 图码
图码2.1 顺序表
💡 让我们以一个现实世界的例子来描述计算机中的数组。
想象你在一个图书馆,这个图书馆里有很多书架,每个书架上都有一排排的书。每本书都有一个特定的位置,你可以通过书架的编号和书的位置找到它。
在计算机中,数组就像这个图书馆中的书架一样。它是一个存储相同类型数据元素的数据结构。每个数据元素都有一个唯一的索引或位置,通过这个索引,你可以访问或修改特定位置的数据元素。
在计算机内存中,数组的元素是依次存储的,就像书架上的书一样。这样,计算机可以通过简单的数学运算来计算出元素的内存地址,从而快速访问数组中的任何元素。
数组是一种有效存储和访问大量相似数据的方式,就像图书馆中的书架一样可以帮助你组织和查找大量书籍。
数组是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。
数组中的元素存储在连续的内存位置中,并由一个索引(也称为下标)引用。下标是一个用于标识数组中的元素位置的序号。
2.1.1 数组的声明
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cnElemType:是我们要存放的数组元素的类型,类型可以是int, float,,double, char,或者其他可以使用的数据类型;
name:是用来表示数组的,称为数组名;
size:当前数组可以存放的最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn❗ 注意:
在本文后续中提到的所有
索引或下标 都是从 0 开始计数。
位序或第几个 都是从 1 开始计数。
在C 或者 C++ 中,数组索引从零开始。
第一个元素存储在array[0]中,第二个元素存储在array[1]中,以此类推。
因此,最后一个元素,即第6个元素,被存储在array[5]中。
在内存中,数组将如图所示进行存储。注意,方括号内写的0、1、2、3、4、5是下标。
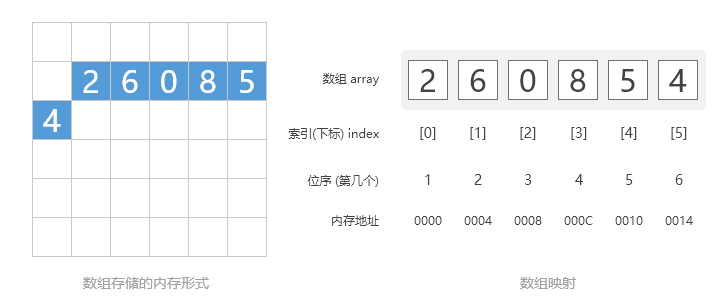
数组及内存结构
1 内存地址的计算
一个int类型的大小在内存中为4bytes。由于数组将其所有数据元素存储在连续的存储器位置中, 因此只需要知道数组首地址,即数组中第一个元素的地址就可以计算出该数组中其他元素的内存地址。
$$公式为:array[index] = base\_address + data\_type\_size \times index$$
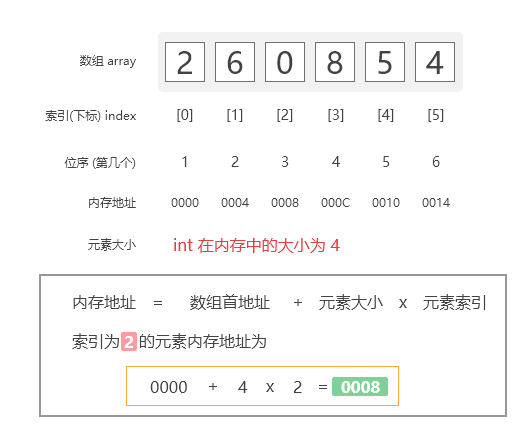
数组内存映射计算
由于数组元素是连续存储在内存的中的,所以我们可以很方便的访问任意一个元素。
就像你在图书馆的书架上查找一本特定的书时,如果你知道它的编号或位置,你可以直接走到该位置,而不必按顺序检查每本书。
在数组中访问元素是非常高效的,可以在$O(1)$时间内随机访问数组中的任意一个元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn在实际编码过程中,我们无需手动计算内存地址,因为每个元素占用大小相同的内存空间,数组元素的起始位置对于计算机也是已知的。 当我们在使用数组的下标来访问元素时,计算机可以通过上述的内存地址计算方法进行计算。
2 修改数组元素
需求:我们将index = 2即第 3 个元素的值修改为3。
操作步骤:
先找到$array[2]$的内存地址,使用上述公式:
$$\begin{split} array[2] &= base\_address + index \times data\_type\_size \\ \Rightarrow array[2] &= 0000 + 2 \times 4\\ \Rightarrow array[2] &= 0008 \end{split}$$
注意上面是计算内存地址,不是赋值
将内存地址为0xFFFF0008的值修改为3。
代码实现比较简单,计算机已自动帮助我们计算内存地址,我们只需提供对应的索引(index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn整个操作的时间复杂度为$O(1)$。
2.1.2 顺序表的介绍
💡 提示:
数组是一种数据结构,用于存储相同类型的元素的集合。
数组是一种顺序存储结构,元素在内存中按照一定的顺序依次存储。
那么数组和线性表的关系是什么呢?
