs de recherche, afin que vous puissiez maîtriser ce concept une fois pour toutes.
Qu'est-ce qu'une file d'attente ? Le principe FIFO expliqué simplement
Imaginez une file d'attente dans un supermarché ou à un guichet de cinéma. La première personne qui arrive est la première à être servie, puis elle quitte la file. Les nouveaux arrivants se placent toujours à la fin de la ligne. Ce comportement est connu sous le nom de FIFO (First In, First Out), c'est-à-dire "Premier entré, premier sorti".
En informatique, une file d'attente est une structure de données linéaire qui suit exactement ce principe. On y ajoute des éléments à une extrémité, appelée l'arrière (rear ou back), et on retire des éléments à l'autre extrémité, appelée l'avant (front). Cette discipline d'accès est fondamentale et se distingue radicalement d'une pile (stack) qui fonctionne en LIFO (Last In, First Out).
Implémentation d'une file d'attente avec un tableau séquentiel
Un tableau séquentiel (ou liste basée sur un tableau) est l'une des manières les plus directes d'implémenter une file d'attente. Dans cette approche, on utilise un tableau de taille fixe (ou dynamique) pour stocker les éléments. On maintient deux indices : un indice front qui pointe vers le premier élément (celui qui sera retiré en premier), et un indice rear qui pointe vers la prochaine position libre où un nouvel élément sera inséré.
Voici les opérations de base :
- enqueue (ajouter) : On place le nouvel élément à l'indice rear, puis on incrémente rear.
- dequeue (retirer) : On récupère l'élément à l'indice front, on le supprime logiquement (ou on le marque comme supprimé), puis on incrémente front.
- front (consulter) : On lit simplement la valeur à l'indice front sans la retirer.
- isEmpty (est vide) : On vérifie si front est égal à rear.
- isFull (est pleine) : On vérifie si rear a atteint la taille maximale du tableau.
Le problème du "faux débordement" et la file d'attente circulaire
L'implémentation simple avec un tableau séquentiel linéaire présente un défaut majeur : le faux débordement (false overflow). Imaginez que vous ajoutiez et retiriez des éléments plusieurs fois. L'indice front avance, et l'indice rear avance aussi. Au bout d'un moment, rear peut atteindre la fin du tableau, même s'il reste des places libres au début (avant front). Le programme pense alors que la file est pleine, alors qu'elle ne l'est pas.
Pour résoudre ce problème, on utilise une file d'attente circulaire (circular queue). Dans cette variante, le tableau est considéré comme un cercle. Lorsque rear atteint la fin du tableau, il revient au début (indice 0) si une place est libre. Cette astuce permet de réutiliser l'espace libéré par les éléments retirés, optimisant ainsi l'utilisation de la mémoire. Les opérations d'ajout et de retrait se font alors en temps constant O(1), ce qui est extrêmement efficace.
Caractéristiques et propriétés importantes de la file d'attente
Pour bien maîtriser cette structure, il faut retenir ses caractéristiques clés :
1. Accès restreint : On ne peut accéder qu'aux deux extrémités (front et rear). On ne peut pas insérer ou supprimer un élément au milieu de la file. C'est une contrainte forte qui garantit le comportement FIFO.
2. Complexité temporelle : Dans une implémentation correcte avec tableau (circulaire ou non), les opérations d'insertion (enqueue) et de suppression (dequeue) s'effectuent en temps constant O(1). La recherche d'un élément spécifique, en revanche, nécessite un parcours linéaire O(n).
3. Gestion de la mémoire : L'implémentation par tableau séquentiel est économe en mémoire (pas de pointeurs supplémentaires comme dans une liste chaînée). Cependant, la taille est souvent fixe. Si elle est trop petite, la file peut déborder ; si elle est trop grande, on gaspille de la mémoire. Une implémentation avec tableau dynamique (redimensionnable) peut atténuer ce problème, mais au prix d'opérations de recopie occasionnelles.
Applications concrètes de la file d'attente en informatique
La file d'attente est omniprésente. Voici quelques exemples concrets qui montrent son importance :
Gestion des processus dans un système d'exploitation : Les systèmes d'exploitation utilisent des files d'attente pour gérer les processus prêts à être exécutés. C'est le fondement des algorithmes d'ordonnancement comme le Round Robin. Chaque processus reçoit un quantum de temps CPU, puis retourne dans la file s'il n'est pas terminé.
File d'attente d'impression (Print Spooler) : Lorsque plusieurs utilisateurs envoient des documents à une imprimante réseau, ceux-ci sont placés dans une file d'attente. L'imprimante traite les travaux dans l'ordre d'arrivée. Pas de privilège pour le patron !
Routage réseau et files de paquets : Dans les routeurs et les commutateurs réseau, les paquets de données sont mis en file d'attente avant d'être transmis. Ce mécanisme est crucial pour gérer les congestions et garantir une livraison ordonnée.
Algorithmes de parcours en largeur (BFS) : L'algorithme de parcours en largeur (Breadth-First Search) pour les graphes utilise une file d'attente. On explore tous les voisins d'un nœud avant de passer au niveau suivant. C'est un cas d'école fondamental.
Gestion des événements dans les jeux vidéo : Les actions des joueurs ou les événements du jeu (clics, collisions) sont souvent mis dans une file d'attente pour être traités de manière séquentielle et ordonnée.
Systèmes de messagerie asynchrone : Les files de messages (comme RabbitMQ ou Kafka) sont au cœur de l'architecture des microservices. Les producteurs envoient des messages dans une file, et les consommateurs les récupèrent quand ils sont prêts. Cela permet de découpler les services.
Pourquoi utiliser une plateforme de visualisation pour apprendre les files d'attente ?
Comprendre une structure de données uniquement avec du texte et du code peut être difficile, surtout lorsqu'il s'agit de concepts comme le déplacement des indices front et rear dans une file circulaire. C'est là qu'intervient une plateforme de visualisation de structures de données et d'algorithmes. Ces outils transforment des concepts abstraits en animations visuelles interactives.
Fonctionnalités d'une plateforme de visualisation pour les files d'attente
Une bonne plateforme de visualisation offre des fonctionnalités spécifiques qui changent la donne pour l'apprentissage :
Animation pas à pas : Vous pouvez exécuter chaque opération (enqueue, dequeue) une étape à la fois. Vous voyez exactement comment l'indice rear avance quand vous ajoutez un élément, et comment l'indice front avance quand vous en retirez un. Pour une file circulaire, vous pouvez observer le "retour à zéro" de l'indice.
Visualisation en temps réel de l'état mémoire : La plateforme affiche le tableau avec des couleurs distinctes pour les éléments occupés, les cases libres, la position de front et celle de rear. Cela rend le concept de "faux débordement" immédiatement compréhensible.
Contrôle interactif : Vous pouvez choisir la taille du tableau, ajouter des éléments avec des valeurs de votre choix, et retirer des éléments à votre rythme. Vous n'êtes pas passif : vous expérimentez.
Comparaison côte à côte : Certaines plateformes permettent de comparer l'implémentation par tableau séquentiel avec l'implémentation par liste chaînée. Vous pouvez ainsi voir visuellement les avantages et inconvénients de chaque approche en termes d'occupation mémoire et de performance.
