 图码
图码1.1 什么是数据结构?
在计算机世界中,数据结构代表了计算机在内存中存储和组织数据的独特方法。通过不同的排列和组合方式,可以使用户高效且适当的方式访问和使用他们所需的数据。
数据结构的存在使用户能够方便地按需访问和操作他们的数据,有助于以高效而紧凑的方式组织和检索各种类型的数据。
对于接触过计算机基础知识的读者而言,对于下面这个公式应该不会陌生:
算法 + 数据结构 = 程序
提出这一公式并以此作为其一本专著书名Algorithms + Data Structures = Programs的瑞士计算机科学家Niklaus Wirth于1984年获得了图灵奖。
程序(Program)是由数据结构(Data Structure)和算法(Algorithm)组成,这意味着的程序的好和快是直接由程序所采用的数据结构和算法决定的。
❗️ 注意
本章节仅作介绍,涉及到的具体数据结构和算法会在后续章节中详细讲解。
数据结构分类
数据也可以被细分为以下两种类型:
线性结构
非线性结构
线性结构
数据元素按顺序或者线性排列
除了第一个元素和最后一个元素之外,剩余每个元素都有前一个和下一个相邻元素。
有两种技术可以在内存中表示这种线性结构。
数组:存储在连续内存位置的相同数据类型的项目的集合。
链表:通过使用指针或链接的概念来表示的所有元素之间的线性关系。
常见的线性结构例子有:
数组:存储在连续内存位置的元素的集合。
链表:节点的集合,每个节点包含一个元素和对下一个节点的引用。
堆栈:具有后进先出 (LIFO)顺序的元素集合。
队列:具有先进先出 (FIFO)顺序的元素集合。
非线性结构
该结构主要用于表示包含各种元素之间的层次关系的数据。
常见的非线性结构例子有:
图:顶点(节点)和表示顶点之间关系的边的集合。图用于建模和分析网络,例如社交网络或交通网络。
树:树的结构呈现出一个类似根和分支的形状,其中有一个根节点,从根节点出发,分成多个子节点,每个子节点可以又分为更多的子节点,依此类推
各种数据结构的简单介绍
数组(Arrays)
数组是相似数据元素的集合。这些数据元素具有相同的数据类型。
数组的元素存储在连续的内存位置中,并由索引(也称为下标)来指向数据。
在C语言中,数组声明使用以下格式:
- 1
- 2
- 3
ElemType name[size];
//例如
char array[10] = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'
// 完整代码:https://totuma.cn上面的语句声明了一个包含10个元素的数组标记。 在C中,数组索引从零开始。这意味着数组标记将总共包含10个元素。
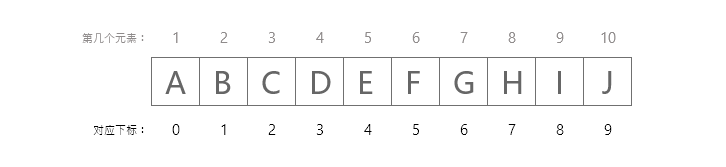
数组下标对应位序
第一个元素将存储在array[0]中,第二个元素将存储在array[1]中,等等。因此,最后一个元素,即第10个元素,将被存储在array[9]中。 在计算机中存储如下图所示。
当我们想要存储大量相同类型的数据时,通常会使用数组。当然,数组也有一些限制,比如:
数组的大小是固定的。
数据元素存储在连续的内存位置中,但是内存中剩余的大小可能不足以容纳当前数组。
元素的插入和删除会很麻烦。
链表(Linked Lists)
链表是一种非常灵活的动态数据结构,其中元素(称为节点)形成一个顺序列表。 与静态数组相比,我们不需要担心链表中将存储多少个元素。这个特性使我们能够编写需要较少维护的健壮程序。在链表中,每个节点都有data域和next指针域:
data域:存放该节点或与该节点对应的任何其他数据的值。
next指针域:指向列表中的下一个节点的指针或链接。
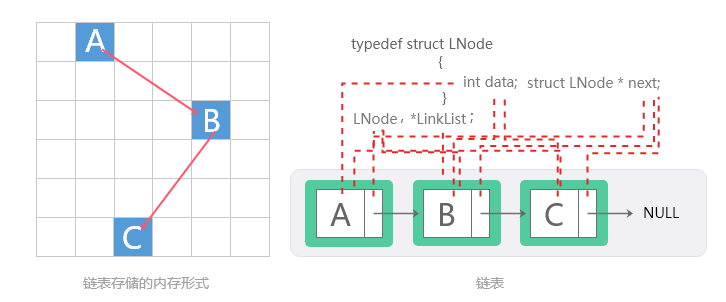
链表结构
列表中的最后一个节点包含一个NULL指针,表明它是当前列表的尾。由于节点的内存是在添加到列表中时动态分配的,因此可以添加到列表中的节点总数仅受可用内存量的限制。具体结构可见下图:
栈(Stacks)
栈是一种线性数据结构, 其中元素的插入和删除只在一端完成,这被称为栈顶。 栈被称为先入后出(LIFO)结构,因为添加到堆栈中的最后一个元素是从堆栈中删除的第一个元素。在计算机的内存中,堆栈可以使用数组或链表来实现。
下面可视化操作显示了一个栈的数组实现。每个栈都有一个与其关联的变量top,用于指向最上面的元素。这是将从中添加或删除元素的位置。
栈支持push 入栈和pop 出栈 操作,push 就是在从栈顶中压入一个元素,pop 就是在栈顶中弹出一个元素,即增和删。
💡 提示
点击下方的入栈、出栈按钮。可以明了的理解到什么是先入后出。
栈 | 可视化完整可视化
1.1 O que é uma Estrutura de Dados? - Tutorial de Estruturas de Dados Visualize seu código com animações