线性表是一种数据结构,其中元素排列成一条线一样的顺序。
这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继。
线性表包括顺序表(数组实现)和链表等。
数组是一种实现线性表的方式之一。线性表可以通过数组来实现,也可以通过链表等其他结构来实现。
因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一。
通过数组实现的线性表称为顺序表。
1 顺序表的定义
线性表的顺序存储类型结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn定义了一个结构体SqList,包含两个成员变量:data和length。
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素。
2 顺序表的初始化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn这个函数的作用是将传入的顺序表 L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
2 在顺序表中插入元素
在顺序表中插入元素分为以下几种情况:
情况一:顺序表未满:插入在末尾
这种情况比较简单,我们只需要在当前最后一个元素的位置+1处直接赋值
例如:下面可视化窗口中的顺序表被声明为最大容量为10个元素,目前它存储了8个元素
步骤:
在末尾插入的位置为:9下标为:8 插入值5。
继续在末尾位置插入值:10
顺序表未满:插入末尾 | 可视化完整可视化
情况二:顺序表已满:不能再插入元素
上面可视化动画在插入了两个元素以后,顺序表总共有10个元素,那么我们将不能再向它添加元素,这种情况我们是不能进行插入的。
情况三:顺序表未满:插入在中间
如果想要在顺序表中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,给要插入的元素腾出位置,之后再把元素赋值给该索引。
步骤:
当前顺序表中已有8个元素,我们在下标为5位序为6处插入值10
注意代码中 i 为位序,不是下标
数组未满:插入在中间 | 可视化完整可视化
时间复杂度:
最好情况:如果插入操作发生在顺序表的末尾,并且顺序表有足够的空间,那么插入操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接在末尾添加元素不需要移动其他元素。
最坏情况:如果插入操作发生在顺序表的开头,需要将所有元素向后移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况: 平均情况下,需要移动插入位置后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
4 删除顺序表中的元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单。 我们只需要在当前存放元素的长度 -1 (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
步骤:
下面可视化面板中给出了最大容量为10的顺序表。
此时的顺序表内元素为{ 2, 6, 0, 8, 5, 4, 9, 8 },我们把下标为:3,位序为:4的元素删除掉。
❗ 注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它。
删除顺序表元素 | 可视化完整可视化
时间复杂度:
最好情况:如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素。
最差情况:如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况:平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序。
查找顺序表中的值 | 可视化完整可视化
2.1 Explicação detalhada da Lista Sequencial - Tutorial de Lista Linear Visualize seu código com animações

O que é uma Tabela Linear? Entendendo a Estrutura de Dados Fundamental
Uma tabela linear é uma das estruturas de dados mais básicas e essenciais no estudo de algoritmos e estruturas de dados. Em termos simples, uma tabela linear é uma sequência ordenada de elementos do mesmo tipo, onde cada elemento, exceto o primeiro e o último, possui um predecessor e um sucessor imediato. Esta estrutura é fundamental para qualquer estudante de ciência da computação, pois serve como base para estruturas mais complexas como pilhas, filas e listas encadeadas.
A principal característica de uma tabela linear é que os elementos estão organizados em uma ordem específica, e o acesso a esses elementos pode ser feito através de índices. Por exemplo, em uma tabela linear com 5 elementos, o primeiro elemento está na posição 0, o segundo na posição 1, e assim sucessivamente. Esta organização sequencial torna a tabela linear uma estrutura intuitiva e fácil de entender para iniciantes.
O que é uma Lista Sequencial? A Implementação Mais Simples de Tabela Linear
A lista sequencial, também conhecida como vetor ou array dinâmico, é a implementação mais direta de uma tabela linear. Nesta implementação, os elementos são armazenados em posições consecutivas de memória. Isso significa que, se você sabe onde está o primeiro elemento, pode calcular facilmente onde está qualquer outro elemento somando o deslocamento adequado.