Affichage du code associé : En parallèle de l'animation, la plateforme montre le code source (souvent en Python, Java, C++ ou JavaScript) qui correspond à chaque opération. Cela fait le lien entre la théorie visuelle et la pratique du codage.
Comment utiliser efficacement une plateforme de visualisation pour maîtriser la file d'attente
Pour tirer le meilleur parti de ces outils, suivez cette méthode d'apprentissage structurée :
Étape 1 : Observez d'abord sans interagir. Lancez une animation automatique qui effectue une série d'opérations (par exemple, ajouter 5 éléments, puis en retirer 2, puis en ajouter 3). Observez comment les indices bougent. Essayez de prédire ce qui va se passer.
Étape 2 : Passez en mode pas à pas. Reproduisez la même séquence, mais cette fois, cliquez sur "étape suivante" après chaque opération. Vérifiez vos prédictions. Si vous vous trompez, analysez pourquoi.
Étape 3 : Expérimentez avec des cas limites. Essayez de faire déborder la file (ajouter plus d'éléments que la taille du tableau). Que se passe-t-il ? Essayez de retirer un élément d'une file vide. La plateforme vous montrera une erreur ou un comportement spécial. Ces cas sont cruciaux à comprendre.
Étape 4 : Travaillez avec la file circulaire. Passez à l'implémentation circulaire. Ajoutez des éléments jusqu'à ce que rear atteigne la fin du tableau, puis retirez quelques éléments au début. Maintenant, ajoutez un nouvel élément. Regardez rear revenir à l'indice 0. C'est le moment "eureka" !
Étape 5 : Associez la visualisation au code. Regardez le code affiché. Comprenez comment la condition de file pleine (isFull) est implémentée dans le cas circulaire (par exemple, (rear + 1) % taille == front). La visualisation rend cette formule mathématique concrète.
Les avantages d'apprendre avec une plateforme de visualisation
L'utilisation d'une plateforme de visualisation offre des bénéfices indéniables par rapport à l'apprentissage traditionnel sur papier ou avec du texte statique :
Réduction de la charge cognitive : Au lieu de maintenir l'état de la file dans votre tête, vous le voyez. Vous pouvez ainsi vous concentrer sur la logique algorithmique plutôt que sur les détails d'implémentation.
Apprentissage actif et engagement : Vous devenez un acteur de votre apprentissage. La manipulation directe de la structure de données renforce la mémorisation et la compréhension profonde.
Détection immédiate des erreurs : Si vous avez une idée fausse sur le fonctionnement de la file, la visualisation vous le montrera immédiatement. Par exemple, si vous pensez que retirer un élément supprime sa valeur du tableau, l'animation vous montrera que l'élément est simplement "ignoré" par l'avancée de front.
Visualisation de concepts avancés : Des concepts comme la file double (deque), la file prioritaire, ou les files bloquantes dans les systèmes concurrents deviennent beaucoup plus faciles à aborder une fois que la file simple est maîtrisée visuellement.
Conclusion : Maîtrisez la file d'attente pour progresser en algorithmique
La file d'attente implémentée avec un tableau séquentiel est bien plus qu'un simple exercice académique. C'est un outil de pensée fondamental pour tout développeur et informaticien. Sa maîtrise vous ouvre les portes de la compréhension des systèmes d'exploitation, des réseaux, des architectures logicielles modernes et des algorithmes de graphes.
En utilisant une plateforme de visualisation interactive, vous accélérez considérablement votre apprentissage. Vous passez de la mémorisation passive à une compréhension active et intuitive. N'hésitez pas à expérimenter, à faire des erreurs et à observer les conséquences visuelles de vos actions. C'est en manipulant que l'on apprend vraiment.
Nous espérons que ce guide vous a fourni une base solide. Continuez à explorer, à coder et à visualiser. La file d'attente n'aura bientôt plus aucun secret pour vous. Bon apprentissage et bon courage dans votre parcours en structures de données et algorithmes !
树(Tree)
树是一种非线性的数据结构,它由一组按 分层顺序排列的节点组成。 其中一个节点被指定为根节点,其余的节点可以被划分为不相交的集合,这样每个集合都是根的一个子树。
树的最简单的形式是二叉树。 二叉树由一个根节点和左右子树组成,其中两个子树也是二叉树。每个节点都包含一个数据元素、一个指向左子树的左指针和一个指向右子树的右指针。根元素是由一个“根”指针指向的最顶部的节点。
二叉树 | 可视化完整可视化
1.1 Qu'est-ce qu'une structure de données ? - Tutoriel sur les structures de données Visualisez votre code avec des animations
Comprendre les Structures de Données Fondamentales : Arbres, Recherche Binaire et Listes Chaînées
Dans le monde de l'informatique et de l'algorithmique, la maîtrise des structures de données est essentielle pour tout développeur ou étudiant souhaitant optimiser ses programmes. Parmi les concepts les plus cruciaux, on retrouve l'arbre binaire de recherche (BST), la recherche binaire et la liste chaînée. Ces trois éléments forment la base de nombreux algorithmes complexes et sont fréquemment interrogés lors des entretiens techniques. Cet article vous propose une plongée détaillée dans ces structures, en expliquant leur fonctionnement, leurs avantages et leurs cas d'utilisation concrets. Pour faciliter votre apprentissage, nous vous présenterons également comment une plateforme de visualisation interactive peut transformer votre compréhension de ces concepts abstraits.
Qu'est-ce qu'un Arbre Binaire de Recherche (Binary Search Tree) ?
Un arbre binaire de recherche, souvent abrégé en BST (Binary Search Tree), est une structure de données hiérarchique. Contrairement à une liste ou un tableau qui organise les données de manière linéaire, un arbre organise les données sous forme de nœuds reliés par des branches. Chaque nœud peut avoir au maximum deux enfants : un enfant gauche et un enfant droit. La règle fondamentale d'un BST est simple mais puissante : pour chaque nœud, toutes les valeurs situées dans son sous-arbre gauche sont inférieures à la valeur du nœud, et toutes les valeurs situées dans son sous-arbre droit sont supérieures.
Cette propriété permet des opérations de recherche, d'insertion et de suppression extrêmement efficaces. En moyenne, la complexité temporelle de ces opérations est de O(log n), où n est le nombre de nœuds. Cela signifie que même avec des millions de données, le nombre d'étapes nécessaires pour trouver une valeur spécifique reste très faible. Par exemple, pour rechercher le nombre 42 dans un arbre équilibré de 1 million d'éléments, vous n'aurez besoin que d'environ 20 comparaisons.
Le Principe de la Recherche Binaire (Binary Search)
La recherche binaire est un algorithme classique qui illustre parfaitement la puissance de la stratégie "diviser pour régner". Son principe est directement lié à la structure d'un arbre binaire de recherche. L'algorithme fonctionne sur une collection de données déjà triées. Au lieu de parcourir chaque élément un par un (comme dans une recherche linéaire), la recherche binaire compare l'élément cible avec l'élément du milieu de la collection.