O que são Estruturas de Dados Lineares? Uma Introdução para Iniciantes
Se você está começando seus estudos em ciência da computação ou se preparando para entrevistas técnicas, certamente já ouviu falar sobre estruturas de dados. Entre as mais fundamentais estão as estruturas lineares, que organizam os elementos de forma sequencial. Neste artigo, vamos explorar em detalhes três tipos essenciais: a lista linear (ou sequencial), a pilha e a lista sequencial (também conhecida como vetor ou array). Utilizaremos uma abordagem prática, com exemplos do dia a dia, e mostraremos como um plataforma de visualização de algoritmos e estruturas de dados pode transformar completamente seu aprendizado.
O que é uma Lista Linear (Sequencial)?
Uma lista linear, também chamada de lista sequencial ou simplesmente lista, é a estrutura de dados mais básica e intuitiva. Imagine uma lista de compras, uma fila de espera no banco ou os nomes dos alunos em uma chamada. Todos esses são exemplos de listas lineares. A principal característica é que cada elemento, exceto o primeiro e o último, possui um antecessor e um sucessor direto. Os elementos são organizados um após o outro em uma sequência lógica.
Em termos computacionais, uma lista linear pode ser implementada de duas maneiras principais: usando um vetor (array) ou usando nós encadeados (linked list). Neste artigo, focaremos na implementação por vetor, que é a base para entender a lista sequencial.
O que é uma Lista Sequencial (Vetor)?
A lista sequencial é uma implementação concreta de uma lista linear onde os elementos são armazenados em posições contíguas de memória. Pense nela como uma fileira de cadeiras numeradas em um teatro. Cada cadeira tem um número único (índice) e, para acessar uma pessoa sentada em qualquer cadeira, basta saber o número dela. Isso torna o acesso a qualquer elemento extremamente rápido, com complexidade O(1) no pior caso.
Principais características da lista sequencial:
- Acesso direto: Você pode acessar qualquer elemento instantaneamente usando seu índice.