Por exemplo, se cada elemento ocupa 4 bytes na memória e o primeiro elemento está no endereço 1000, o quinto elemento estará no endereço 1000 + (4 * 4) = 1016. Esta característica torna o acesso aleatório extremamente rápido, pois podemos acessar qualquer elemento diretamente pelo seu índice sem precisar percorrer a lista.
Princípios Fundamentais da Lista Sequencial
Para compreender completamente a lista sequencial, é importante entender seus princípios operacionais básicos. Primeiramente, a lista sequencial utiliza um bloco contíguo de memória para armazenar todos os seus elementos. Isso significa que o tamanho máximo da lista é definido no momento da criação, embora algumas implementações permitam redimensionamento dinâmico.
As operações básicas em uma lista sequencial incluem: inserção de elementos, remoção de elementos, busca por valor, acesso por índice e atualização de elementos. Cada uma dessas operações tem características de desempenho específicas que afetam a escolha desta estrutura para diferentes aplicações.
Características de Desempenho da Lista Sequencial
O desempenho é um aspecto crucial ao escolher uma estrutura de dados. Na lista sequencial, o acesso a um elemento pelo seu índice tem complexidade O(1), ou seja, constante. Isso significa que não importa se a lista tem 10 ou 10.000 elementos, o tempo para acessar um elemento específico é praticamente o mesmo.
No entanto, as operações de inserção e remoção têm complexidade O(n) no pior caso. Isso ocorre porque, ao inserir ou remover um elemento no meio da lista, todos os elementos subsequentes precisam ser deslocados para manter a ordem sequencial. Por exemplo, se você inserir um elemento na primeira posição de uma lista com 1000 elementos, todos os 1000 elementos existentes precisarão ser movidos uma posição para frente.
Vantagens da Lista Sequencial
A lista sequencial oferece várias vantagens que a tornam adequada para muitas aplicações. A principal vantagem é o acesso aleatório rápido, permitindo que você acesse qualquer elemento instantaneamente pelo seu índice. Isso é particularmente útil em situações onde você precisa frequentemente acessar elementos em posições específicas.
Outra vantagem significativa é a localidade de referência. Como os elementos estão armazenados em posições consecutivas de memória, o sistema de cache do computador funciona muito bem, resultando em melhor desempenho durante a iteração sequencial. Além disso, a implementação é simples e direta, tornando o código mais fácil de escrever e depurar.
A lista sequencial também consome menos memória por elemento em comparação com listas encadeadas, pois não precisa armazenar ponteiros adicionais para os elementos vizinhos. Isso pode resultar em economia significativa de memória em listas grandes.
Desvantagens da Lista Sequencial
Apesar de suas vantagens, a lista sequencial também possui desvantagens importantes. A mais significativa é o custo elevado de inserções e remoções no meio da lista, especialmente quando a lista é grande. Cada operação de inserção ou remoção pode exigir o deslocamento de muitos elementos.
Outra desvantagem é a necessidade de alocar memória contígua. Se você não souber o tamanho máximo necessário antecipadamente, pode precisar redimensionar a lista, o que envolve alocar um novo bloco de memória maior e copiar todos os elementos existentes. Este processo pode ser ineficiente e causar fragmentação de memória.
Além disso, o desperdício de espaço pode ocorrer se você alocar mais memória do que realmente precisa. Por exemplo, se você criar uma lista para 1000 elementos mas usar apenas 100, estará desperdiçando espaço para 900 elementos.
Aplicações Práticas da Lista Sequencial
A lista sequencial é amplamente utilizada em diversas aplicações do mundo real. Uma aplicação comum é em sistemas de gerenciamento de banco de dados, onde registros são frequentemente acessados por índice. Listas de reprodução de música, onde você pode pular diretamente para uma música específica, também utilizam esta estrutura.
Em processamento de imagens, as imagens são frequentemente representadas como arrays bidimensionais (matrizes), que são essencialmente listas sequenciais de linhas. Jogos de computador usam listas sequenciais para armazenar informações sobre sprites, pontuações e estados de jogo.
Compiladores e interpretadores usam listas sequenciais para armazenar tabelas de símbolos, onde a busca rápida por nome de variável é essencial. Sistemas operacionais utilizam listas sequenciais para gerenciar filas de processos e memória.
Operações Básicas em uma Lista Sequencial
Para dominar a lista sequencial, é essencial entender suas operações básicas. A operação de inserção pode ser realizada no início, no meio ou no final da lista. Inserir no final geralmente é mais eficiente, a menos que a lista precise ser redimensionada.