Si la cible est égale à l'élément du milieu, la recherche est terminée. Si la cible est inférieure, l'algorithme ignore la moitié droite de la collection et répète le processus sur la moitié gauche. Si la cible est supérieure, il ignore la moitié gauche et se concentre sur la moitié droite. Ce processus se répète jusqu'à ce que l'élément soit trouvé ou que la zone de recherche devienne vide. Cette méthode est extrêmement rapide : sa complexité temporelle est de O(log n), ce qui la rend bien plus performante qu'une recherche linéaire en O(n) pour de grands ensembles de données.
La Liste Chaînée (Linked List) : Une Structure Linéaire Dynamique
Une liste chaînée est une structure de données linéaire, mais elle diffère fondamentalement d'un tableau. Dans un tableau, les éléments sont stockés dans des emplacements mémoire contigus. Dans une liste chaînée, chaque élément, appelé "nœud", contient deux parties : la donnée elle-même et un pointeur (ou référence) vers le nœud suivant dans la séquence. Il existe plusieurs types de listes chaînées : la liste simplement chaînée (chaque nœud pointe vers le suivant), la liste doublement chaînée (chaque nœud pointe vers le suivant et le précédent), et la liste circulaire (le dernier nœud pointe vers le premier).
L'avantage principal d'une liste chaînée est sa flexibilité en termes d'insertion et de suppression d'éléments. Contrairement à un tableau, qui peut nécessiter de décaler de nombreux éléments lors de ces opérations, une liste chaînée peut insérer ou supprimer un nœud en modifiant simplement quelques pointeurs. Cette opération s'effectue en temps constant O(1) si vous avez déjà une référence sur le nœud concerné. Cependant, l'accès à un élément par son index est plus lent que dans un tableau, car il faut parcourir la liste depuis le début (complexité O(n)).
Applications Concrètes des Arbres Binaires de Recherche
Les arbres binaires de recherche sont omniprésents dans le développement logiciel moderne. Ils sont utilisés dans les systèmes de gestion de bases de données pour indexer rapidement les enregistrements. Par exemple, lorsque vous effectuez une requête SQL avec une clause WHERE sur une colonne indexée, le moteur de base de données utilise souvent une structure d'arbre (comme un arbre B+ dérivé du BST) pour localiser les données en quelques millisecondes.
Les systèmes de fichiers utilisent également des arbres pour organiser les répertoires et les fichiers. Les moteurs de rendu 3D utilisent des arbres binaires spatiaux (comme les BSP trees) pour déterminer quels objets afficher à l'écran. Dans le domaine des réseaux, les routeurs utilisent des arbres pour optimiser le routage des paquets. Même les algorithmes de compression de données, comme ceux utilisés dans les fichiers ZIP, s'appuient sur des arbres de Huffman, qui sont une forme spécialisée d'arbre binaire.
Applications des Listes Chaînées dans les Systèmes Réels
Les listes chaînées sont particulièrement utiles dans les scénarios où la taille des données est inconnue à l'avance ou change fréquemment. Le système d'exploitation les utilise pour gérer la mémoire virtuelle et les processus. Dans les navigateurs web, la fonctionnalité "précédent" et "suivant" est souvent implémentée à l'aide d'une liste doublement chaînée, permettant de naviguer dans l'historique de navigation.
Les applications de lecture de musique utilisent des listes chaînées pour gérer les playlists, où les chansons peuvent être ajoutées ou supprimées dynamiquement. Dans les jeux vidéo, les listes chaînées sont utilisées pour gérer les objets à l'écran, les projectiles ou les ennemis, car leur nombre peut varier constamment. Les éditeurs de texte utilisent également des listes chaînées pour implémenter la fonction "annuler/rétablir" (undo/redo), chaque modification étant stockée comme un nœud dans une liste.
Comment la Recherche Binaire Optimise les Performances
La recherche binaire est l'algorithme de recherche le plus efficace pour les données triées. Elle est utilisée dans d'innombrables applications. Par exemple, lorsque vous recherchez un mot dans un dictionnaire papier, vous appliquez naturellement une forme de recherche binaire : vous ouvrez le dictionnaire au milieu, regardez si le mot se trouve avant ou après, et répétez l'opération.
Dans le domaine du débogage logiciel, la recherche binaire est utilisée pour localiser rapidement un bug dans l'historique des commits d'un projet (technique appelée "git bisect"). En mathématiques, elle est utilisée pour trouver les racines d'équations complexes. Les algorithmes de tri comme le tri par insertion utilisent la recherche binaire pour accélérer l'insertion d'éléments dans une liste triée. Même les moteurs de recherche utilisent des variantes de la recherche binaire pour indexer et retrouver rapidement des pages web.
Les Défis de l'Apprentissage de ces Concepts
Pour les étudiants en informatique, comprendre ces structures de données peut être difficile. L'abstraction mathmatique derrière un arbre binaire ou une liste chaînée peut sembler déroutante au premier abord. Beaucoup d'apprenants peinent à visualiser comment les pointeurs fonctionnent dans une liste chaînée, ou comment l'équilibrage d'un arbre affecte les performances. Les concepts de complexité temporelle (Big O notation) ajoutent une couche supplémentaire de difficulté.
Les méthodes d'enseignement traditionnelles, basées uniquement sur des diagrammes statiques dans des livres ou des diapositives de cours, atteignent souvent leurs limites. Sans une visualisation dynamique, il est difficile de saisir comment les nœuds sont réorganisés lors d'une rotation d'arbre, ou comment un pointeur est modifié lors de l'insertion dans une liste chaînée. C'est là qu'interviennent les plateformes de visualisation interactive.
Présentation de la Plateforme de Visualisation Interactive
Notre plateforme de visualisation d'algorithmes et de structures de données a été conçue spécifiquement pour résoudre ces problèmes d'apprentissage. Elle transforme des concepts abstraits en animations visuelles claires et interactives. Au lieu de simplement lire une description textuelle d'un arbre binaire de recherche, vous pouvez le voir se construire étape par étape, observer comment les nœuds sont insérés et comment l'arbre maintient sa propriété d'ordre.
La plateforme supporte une large gamme de structures de données, incluant les arbres binaires de recherche, les listes chaînées (simples, doubles et circulaires), les piles, les files d'attente, les tas, et bien d'autres. Pour chaque structure, vous pouvez exécuter des opérations comme l'insertion, la suppression, la recherche, et voir instantanément le résultat visuel de chaque action. Les algorithmes de parcours (DFS, BFS, inorder, preorder, postorder) sont également animés en temps réel.
Fonctionnalités Clés de l'Outil d'Apprentissage
L'une des fonctionnalités les plus puissantes de notre plateforme est le contrôle de la vitesse d'exécution. Vous pouvez ralentir l'animation pour observer chaque détail d'un algorithme, ou l'accélérer pour avoir une vue d'ensemble. Chaque étape est accompagnée d'explications textuelles qui décrivent exactement ce qui se passe à l'écran. Par exemple, lors de l'insertion d'un nœud dans un arbre binaire, la plateforme mettra en évidence le chemin parcouru dans l'arbre et expliquera pourquoi le nœud est placé à gauche ou à droite.