- Tamanho fixo (na maioria das implementações tradicionais): Ao criar um vetor, você define quantos elementos ele pode armazenar. Se precisar de mais espaço, é necessário criar um novo vetor maior e copiar todos os dados.
- Inserção e remoção no final são rápidas: Adicionar ou remover um elemento no final da lista não exige deslocamento de outros elementos.
- Inserção e remoção no início ou no meio são lentas: Para adicionar um elemento no início, todos os outros elementos precisam ser deslocados uma posição para a direita. Isso tem complexidade O(n).
Aplicações comuns da lista sequencial:
- Armazenar dados de uma tabela em um banco de dados.
- Manter uma lista de reprodução de músicas.
- Representar matrizes em computação gráfica.
- Implementar outras estruturas de dados, como pilhas e filas.
O que é uma Pilha (Stack)?
A pilha é uma estrutura de dados linear que segue o princípio LIFO (Last In, First Out) – “o último a entrar é o primeiro a sair”. Imagine uma pilha de pratos em um restaurante. O garçom sempre pega o prato que está no topo (o último que foi colocado). Para colocar um novo prato, ele também o coloca no topo. Não é possível acessar um prato do meio sem antes retirar todos os que estão acima dele.
Operações básicas de uma pilha:
- Push (empilhar): Insere um elemento no topo da pilha.
- Pop (desempilhar): Remove e retorna o elemento do topo da pilha.
- Top ou Peek (topo): Retorna o elemento do topo sem removê-lo.
- IsEmpty (está vazia?): Verifica se a pilha está vazia.
Características importantes da pilha:
- O acesso é restrito ao topo. Você nunca acessa elementos do meio diretamente.
- Inserções e remoções são sempre O(1), pois ocorrem sempre em uma extremidade (o topo).
- É uma estrutura simples, porém extremamente poderosa.
Aplicações clássicas da pilha:
- Desfazer/Refazer (Undo/Redo): Em editores de texto, cada ação é empilhada. O comando “Desfazer” desempilha a última ação.
- Navegação em navegadores: O botão “Voltar” desempilha a página atual e volta para a página anterior na pilha de histórico.
- Avaliação de expressões matemáticas: Compiladores usam pilhas para converter expressões infixas (como 2 + 3) para pós-fixas (2 3 +) e avaliá-las.
- Chamadas de funções (Call Stack): Quando um programa executa uma função, o endereço de retorno e as variáveis locais são empilhados. Quando a função termina, esses dados são desempilhados.
- Algoritmos de backtracking: Como o problema do labirinto, onde você precisa tentar caminhos e voltar atrás quando encontra um beco sem saída.
Diferenças Cruciais entre Lista Sequencial e Pilha
Embora ambas sejam estruturas lineares, suas diferenças são fundamentais para escolher a ferramenta certa para cada problema.
Lista Sequencial (Vetor):
- Permite acesso aleatório a qualquer elemento.
- Inserção e remoção podem ser feitas em qualquer posição, mas com custo O(n) no pior caso.
- Ideal quando você precisa acessar dados frequentemente por índice.
Pilha:
- Permite acesso apenas ao topo.
- Inserção e remoção são sempre O(1).
- Ideal quando a ordem de processamento é inversa à ordem de chegada (LIFO).
Pense na lista sequencial como uma estante de livros onde você pode pegar qualquer livro de qualquer prateleira. A pilha é como uma caixa de biscoitos onde você só pode pegar o biscoito que está no topo.
Por que Visualizar Estruturas de Dados é Essencial?
Muitos alunos têm dificuldade em entender como essas estruturas funcionam internamente. É comum ler sobre o princípio LIFO da pilha e ainda assim não compreender como o computador realmente gerencia a memória. É aqui que uma plataforma de visualização de algoritmos e estruturas de dados se torna uma ferramenta indispensável.