A remoção também pode ser feita em qualquer posição. Remover o último elemento é uma operação O(1), enquanto remover do início ou do meio requer deslocamento de elementos. A busca pode ser sequencial ou binária (se a lista estiver ordenada), sendo que a busca binária tem complexidade O(log n).
A atualização de um elemento existente é uma operação O(1) se você souber o índice, tornando-a muito eficiente. A iteração sobre todos os elementos tem complexidade O(n) e é frequentemente usada para processamento em lote.
Implementação de Lista Sequencial em Diferentes Linguagens
A implementação de listas sequenciais varia entre linguagens de programação. Em C, você pode usar arrays estáticos ou alocar memória dinamicamente com malloc. Em Java, a classe ArrayList fornece uma implementação pronta para uso com redimensionamento automático. Python oferece listas nativas que são implementadas como arrays dinâmicos.
Em C++, você pode usar std::vector, que é uma implementação eficiente de lista sequencial. JavaScript tem arrays que funcionam de forma similar, embora sejam mais flexíveis em termos de tipos de elementos. Cada linguagem oferece diferentes compensações entre flexibilidade e desempenho.
Comparação com Outras Estruturas de Dados Lineares
É importante comparar a lista sequencial com outras estruturas de dados lineares para entender quando usá-la. Em comparação com listas encadeadas, a lista sequencial oferece melhor desempenho para acesso aleatório, mas pior desempenho para inserções e remoções frequentes no meio da lista.
Pilhas e filas podem ser implementadas usando listas sequenciais, mas estruturas especializadas podem oferecer melhor desempenho para operações específicas. Deques (filas duplas) combinam características de pilhas e filas e podem ser implementados eficientemente com arrays circulares.
Otimizações e Melhores Práticas
Para usar listas sequenciais de forma eficiente, existem várias otimizações e melhores práticas. Uma delas é alocar espaço extra durante a criação para reduzir a frequência de redimensionamentos. Outra é usar fator de crescimento apropriado (geralmente 1.5x ou 2x) para balancear desperdício de espaço e frequência de realocações.
Para inserções e remoções frequentes no início ou meio, considere usar uma estrutura de dados diferente. Se você precisa de acesso aleatório frequente mas raramente modifica a lista, a lista sequencial é ideal. Para aplicações onde inserções e remoções são frequentes, listas encadeadas podem ser mais adequadas.
Problemas Comuns e Soluções
Ao trabalhar com listas sequenciais, alguns problemas comuns podem surgir. Um deles é o estouro de capacidade, que ocorre quando você tenta inserir em uma lista cheia. A solução é implementar redimensionamento automático ou verificar a capacidade antes de inserir.
Outro problema é a fragmentação de memória, que pode ocorrer após múltiplos redimensionamentos. Isso pode ser mitigado usando alocadores de memória eficientes ou implementando estratégias de crescimento mais inteligentes.
A remoção de elementos pode deixar buracos na lista se não for feita corretamente. É importante sempre manter a contiguidade dos elementos após operações de remoção, deslocando os elementos subsequentes.
Por que Usar um Plataforma de Visualização de Algoritmos?
Para realmente dominar a lista sequencial e outras estruturas de dados, a visualização é uma ferramenta extremamente poderosa. Uma plataforma de visualização de algoritmos permite que você veja exatamente como cada operação funciona, passo a passo, tornando conceitos abstratos muito mais concretos e fáceis de entender.
Em vez de apenas ler sobre como uma inserção funciona, você pode ver os elementos se movendo na tela, entender exatamente quais elementos são afetados e em que ordem as operações acontecem. Esta experiência visual acelera significativamente o aprendizado e ajuda a construir intuição sobre o comportamento das estruturas de dados.
Funcionalidades da Nossa Plataforma de Visualização de Algoritmos
Nossa plataforma de visualização de estruturas de dados oferece funcionalidades projetadas especificamente para ajudar estudantes a compreender listas sequenciais e outros conceitos de algoritmos. Você pode criar listas sequenciais de qualquer tamanho e executar operações passo a passo, vendo cada elemento sendo movido e cada índice sendo atualizado.
A plataforma permite que você visualize a alocação de memória, mostrando exatamente como os elementos estão dispostos na memória do computador. Você pode ver o efeito de cada operação no layout da memória, entendendo por que o acesso aleatório é tão rápido e por que inserções no meio são lentas.