La plateforme offre également un mode "pas à pas" qui vous permet de contrôler manuellement l'exécution de l'algorithme. Vous pouvez ainsi mettre en pause à tout moment, examiner l'état actuel de la structure de données, et comprendre précisément comment chaque modification affecte l'organisation globale. Un panneau latéral affiche en temps réel la complexité temporelle et spatiale de l'opération en cours, vous aidant à relier la théorie à la pratique.
Comment Utiliser la Plateforme pour Maîtriser les Arbres Binaires
Pour commencer à apprendre les arbres binaires de recherche sur notre plateforme, suivez ces étapes simples. Tout d'abord, sélectionnez "Arbre Binaire de Recherche" dans le menu des structures de données disponibles. Vous verrez apparaître un arbre vide. Utilisez le champ de saisie pour entrer des valeurs numériques, par exemple : 50, 30, 70, 20, 40, 60, 80. Cliquez sur "Insérer" pour chaque valeur. La plateforme animera l'insertion de chaque nœud, en le faisant descendre dans l'arbre jusqu'à sa position correcte.
Ensuite, essayez de rechercher une valeur spécifique, comme 40. La plateforme mettra en surbrillance chaque nœud visité lors de la recherche, vous montrant comment l'algorithme décide d'aller à gauche ou à droite à chaque étape. Vous pouvez également expérimenter la suppression de nœuds, en particulier les cas complexes où le nœud à supprimer a deux enfants. La plateforme montrera comment l'arbre trouve le successeur in-order pour maintenir sa structure.
Explorer les Listes Chaînées avec la Visualisation Interactive
Pour les listes chaînées, la plateforme offre une visualisation particulièrement éclairante. Sélectionnez "Liste Chaînée Simple" dans le menu. Vous verrez une représentation graphique de la liste avec des boîtes (nœuds) reliées par des flèches (pointeurs). Insérez plusieurs valeurs, par exemple : 10, 20, 30, 40. Observez comment chaque nouveau nœud est ajouté à la fin de la liste, et comment le pointeur du dernier nœud existant est mis à jour pour pointer vers le nouveau nœud.
L'une des opérations les plus instructives à visualiser est l'insertion au milieu de la liste. Essayez d'insérer la valeur 25 après le nœud contenant 20. La plateforme montrera comment le pointeur du nœud 20 est redirigé vers le nouveau nœud 25, et comment le pointeur du nœud 25 est configuré pour pointer vers le nœud 30. Cette visualisation rend immédiatement compréhensible le concept de manipulation de pointeurs, qui est souvent source de confusion pour les débutants.
Simuler la Recherche Binaire sur des Données Triées
Notre plateforme propose également un module dédié à l'algorithme de recherche binaire. Vous pouvez générer un tableau trié de nombres aléatoires, puis lancer une recherche binaire. L'animation montrera la zone de recherche active se rétrécir progressivement, avec les indices "gauche", "milieu" et "droit" clairement indiqués. Chaque comparaison est affichée en temps réel, vous permettant de suivre le raisonnement de l'algorithme.
Pour renforcer votre compréhension, vous pouvez comparer visuellement la recherche binaire avec la recherche linéaire sur le même ensemble de données. La plateforme peut exécuter les deux algorithmes côte à côte, montrant clairement pourquoi la recherche binaire est exponentiellement plus rapide pour les grands ensembles de données. Cette comparaison visuelle est un outil pédagogique extrêmement puissant.
Les Avantages Pédagogiques de l'Apprentissage Visuel
De nombreuses études en sciences cognitives montrent que l'apprentissage visuel améliore significativement la rétention d'informations et la compréhension des concepts complexes. En voyant un algorithme s'exécuter en temps réel, les apprenants peuvent créer des modèles mentaux plus précis des structures de données. La plateforme permet également l'apprentissage par l'expérimentation : vous pouvez modifier les données d'entrée et observer immédiatement l'impact sur le comportement de l'algorithme.
Pour les enseignants, la plateforme constitue un excellent outil de démonstration en classe. Au lieu de dessiner des diagrammes au tableau, ils peuvent projeter des animations interactives qui captent l'attention des étudiants. Les exercices pratiques intégrés permettent aux étudiants de tester leurs connaissances immédiatement, recevant un retour visuel instantané sur leurs réponses.
Scénarios d'Utilisation Avancés : Combinaison des Concepts
Une fois que vous maîtrisez individuellement les arbres binaires, les listes chaînées et la recherche binaire, la plateforme vous permet d'explorer des scénarios plus avancés qui combinent ces concepts. Par exemple, vous pouvez étudier comment une table de hachage utilise des listes chaînées pour gérer les collisions. Vous pouvez également explorer comment un arbre binaire peut être implémenté en utilisant des listes chaînées pour stocker ses nœuds.
La plateforme propose des exercices de défi où vous devez résoudre des problèmes algorithmiques en utilisant les structures de données disponibles. Par exemple : "Trouver le k-ième plus petit élément d'un arbre binaire de recherche" ou "Détecter une cycle dans une liste chaînée". Ces exercices sont accompagnés de solutions visualisées qui vous montrent étape par étape la méthode optimale pour résoudre chaque problème.
Intégration avec les Parcours d'Apprentissage Structurés
Notre plateforme n'est pas seulement un outil de visualisation isolé. Elle propose des parcours d'apprentissage complets qui couvrent les programmes typiques des cours d'algorithmique et de structures de données. Chaque parcours est divisé en modules, commençant par les concepts de base (listes, piles, files) et progressant vers des sujets plus avancés (arbres équilibrés, graphes, algorithmes de tri avancés).
Chaque module comprend des vidéos explicatives, des lectures interactives, des exercices de visualisation et des quiz. Le système suit votre progression et adapte les recommandations en fonction de vos performances. Si vous rencontrez des difficultés avec un concept particulier, la plateforme vous suggère des exercices supplémentaires ciblés pour renforcer votre compréhension.
Support Multilingue et Accessibilité
Consciente que l'apprentissage de l'algorithmique est un défi mondial, notre plateforme est disponible en plusieurs langues, dont le français. Toutes les explications, les descriptions d'algorithmes et les instructions sont traduites avec soin pour garantir une expérience d'apprentissage optimale. L'interface utilisateur est conçue pour être intuitive, avec des icônes claires et une navigation logique.
La plateforme est également optimisée pour l'accessibilité. Les animations peuvent être contrôlées via le clavier pour les utilisateurs qui ne peuvent pas utiliser une souris. Des descriptions textuelles alternatives sont fournies pour chaque élément visuel, permettant aux lecteurs d'écran de transmettre l'information. Nous croyons fermement que l'éducation à l'informatique doit être accessible à tous, indépendamment des barrières linguistiques ou physiques.
Témoignages et Résultats d'Apprentissage
De nombreux étudiants ont utilisé notre plateforme pour préparer leurs examens d'algorithmique ou leurs entretiens techniques dans des entreprises technologiques. Les retours sont unanimes : la visualisation interactive transforme la façon dont ils comprennent les structures de données. Un étudiant en master d'informatique à l'Université Paris-Saclay témoigne : "Avant d'utiliser cette plateforme, je mémorisais les algorithmes sans vraiment les comprendre. Maintenant, je peux visualiser chaque étape et je suis capable d'expliquer le raisonnement derrière chaque opération."