Em vez de apenas ler teoria, você pode ver, em tempo real, cada elemento sendo inserido, removido ou acessado. A visualização transforma conceitos abstratos em imagens concretas. Você pode ver as setas apontando para o topo da pilha, os índices da lista sequencial sendo atualizados e os elementos se deslocando durante uma inserção no meio da lista.
Funcionalidades de uma Plataforma de Visualização de Estruturas de Dados
Uma boa plataforma de visualização oferece muito mais do que apenas animações bonitas. Ela é uma ferramenta completa de aprendizado. Veja as principais funcionalidades que você deve procurar:
- Animação passo a passo: Você pode executar cada operação (push, pop, inserir, remover) um passo de cada vez, vendo exatamente o que acontece na memória.
- Controles de velocidade: Permite acelerar ou desacelerar a animação conforme sua necessidade de compreensão.
- Código-fonte sincronizado: A plataforma mostra o código (em C, Java, Python, etc.) sendo executado e destaca a linha correspondente à animação atual. Isso conecta a teoria à prática.
- Simulação de diferentes cenários: Você pode testar casos extremos, como inserir em uma lista cheia, remover de uma pilha vazia, ou buscar um elemento que não existe.
- Comparação de desempenho: Algumas plataformas mostram o número de operações realizadas (complexidade) em tempo real, ajudando a entender por que um algoritmo é mais eficiente que outro.
- Suporte a múltiplas estruturas: A plataforma ideal oferece visualizações para listas, pilhas, filas, árvores, grafos, tabelas hash, etc.
Como Usar uma Plataforma de Visualização para Aprender sobre Listas, Pilhas e Listas Sequenciais
Se você está começando agora, siga este roteiro prático usando a plataforma de visualização:
Passo 1: Estude a Lista Sequencial (Vetor).
Na plataforma, selecione a estrutura “Lista Sequencial” ou “Array”. Crie uma lista vazia. Agora, execute as seguintes operações, observando atentamente a animação:
- Insira alguns elementos no final da lista. Veja como eles ocupam posições consecutivas.
- Insira um elemento no início da lista. Observe como todos os outros elementos são deslocados uma posição para a direita. Conte quantos movimentos foram necessários.
- Remova um elemento do meio da lista. Veja o deslocamento para a esquerda.
- Tente acessar um elemento pelo índice. Veja como o acesso é instantâneo, sem movimentação.
Passo 2: Estude a Pilha (Stack).
Agora, selecione a estrutura “Pilha” ou “Stack”. Observe que há apenas uma extremidade ativa: o topo.
- Use a operação “Push” para empilhar elementos. Veja como cada novo elemento é colocado no topo.
- Use a operação “Pop” para desempilhar. Observe que o elemento removido é sempre o último que entrou.
- Use a operação “Top” ou “Peek”. Veja que o elemento do topo é apenas visualizado, não removido.
- Tente acessar um elemento que não seja o topo. A plataforma deve mostrar um erro, reforçando a regra LIFO.
Passo 3: Compare as duas estruturas lado a lado.
Muitas plataformas permitem abrir duas visualizações simultâneas. Coloque a lista sequencial em uma janela e a pilha em outra. Realize as mesmas operações (inserir e remover) e veja como os comportamentos são diferentes. Isso solidifica o entendimento de quando usar cada uma.
Vantagens de Usar uma Plataforma de Visualização no seu Aprendizado
O uso de uma plataforma de visualização não é apenas um “extra” no estudo. É uma mudança de paradigma que acelera o aprendizado de várias maneiras:
- Aprendizado Ativo: Você não é um espectador passivo. Você interage, executa operações e vê as consequências imediatas de suas ações.
- Memorização Visual: Imagens e animações são processadas mais rapidamente pelo cérebro e são mais fáceis de lembrar do que texto puro. Você se lembrará da animação da pilha quando precisar usar uma no futuro.
- Depuração de Erros: Quando você comete um erro de lógica (por exemplo, tentar remover de uma pilha vazia), a plataforma mostra visualmente o erro, ajudando a entender por que aquilo não é permitido.