Além disso, a plataforma oferece animações das operações, destacando visualmente os elementos que estão sendo afetados. Você pode pausar, retroceder e avançar as animações para estudar cada etapa com calma. Indicadores visuais mostram a complexidade de tempo de cada operação em tempo real.
Vantagens de Usar Nossa Plataforma para Estudar Listas Sequenciais
Usar nossa plataforma de visualização oferece várias vantagens em relação aos métodos tradicionais de estudo. A visualização interativa permite que você experimente com diferentes cenários e veja imediatamente os resultados. Você pode testar casos extremos, como inserir no início de uma lista grande, e ver exatamente quantos elementos precisam ser deslocados.
A plataforma também oferece comparações lado a lado entre diferentes estruturas de dados, ajudando você a entender as compensações entre lista sequencial e lista encadeada. Você pode ver visualmente por que uma estrutura é melhor para certas operações e outra para operações diferentes.
Outra vantagem importante é o feedback imediato. Se você cometer um erro ao implementar uma operação, a plataforma pode mostrar visualmente onde o erro ocorreu e qual deveria ser o comportamento correto. Isso acelera o processo de aprendizado e ajuda a evitar mal-entendidos comuns.
Como Usar Nossa Plataforma para Estudar Listas Sequenciais
Para começar a usar nossa plataforma, primeiro crie uma nova lista sequencial especificando seu tamanho inicial. Você pode então adicionar elementos manualmente ou gerar automaticamente uma lista de exemplo. A interface mostrará visualmente a lista com índices para cada elemento.
Selecione a operação que deseja executar: inserir, remover, buscar ou atualizar. A plataforma mostrará uma animação passo a passo da operação, com explicações textuais detalhadas de cada etapa. Você pode controlar a velocidade da animação e repetir operações quantas vezes desejar.
Para operações de inserção, você pode escolher a posição exata onde inserir o novo elemento. A plataforma mostrará todos os elementos sendo deslocados para abrir espaço. Para remoção, você verá os elementos sendo movidos para preencher o espaço vazio.
A plataforma também oferece exercícios práticos onde você precisa prever o resultado de uma operação antes de executá-la. Isso testa sua compreensão e ajuda a solidificar o conhecimento. Você pode acompanhar seu progresso e revisar operações onde teve dificuldade.
Exemplos Práticos com Nossa Plataforma
Vamos considerar um exemplo prático. Suponha que você crie uma lista sequencial com 5 elementos: [10, 20, 30, 40, 50]. Usando nossa plataforma, você pode inserir o valor 25 na posição 2 (entre 20 e 30). A animação mostrará os elementos 30, 40 e 50 sendo deslocados uma posição para a direita, resultando em [10, 20, 25, 30, 40, 50].
Outro exemplo: remover o primeiro elemento da lista [10, 20, 30, 40, 50]. A plataforma mostrará todos os elementos sendo deslocados uma posição para a esquerda, resultando em [20, 30, 40, 50]. Você pode ver exatamente como cada elemento se move e entender por que esta operação é O(n).
Para busca, se você procurar o valor 30 em uma lista ordenada, a plataforma pode demonstrar visualmente a busca binária, mostrando como o intervalo de busca é reduzido pela metade a cada passo. Isso ajuda a entender por que a busca binária é tão eficiente.
Recursos Avançados da Plataforma
Nossa plataforma inclui recursos avançados para estudantes mais experientes. Você pode visualizar a representação em memória da lista sequencial, vendo os endereços de memória de cada elemento. Isso ajuda a entender conceitos como alocação de memória e localidade de referência.
A plataforma também permite que você compare diferentes implementações da mesma estrutura de dados. Por exemplo, você pode comparar uma lista sequencial com redimensionamento simples versus uma com redimensionamento otimizado, vendo visualmente a diferença no número de realocações.
Para estudantes que estão aprendendo análise de algoritmos, a plataforma mostra gráficos de desempenho em tempo real, permitindo que você veja como o tempo de execução cresce com o tamanho da lista para diferentes operações. Isso torna conceitos como complexidade O(1), O(n) e O(log n) muito mais tangíveis.
Integração com Outros Tópicos de Estruturas de Dados
A lista sequencial é frequentemente a base para entender outras estruturas de dados. Nossa plataforma permite que você veja como pilhas e filas podem ser implementadas usando listas sequenciais, e como as operações específicas dessas estruturas se traduzem em operações na lista subjacente.