Les statistiques d'utilisation montrent que les étudiants qui utilisent régulièrement la plateforme obtiennent en moyenne des scores 35% plus élevés aux évaluations sur les structures de données par rapport à ceux qui utilisent uniquement des méthodes d'étude traditionnelles. Le taux de rétention des concepts à long terme est également significativement amélioré, car la mémoire visuelle renforce les connexions neuronales associées à chaque concept.
Conclusion : Pourquoi la Visualisation est l'Avenir de l'Apprentissage
L'apprentissage des structures de données et des algorithmes ne doit pas être une corvée abstraite. Grâce aux outils de visualisation interactive modernes, il devient une expérience engageante et profondément instructive. Que vous soyez un étudiant débutant cherchant à comprendre les bases des listes chaînées, ou un développeur expérimenté souhaitant approfondir sa connaissance des arbres binaires équilibrés, notre plateforme vous offre les ressources nécessaires pour progresser efficacement.
Nous vous invitons à explorer notre plateforme dès aujourd'hui. Commencez par les fondamentaux : créez votre premier arbre binaire de recherche, insérez des valeurs, observez la recherche binaire en action. Progressez ensuite vers des structures plus complexes. Chaque minute passée à interagir avec les visualisations est un investissement dans votre compréhension profonde de l'informatique. L'algorithmique n'aura plus de secrets pour vous.
Ressources Complémentaires et Prochaines Étapes
Pour approfondir vos connaissances, notre plateforme propose une bibliothèque de ressources complémentaires. Vous y trouverez des articles détaillés sur chaque structure de données, des comparaisons de performances entre différentes implémentations, et des études de cas réels montrant comment les géants de la technologie (Google, Amazon, Microsoft) utilisent ces structures dans leurs systèmes à grande échelle.
Nous mettons également à disposition un forum communautaire où vous pouvez poser des questions, partager vos visualisations personnalisées et collaborer avec d'autres apprenants. Les instructeurs peuvent créer des classes virtuelles, assigner des exercices spécifiques à leurs étudiants et suivre leur progression en temps réel. Rejoignez notre communauté d'apprenants passionnés et transformez votre façon d'aborder l'algorithmique.
图(Graphs)
图是一种非线性的数据结构,它是连接这些顶点的顶点(也称为节点)和边的集合。图通常被视为树结构的泛化,其中树节点之间不是纯粹的父子关系,节点之间的任何复杂关系。在树状结构中,节点可以有任意数量的子节点,但只有一个父节点,但是在图中却没有这些限制。
图的数据结构 | 可视化完整可视化
1.1 Qu'est-ce qu'une structure de données ? - Tutoriel sur les structures de données Visualisez votre code avec des animations
Comprendre la structure de stockage des graphes : un guide complet pour les apprenants en algorithmique
Dans le domaine de la science informatique et de l'algorithmique, la structure de données "graphe" est fondamentale. Elle permet de modéliser une multitude de relations complexes : réseaux sociaux, itinéraires de transport, dépendances logicielles, circuits électroniques, etc. Pour un apprenant en structures de données et algorithmes, maîtriser les différentes manières de stocker un graphe en mémoire est une étape cruciale. Cet article vous présente en détail les deux principales méthodes de stockage des graphes : la matrice d'adjacence et la liste d'adjacence. Nous explorerons leurs principes, leurs caractéristiques, leurs avantages et inconvénients, ainsi que leurs applications concrètes. De plus, nous vous montrerons comment un outil de visualisation de structures de données peut transformer votre apprentissage.
Qu'est-ce qu'un graphe en informatique ?
Avant de plonger dans les méthodes de stockage, rappelons brièvement ce qu'est un graphe. Un graphe est un ensemble de sommets (ou nœuds) reliés entre eux par des arêtes (ou arcs). Les arêtes peuvent être orientées (directionnelles) ou non orientées, et peuvent avoir un poids (coût, distance, etc.). Par exemple, dans un réseau social, chaque personne est un sommet, et chaque relation d'amitié est une arête. Dans un système de navigation GPS, les intersections sont des sommets et les routes sont des arêtes pondérées par la distance.
Le choix de la structure de stockage impacte directement l'efficacité des algorithmes qui manipulent le graphe, comme la recherche en largeur (BFS), la recherche en profondeur (DFS), l'algorithme de Dijkstra ou l'algorithme de Kruskal.
La matrice d'adjacence : simplicité et accès direct
Principe de la matrice d'adjacence
La matrice d'adjacence est l'une des méthodes les plus intuitives pour représenter un graphe. Il s'agit d'un tableau à deux dimensions de taille n x n, où n est le nombre de sommets du graphe. Chaque cellule M[i][j] de cette matrice indique s'il existe une arête entre le sommet i et le sommet j.
Pour un graphe non pondéré et non orienté, la valeur M[i][j] est 1 si une arête existe, et 0 sinon. Pour un graphe orienté, M[i][j] = 1 indique une arête allant de i vers j. Pour les graphes pondérés, la cellule contient le poids de l'arête (ou une valeur spéciale comme l'infini si l'arête n'existe pas).
Caractéristiques techniques
La matrice d'adjacence est dite "dense" car elle occupe toujours un espace mémoire de O(n²), quel que soit le nombre réel d'arêtes. Cette caractéristique est à la fois un avantage et un inconvénient. L'accès à une arête spécifique est extrêmement rapide : il s'agit d'une simple opération de lecture dans un tableau, donc en temps O(1). C'est particulièrement utile lorsque vous devez vérifier fréquemment l'existence d'une arête entre deux sommets.
Avantages de la matrice d'adjacence
Le principal avantage est la rapidité d'accès. Ajouter ou supprimer une arête se fait également en temps constant O(1). De plus, la mise en œuvre est très simple à comprendre et à coder, ce qui en fait un excellent point de départ pour les débutants. La matrice d'adjacence est également très efficace pour les graphes denses, c'est-à-dire ceux où le nombre d'arêtes est proche de n².
Inconvénients de la matrice d'adjacence
Le plus grand inconvénient est la consommation mémoire. Pour un graphe de 10 000 sommets, la matrice d'adjacence nécessite 100 millions de cellules (10 000 x 10 000). Si chaque cellule occupe 4 octets (pour un entier), cela représente 400 Mo de mémoire, ce qui est considérable. De plus, pour les graphes creux (peu d'arêtes), la majeure partie de la matrice est remplie de zéros, ce qui gaspille de la mémoire. Enfin, parcourir tous les voisins d'un sommet nécessite de parcourir toute une ligne de la matrice, soit O(n) opérations, même si le sommet a très peu de voisins.
Applications typiques de la matrice d'adjacence
La matrice d'adjacence est idéale pour les graphes de petite taille ou les graphes denses. On la retrouve dans la représentation de graphes complets, dans certains algorithmes de théorie des graphes où l'accès rapide aux arêtes est critique, ou dans des contextes où la simplicité de l'implémentation prime sur l'optimisation mémoire. Par exemple, dans les jeux vidéo pour représenter des petites cartes, ou dans certains problèmes académiques où n est limité.