- Preparação para Entrevistas: Em entrevistas técnicas, é comum que o entrevistador peça para você desenhar o funcionamento de uma estrutura de dados. Ter visualizado isso centenas de vezes na plataforma torna essa tarefa muito mais fácil.
- Base para Algoritmos Complexos: Estruturas de dados são a base para algoritmos. Se você não entende profundamente como uma pilha funciona, terá dificuldade em entender algoritmos de backtracking ou avaliação de expressões. A visualização constrói essa base sólida.
Exemplo Prático: Simulando um Editor de Texto com Pilha
Vamos usar a plataforma de visualização para simular o recurso “Desfazer” de um editor de texto. Suponha que você digitou as palavras: “Olá”, “Mundo”, “!”.
Na plataforma (Pilha):
- Empilhe (Push) a string “Olá”.
- Empilhe (Push) a string “Mundo”.
- Empilhe (Push) a string “!”.
Agora sua pilha tem: Topo -> “!” -> “Mundo” -> “Olá” (fundo).
Se você quiser desfazer a última ação (remover o “!”), você executa um Pop. A plataforma mostra o elemento “!” sendo removido do topo. Agora a pilha tem: Topo -> “Mundo” -> “Olá”. Se você executar outro Pop, “Mundo” é removido. Isso demonstra perfeitamente o conceito LIFO aplicado ao mundo real.
Agora, tente fazer o mesmo com uma lista sequencial. Você verá que, para remover o último elemento, você precisa saber o índice dele. A lista sequencial não tem o conceito de “topo”. Isso mostra por que a pilha é a estrutura ideal para esse problema.
Exemplo Prático: Simulando uma Fila de Banco com Lista Sequencial
Embora a fila (Queue) seja outra estrutura (FIFO), a lista sequencial pode ser usada para implementá-la. Vamos simular uma fila de banco usando uma lista sequencial na plataforma.
Na plataforma (Lista Sequencial):
- Insira “Cliente 1” no final da lista.
- Insira “Cliente 2” no final da lista.
- Insira “Cliente 3” no final da lista.
Agora sua lista é: [“Cliente 1”, “Cliente 2”, “Cliente 3”].
O primeiro cliente a ser atendido é o “Cliente 1”. Para removê-lo, você precisa removê-lo do início da lista. Na plataforma, execute a remoção no índice 0. Observe como “Cliente 2” e “Cliente 3” são deslocados para a esquerda. Isso demonstra o custo O(n) da remoção no início de uma lista sequencial. Se você estivesse usando uma fila implementada com nós encadeados (linked list), essa remoção seria O(1). A visualização deixa claro por que, para filas, a implementação encadeada é geralmente preferível.
Dicas para Aproveitar ao Máximo a Plataforma de Visualização
Para realmente dominar as estruturas de dados, não se limite a apenas assistir às animações. Siga estas dicas:
- Antecipe o resultado: Antes de clicar em “Executar”, pergunte a si mesmo: “O que vai acontecer agora?”. Tente prever a animação. Se errar, analise por que errou.
- Varie os dados de entrada: Teste com listas vazias, listas com um único elemento, listas cheias. Veja como a estrutura se comporta em cada caso limite.
- Use o modo passo a passo: Não pule etapas. Cada passo revela um detalhe importante.
- Leia o código sincronizado: Se a plataforma oferecer, preste atenção na linha de código sendo destacada. Isso conecta a lógica visual à implementação real.
- Repita o processo: A primeira vez que você vê uma animação, você entende o conceito. Na segunda vez, você começa a notar os detalhes. Na terceira, você já consegue prever cada movimento.
Conclusão: Domine Estruturas de Dados com Visualização
As estruturas de dados lineares – lista sequencial e pilha – são pilares fundamentais da computação. A lista sequencial oferece acesso rápido a qualquer elemento, mas paga o preço com inserções e remoções custosas no meio. A pilha, com sua simplicidade LIFO, é perfeita para problemas que exigem ordem reversa de processamento, como desfazer ações ou gerenciar chamadas de funções.