Você pode explorar como listas sequenciais são usadas em implementações de tabelas hash, onde a lista armazena as entradas da tabela. A plataforma mostra visualmente como o hash é calculado e como as colisões são resolvidas.
Para estruturas mais complexas como árvores e grafos, a plataforma mostra como listas sequenciais podem ser usadas para representar matrizes de adjacência e listas de adjacência, permitindo que você compare as vantagens de cada representação.
Benefícios para Diferentes Níveis de Aprendizado
Nossa plataforma é projetada para beneficiar estudantes em todos os níveis de aprendizado. Para iniciantes, as visualizações básicas e explicações passo a passo tornam conceitos abstratos acessíveis. Você pode começar com operações simples como inserir e remover, e gradualmente avançar para tópicos mais complexos.
Para estudantes intermediários, a plataforma oferece recursos para aprofundar a compreensão, como visualização de memória e análise de complexidade. Você pode experimentar com diferentes cenários e ver como pequenas mudanças na implementação afetam o desempenho.
Para estudantes avançados, a plataforma permite explorar implementações otimizadas e comparar diferentes estratégias. Você pode modificar parâmetros como fator de crescimento e ver como isso afeta o desempenho geral da estrutura.
Suporte para Diferentes Estilos de Aprendizado
Reconhecemos que cada pessoa aprende de forma diferente. Nossa plataforma oferece múltiplas formas de interagir com o conteúdo. Além das animações visuais, fornecemos explicações textuais detalhadas, diagramas estáticos para referência rápida e exercícios interativos para prática.
Você pode alternar entre diferentes modos de visualização, desde uma visão simplificada focada nos elementos até uma visão detalhada mostrando endereços de memória e ponteiros. Isso permite que você escolha o nível de detalhe mais adequado ao seu estágio de aprendizado.
A plataforma também oferece suporte para audiodescrição das operações, beneficiando estudantes que preferem aprendizado auditivo. Você pode ouvir uma narração detalhada de cada etapa enquanto acompanha visualmente a animação.
Comunidade e Recursos de Aprendizado
Além das funcionalidades da plataforma, oferecemos uma comunidade ativa de estudantes e instrutores. Você pode compartilhar suas visualizações, discutir dúvidas e aprender com exemplos criados por outros usuários. A comunidade também contribui com exercícios e desafios que ajudam a testar seu conhecimento.
Nossa biblioteca de exemplos inclui centenas de cenários pré-configurados que ilustram diferentes aspectos das listas sequenciais. Você pode explorar casos de uso comuns, problemas de entrevista técnica e implementações em diferentes linguagens de programação.
Oferecemos também tutoriais guiados que combinam leitura teórica com exercícios práticos na plataforma. Cada tutorial é projetado para construir gradualmente sua compreensão, com verificações de conhecimento ao longo do caminho.
Conclusão: Domine Listas Sequenciais com Visualização Interativa
A lista sequencial é uma estrutura de dados fundamental que todo estudante de ciência da computação precisa dominar. Compreender seus princípios, vantagens e limitações é essencial para construir uma base sólida em algoritmos e estruturas de dados.
Nossa plataforma de visualização de algoritmos oferece as ferramentas necessárias para tornar este aprendizado mais eficiente e agradável. Através de visualizações interativas, animações passo a passo e exercícios práticos, você pode desenvolver uma compreensão profunda e intuitiva das listas sequenciais.
Convidamos você a experimentar nossa plataforma e descobrir como a visualização pode transformar seu aprendizado de estruturas de dados. Comece hoje mesmo sua jornada para dominar listas sequenciais e outros conceitos fundamentais de algoritmos.
时间复杂度:
最好情况:要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为$O(1)$,即常数时间复杂度。
最坏情况:要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中。在这种情况下,时间复杂度为$O(n)$,其中$n$是顺序表中元素的个数。
平均情况:平均情况的时间复杂度通常是$O(\frac n 2)$,因为平均而言,我们可以认为要查找的元素在顺序表的中间位置。但是在大$O$表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是$O(n)$。
2.1.3 顺序表数组实现的优点与缺点
1 优点
随机访问速度快:由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 $O(1)$。这使得数组在需要频繁随机访问元素的情况下非常高效。
节约空间:相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间。
缓存友好:由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势。
2 缺点
固定大小:数组的大小是固定的,一旦创建后就不能动态改变。如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销。
插入和删除操作效率低:在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 $O(n)$。这使得数组在频繁插入和删除操作的场景下效率较低。
不适合存储变长数据:由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求。