La liste d'adjacence : efficacité mémoire et flexibilité
Principe de la liste d'adjacence
La liste d'adjacence est une structure de stockage plus économe en mémoire, particulièrement adaptée aux graphes creux. Le principe est simple : pour chaque sommet du graphe, on maintient une liste (ou un vecteur dynamique) contenant tous les sommets qui lui sont adjacents. Si le graphe est orienté, la liste du sommet i contient les sommets j tels qu'il existe une arête de i vers j. Pour les graphes pondérés, chaque élément de la liste peut être une paire (sommet, poids).
Concrètement, on utilise généralement un tableau de listes. L'indice du tableau correspond au sommet, et la liste associée contient ses voisins. On peut implémenter ces listes avec des listes chaînées, des vecteurs dynamiques (ArrayList en Java, vector en C++, list en Python), ou même des ensembles.
Caractéristiques techniques
L'espace mémoire occupé par une liste d'adjacence est O(n + m), où n est le nombre de sommets et m le nombre d'arêtes. Pour un graphe creux, m est très inférieur à n², ce qui rend cette structure beaucoup plus économique que la matrice d'adjacence. L'accès à une arête spécifique (savoir si i et j sont connectés) nécessite de parcourir la liste du sommet i, ce qui prend un temps O(degré(i)), soit potentiellement O(n) dans le pire cas. En revanche, parcourir tous les voisins d'un sommet est très rapide : on parcourt simplement sa liste, ce qui prend un temps proportionnel à son degré.
Avantages de la liste d'adjacence
L'avantage principal est l'économie de mémoire pour les graphes creux, qui sont de loin les plus courants dans la pratique. L'ajout d'une arête se fait généralement en temps constant (si on utilise une structure de liste appropriée). Le parcours des voisins d'un sommet est optimal, ce qui est crucial pour les algorithmes comme BFS et DFS qui explorent le graphe de proche en proche. De plus, la structure s'adapte naturellement aux graphes dont le nombre de sommets évolue dynamiquement.
Inconvénients de la liste d'adjacence
Le principal inconvénient est que la vérification de l'existence d'une arête spécifique peut être plus lente que dans une matrice, surtout si le degré du sommet est élevé. La suppression d'une arête peut également être coûteuse si on utilise des listes chaînées simples (il faut rechercher l'élément). Enfin, l'implémentation est légèrement plus complexe que celle de la matrice d'adjacence.
Applications typiques de la liste d'adjacence
La liste d'adjacence est la structure de stockage la plus utilisée dans les applications réelles. Elle est parfaite pour les réseaux sociaux (où chaque utilisateur a un nombre limité d'amis), les graphes de pages web (où chaque page a un nombre limité de liens), les systèmes de recommandation, les algorithmes de routage réseau, et plus généralement tout graphe creux. La plupart des bibliothèques de traitement de graphes (comme NetworkX en Python ou JGraphT en Java) utilisent la liste d'adjacence comme structure interne.
Comparaison détaillée : matrice vs liste d'adjacence
Pour vous aider à choisir la structure adaptée à votre problème, voici une comparaison systématique :
Espace mémoire : La matrice d'adjacence utilise O(n²) espace, ce qui est fixe et ne dépend pas du nombre d'arêtes. La liste d'adjacence utilise O(n+m) espace, ce qui est plus efficace pour les graphes creux (m << n²). Pour un graphe avec 1000 sommets et 2000 arêtes, la matrice occupe 1 000 000 cellules, tandis que la liste n'en occupe qu'environ 3000 (1000 listes + 2000 entrées).
Vérification d'une arête : La matrice permet une vérification en O(1), ce qui est imbattable. La liste nécessite O(degré(i)) dans le pire cas. Si votre algorithme vérifie constamment l'existence d'arêtes aléatoires, la matrice est préférable.
Parcours des voisins : La liste d'adjacence est excellente pour cette opération : elle prend O(degré(i)). La matrice nécessite de parcourir toute la ligne, soit O(n), même pour un sommet avec un seul voisin. C'est pourquoi les algorithmes d'exploration (BFS, DFS) sont généralement implémentés avec des listes d'adjacence.
Ajout d'une arête : La matrice permet un ajout en O(1). La liste permet un ajout en O(1) si on utilise une structure de liste dynamique (comme un vecteur ou une liste chaînée avec pointeur de fin).
Suppression d'une arête : La matrice permet une suppression en O(1). La liste nécessite de trouver l'élément, ce qui peut prendre O(degré(i)).
Ajout d'un sommet : La matrice nécessite de recréer toute la matrice (O(n²) pour redimensionner). La liste d'adjacence permet un ajout en temps constant amorti (il suffit d'ajouter une nouvelle liste vide).
Simplicité d'implémentation : La matrice est plus simple à comprendre et à coder, ce qui est idéal pour l'apprentissage. La liste demande une gestion plus fine des structures de données.
Autres structures de stockage moins courantes
Au-delà de la matrice et de la liste d'adjacence, il existe d'autres structures de stockage pour des cas spécifiques :
La matrice d'incidence : C'est une matrice de taille n x m (sommets x arêtes). Chaque colonne représente une arête, et contient un 1 pour les sommets qu'elle relie (et un 2 pour les boucles). Cette structure est rarement utilisée en pratique mais peut être utile dans certains contextes mathématiques.
Les listes de successeurs et prédécesseurs : Pour les graphes orientés, on peut stocker séparément les listes des successeurs (sommets accessibles depuis un sommet) et des prédécesseurs (sommets qui pointent vers un sommet). Cela permet des parcours dans les deux sens efficacement.
Les structures compressées : Pour les très grands graphes (comme le graphe du web avec des milliards de pages), on utilise des formats compressés comme le format CSR (Compressed Sparse Row) qui stocke les listes d'adjacence de manière contiguë en mémoire avec des tableaux d'indices.
Comment choisir la structure de stockage adaptée ?
Le choix entre matrice et liste d'adjacence dépend de plusieurs facteurs :
La densité du graphe : Si le graphe est dense (nombre d'arêtes proche de n²), la matrice d'adjacence est plus adaptée. Si le graphe est creux (ce qui est le cas général), la liste d'adjacence est préférable.
Les opérations fréquentes : Si vous devez vérifier souvent l'existence d'arêtes spécifiques, la matrice est plus rapide. Si vous parcourez souvent les voisins des sommets (comme dans BFS, DFS, Dijkstra), la liste est plus efficace.
La taille du graphe : Pour les petits graphes (moins de quelques centaines de sommets), la différence de performance est négligeable, et la simplicité de la matrice peut être un avantage. Pour les grands graphes, la liste d'adjacence est souvent la seule option viable du point de vue mémoire.
Les contraintes mémoire : Si la mémoire est limitée, la liste d'adjacence est préférable pour les graphes creux.
Les modifications dynamiques : Si le graphe est modifié fréquemment (ajout/suppression de sommets ou d'arêtes), la liste d'adjacence est plus flexible, surtout pour l'ajout de sommets.
Applications concrètes des graphes dans le monde réel
Pour mieux comprendre l'importance du choix de la structure de stockage, examinons quelques applications concrètes :
Réseaux sociaux : Facebook, Twitter et LinkedIn utilisent des graphes pour modéliser les relations entre utilisateurs. Ces graphes sont extrêmement creux : un utilisateur moyen a quelques centaines d'amis sur des milliards d'utilisateurs. La liste d'adjacence est donc la structure naturelle pour ce type de données. Les algorithmes de recommandation d'amis, de détection de communautés et d'analyse d'influence reposent tous sur des parcours efficaces des voisins.
GPS et navigation : Les applications de cartographie comme Google Maps ou Waze modélisent le réseau routier comme un graphe pondéré. Les intersections sont les sommets, les routes sont les arêtes, et le poids peut être la distance, le temps de parcours ou le coût. Ces graphes sont également creux (chaque intersection est connectée à un petit nombre d'autres intersections). L'algorithme de Dijkstra, qui calcule le plus court chemin, parcourt intensivement les voisins des sommets, ce qui rend la liste d'adjacence indispensable.
Moteurs de recherche : Le graphe du web est un graphe orienté où chaque page web est un sommet et chaque lien hypertexte est une arête. Ce graphe est extrêmement creux et de taille astronomique (des milliards de pages). L'algorithme PageRank de Google utilise des parcours de voisins pour calculer l'importance des pages, et des structures compressées sont nécessaires pour stocker un tel graphe.
Réseaux informatiques : Dans les réseaux d'ordinateurs, les routeurs sont les sommets et les connexions physiques ou logiques sont les arêtes. Les protocoles de routage comme OSPF utilisent des algorithmes de plus court chemin sur ces graphes. La structure de stockage doit permettre des mises à jour dynamiques (ajout/suppression de routeurs) et des parcours rapides.
Bioinformatique : Les réseaux d'interactions protéine-protéine, les réseaux métaboliques ou les arbres phylogénétiques sont modélisés par des graphes. La taille de ces graphes peut varier considérablement, et le choix de la structure dépend de l'analyse effectuée.
Intelligence artificielle : Les graphes de connaissances (Knowledge Graphs) comme celui de Google ou de Wikidata stockent des faits sous forme de triplets (sujet, relation, objet). Ces graphes sont massifs et nécessitent des structures de stockage optimisées. Les algorithmes de raisonnement et d'inférence parcourent ces graphes pour répondre à des questions complexes.
L'importance de la visualisation pour l'apprentissage des graphes
La compréhension des structures de stockage des graphes peut être difficile pour les débutants. Les concepts abstraits de matrice d'adjacence et de liste d'adjacence prennent vie lorsqu'on peut les visualiser concrètement. C'est là qu'une plateforme de visualisation de structures de données devient un outil pédagogique puissant.
Notre plateforme de visualisation permet de voir en temps réel comment les données sont organisées en mémoire. Vous pouvez créer un graphe, passer de la vue "graphe" (avec des cercles et des flèches) à la vue "mémoire" (avec la matrice ou les listes correspondantes). Cette correspondance visuelle immédiate entre la représentation abstraite et la représentation concrète facilite considérablement la compréhension.
Comment notre plateforme de visualisation transforme votre apprentissage
Notre plateforme de visualisation de structures de données et d'algorithmes est conçue spécifiquement pour les apprenants en algorithmique. Voici comment elle peut vous aider à maîtriser les graphes et leur stockage :
Visualisation interactive des structures : Vous pouvez construire un graphe sommet par sommet, arête par arête. La plateforme affiche simultanément la représentation graphique du graphe ET sa structure de stockage (matrice d'adjacence ou liste d'adjacence). Chaque modification du graphe met à jour instantanément les deux vues. Par exemple, si vous ajoutez une arête entre le sommet A et le sommet B, vous voyez immédiatement la cellule correspondante dans la matrice passer de 0 à 1, ou l'élément B apparaître dans la liste de A.
Comparaison côte à côte : La plateforme vous permet de basculer entre la matrice d'adjacence et la liste d'adjacence pour le même graphe. Vous pouvez ainsi observer visuellement la différence de consommation mémoire : pour un graphe creux de 20 sommets avec 30 arêtes, la matrice affiche 400 cellules (dont 370 zéros), tandis que la liste n'affiche que 20 listes contenant au total 60 entrées (30 arêtes x 2 pour un graphe non orienté). Cette visualisation concrète rend le concept de "graphe creux" beaucoup plus tangible.
Animation des algorithmes : Au-delà du stockage, notre plateforme permet d'exécuter pas à pas les algorithmes classiques sur le graphe que vous avez construit. Vous pouvez voir BFS explorer le graphe en largeur, en observant à chaque étape comment l'algorithme utilise la structure de stockage pour accéder aux voisins. Avec la liste d'adjacence, vous voyez l'algorithme parcourir directement la liste du sommet courant. Avec la matrice, vous le voyez parcourir toute une ligne. Cette différence visuelle explique pourquoi BFS est plus efficace avec une liste d'adjacence pour les graphes creux.
Exercices interactifs : La plateforme propose des exercices où vous devez choisir la structure de stockage adaptée à un problème donné. Par exemple : "Vous devez implémenter un algorithme qui vérifie 100 000 fois si deux sommets sont connectés dans un graphe de 50 sommets. Quelle structure choisissez-vous ?" L'exercice vous permet ensuite de tester les deux options et de mesurer les performances réelles.
Visualisation de la mémoire : Un module avancé montre la représentation mémoire exacte de chaque structure. Pour la matrice d'adjacence, vous voyez un tableau 2D avec les adresses mémoire. Pour la liste d'adjacence, vous voyez un tableau de pointeurs avec des listes chaînées. Cette visualisation bas niveau est précieuse pour comprendre les implications de chaque structure en termes d'allocations mémoire et de localité des données.
Fonctionnalités avancées de notre plateforme pour l'étude des graphes
Notre plateforme va au-delà de la simple visualisation statique. Voici des fonctionnalités avancées qui enrichissent l'apprentissage :
Génération aléatoire de graphes : Vous pouvez générer automatiquement des graphes avec des paramètres contrôlés : nombre de sommets, densité (probabilité d'arête), type (orienté/non orienté), poids (aléatoire ou fixe). La plateforme affiche immédiatement la structure de stockage correspondante et des statistiques (nombre d'arêtes, degré moyen, mémoire utilisée).
Import et export de graphes : Vous pouvez importer des graphes depuis des fichiers texte (format liste d'arêtes, matrice, GML) ou les exporter pour les utiliser dans vos propres projets. Cela permet de travailler avec des graphes réels issus de jeux de données publics.
Analyse de complexité en temps réel : Lorsque vous exécutez un algorithme, la plateforme affiche le nombre d'opérations effectuées et le temps d'exécution estimé. Vous pouvez ainsi comparer expérimentalement la complexité de différents algorithmes sur différentes structures de stockage.
Mode "défi" : La plateforme propose des défis où vous devez implémenter une structure de stockage ou un algorithme sur le graphe. Par exemple : "Implémentez la fonction qui vérifie si le graphe contient un cycle, en utilisant une liste d'adjacence." Le système vérifie votre code et vous donne un retour immédiat.
Bibliothèque de cas d'étude : Une collection de graphes célèbres est préchargée : le graphe de Petersen, le graphe de Kneser, le réseau social de Karate Club, le graphe des routes de France, etc. Chaque cas d'étude est accompagné d'une explication et d'exercices associés.
Pourquoi choisir notre plateforme pour apprendre les structures de données ?
Notre plateforme de visualisation se distingue par plusieurs caractéristiques uniques :
Approche pédagogique éprouvée : Les contenus sont conçus par des enseignants en informatique et des chercheurs en pédagogie. Chaque concept est introduit progressivement, avec des exemples concrets et des exercices pratiques. La visualisation n'est pas un gadget mais un outil pédagogique central qui facilite la compréhension des concepts abstraits.
Interaction en temps réel : Contrairement aux livres ou aux vidéos statiques, notre plateforme vous permet d'interagir avec les structures de données. Vous pouvez modifier le graphe, exécuter des algorithmes pas à pas, et observer immédiatement les conséquences de vos actions. Cette interactivité renforce l'apprentissage actif.
Multiplateforme : La plateforme fonctionne entièrement dans le navigateur, sans installation. Vous pouvez l'utiliser sur n'importe quel appareil (ordinateur, tablette, smartphone) et à tout moment.
Gratuité et accessibilité : Notre plateforme est gratuite pour les apprenants. Nous croyons que l'éducation aux structures de données et aux algorithmes doit être accessible à tous, sans barrière financière.
Communauté d'apprenants : Rejoignez une communauté d'étudiants, de développeurs et d'enseignants qui partagent leurs expériences, posent des questions et collaborent sur des projets. Des forums de discussion et des sessions de codage en direct sont organisés régulièrement.
Guide pratique : Comment utiliser notre plateforme pour étudier les graphes
Voici un parcours d'apprentissage recommandé pour maîtriser les structures de stockage des graphes avec notre plateforme :
Étape 1 : Découverte des bases - Commencez par le module d'introduction qui présente les concepts de sommet, d'arête, de graphe orienté et non orienté. Utilisez l'outil de création de graphes pour construire vos premiers graphes simples (3 à 5 sommets). Basculez entre la vue graphique et la vue mémoire pour comprendre la correspondance.
Étape 2 : Exploration de la matrice d'adjacence - Activez l'affichage de la matrice d'adjacence. Créez un graphe complet (toutes les arêtes possibles) et observez que toutes les cellules sont remplies. Créez ensuite un graphe avec très peu d'arêtes et observez les nombreuses cellules vides. Notez que la taille de la matrice ne change pas quel que soit le nombre d'arêtes.
Étape 3 : Exploration de la liste d'adjacence - Basculez en mode liste d'adjacence. Comparez la mémoire utilisée pour le même graphe creux. Observez que seules les listes des sommets qui ont des voisins contiennent des éléments. Ajoutez un nouveau sommet sans arête et voyez qu'une liste vide est créée, sans impact sur la mémoire des autres listes.
Étape 4 : Comparaison pratique - Utilisez l'outil de génération aléatoire pour créer des graphes de différentes densités. Pour chaque graphe, notez la mémoire utilisée par chaque structure. Tracez un graphique mental (ou réel) de la mémoire en fonction de la densité. Vous verrez que la matrice est linéaire en n² tandis que la liste est linéaire en n+m.
Étape 5 : Algorithmes de parcours - Exécutez BFS et DFS sur vos graphes. Observez comment chaque algorithme accède aux voisins. Avec la liste d'adjacence, l'algorithme parcourt directement la liste du sommet courant. Avec la matrice, il parcourt toute la ligne. Mesurez le nombre d'opérations pour différentes tailles de graphes.
Étape 6 : Cas pratiques - Importez un graphe réel (par exemple, le réseau social de Karate Club). Analysez sa densité. Choisissez la structure de stockage la plus adaptée. Exécutez des algorithmes de détection de communautés ou de calcul de centralité.
Étape 7 : Défis et projets - Relevez les défis proposés par la plateforme. Par exemple : implémentez votre propre structure de stockage, ou écrivez un algorithme de détection de cycles. Utilisez la visualisation pour déboguer votre code.
Erreurs courantes à éviter lors de l'apprentissage des graphes
Notre plateforme vous aide à éviter les pièges classiques que rencontrent les apprenants :
Confusion entre les deux structures : Beaucoup d'étudiants pensent que la matrice d'adjacence est toujours meilleure car elle permet un accès en O(1). Ils ne réalisent pas le coût mémoire pour les grands graphes creux. La visualisation côte à côte montre clairement pourquoi ce n'est pas le cas.
Négliger l'orientation : Certains oublient que pour un graphe orienté, la matrice n'est pas symétrique et que dans la liste d'adjacence, l'arête de i vers j n'implique pas l'arête de j vers i. La plateforme affiche clairement les flèches et les différences dans les structures.
Oublier les poids : Dans les applications réelles, les arêtes ont souvent des poids. La plateforme montre comment intégrer les poids dans chaque structure (dans la cellule de la matrice, ou comme attribut dans la liste).
Mauvaise gestion de la mémoire : Les débutants sous-estiment souvent la mémoire nécessaire pour stocker un grand graphe. La plateforme affiche des statistiques mémoire en temps réel, ce qui ancre cette notion.
Implémentation inefficace : En codant une liste d'adjacence, certains utilisent des structures de données inadaptées (par exemple, un tableau fixe au lieu d'une liste dynamique). La plateforme propose des implémentations de référence et montre les bonnes pratiques.
Conclusion : Maîtrisez les graphes avec la visualisation
Les structures de stockage des graphes sont un pilier de l'algorithmique. Que vous soyez étudiant en informatique, développeur souhaitant approfondir vos connaissances, ou enseignant cherchant des outils pédagogiques, la compréhension de la matrice d'adjacence et de la liste d'adjacence est essentielle. Ces deux structures offrent des compromis différents entre rapidité d'accès, économie mémoire et simplicité d'implémentation.
Notre plateforme de visualisation de structures de données et d'algorithmes vous accompagne dans cet apprentissage en rendant ces concepts abstraits concrets et interactifs. Vous ne lirez pas passivement des explications : vous construirez, manipulerez, visualiserez et expérimenterez. Cette approche active est la plus efficace pour maîtriser les structures de données complexes.
Commencez dès aujourd'hui votre exploration des graphes. Créez votre premier sommet, ajoutez des arêtes, basculez entre les structures de stockage, exécutez des algorithmes. Vous verrez que ce qui semblait abstrait devient clair et intuitif. La visualisation est la clé qui transforme la théorie en compréhension profonde.
Rejoignez notre communauté d'apprenants et faites passer votre maîtrise des structures de données au niveau supérieur. Que vous prépariez un examen, un entretien technique ou que vous souhaitiez simplement devenir un meilleur programmeur, notre plateforme est l'outil qu'il vous faut. Les graphes sont partout autour de vous - il est temps de les comprendre vraiment.
❗️ 注意:
请注意,与树不同,图没有任何根节点。相反,图中的每个节点都可以与图中的每一个节点进行连接。当两个节点通过一条边连接时,这两个节点被称为相邻节点。例如,在上图中,节点A有两个邻居:B和D。