Entender esses conceitos apenas na teoria é possível, mas a verdadeira maestria vem da prática e da visualização. Uma plataforma de visualização de algoritmos e estruturas de dados não é apenas uma ferramenta de estudo; é um laboratório virtual onde você pode experimentar, errar, aprender e, finalmente, internalizar cada detalhe do funcionamento interno dessas estruturas.
Comece hoje mesmo. Escolha uma plataforma confiável, selecione a estrutura “Lista Sequencial” ou “Pilha” e comece a interagir. Você verá que, em pouco tempo, conceitos que pareciam complexos se tornarão intuitivos e naturais. Invista no seu aprendizado com ferramentas visuais e transforme sua compreensão sobre estruturas de dados.
Referências e Próximos Passos
Depois de dominar listas sequenciais e pilhas, você estará pronto para explorar outras estruturas igualmente importantes:
- Filas (Queue): Estrutura FIFO (First In, First Out), usada em gerenciamento de tarefas e buffers.
- Listas Encadeadas (Linked List): Uma alternativa à lista sequencial, com inserções e remoções mais eficientes, mas sem acesso aleatório.
- Árvores (Trees): Estruturas hierárquicas usadas em bancos de dados e inteligência artificial.
- Grafos (Graphs): Usados em redes sociais, mapas e sistemas de recomendação.
- Tabelas Hash (Hash Tables): Estruturas que oferecem acesso extremamente rápido a dados através de chaves.
Continue praticando com a plataforma de visualização e você construirá uma base sólida para se tornar um excelente profissional de tecnologia. Lembre-se: a chave para o aprendizado de estruturas de dados é a prática constante e a visualização ativa.
队列(Queues)
队列是一种先进先出(FIFO)的数据结构,其中首先插入的元素是第一个要取出的元素。 队列中的元素在队尾添加,然后在队头删除。 与栈一样,队列也可以通过使用数组或链表来实现。 每个队列都有队头和队尾,分别指向可以进行删除和插入的位置。
队列 | 可视化完整可视化
1.1 O que é uma Estrutura de Dados? - Tutorial de Estruturas de Dados Visualize seu código com animações
O que é uma Fila (Queue) e sua Implementação com Lista Sequencial (Vetor)
Uma fila (queue) é uma estrutura de dados fundamental na ciência da computação, amplamente utilizada em algoritmos e sistemas do dia a dia. O princípio básico de uma fila é o FIFO (First-In, First-Out), que significa "o primeiro a entrar é o primeiro a sair". Imagine uma fila de banco: a primeira pessoa que chega é a primeira a ser atendida. Em termos de programação, uma fila armazena uma coleção de elementos onde a inserção ocorre em uma extremidade (chamada de final ou traseira) e a remoção ocorre na outra extremidade (chamada de frente ou cabeça). Quando implementamos uma fila usando uma lista sequencial (também conhecida como vetor ou array), estamos utilizando uma estrutura de armazenamento contíguo na memória. Neste artigo, vamos explorar detalhadamente os conceitos, princípios, aplicações e como um plataforma de visualização de algoritmos pode transformar seu aprendizado sobre filas e listas sequenciais.
Princípios Fundamentais da Fila (Queue)
O comportamento de uma fila é estritamente controlado por duas operações principais: enqueue (inserir) e dequeue (remover). A operação enqueue adiciona um novo elemento ao final da fila. A operação dequeue remove o elemento que está na frente da fila. Além disso, existem operações auxiliares como front (consultar o elemento da frente sem removê-lo), rear (consultar o elemento do final) e isEmpty (verificar se a fila está vazia). A restrição de acesso apenas às extremidades é o que define a disciplina FIFO. Diferente de uma pilha (stack), onde o último a entrar é o primeiro a sair (LIFO), a fila garante que todos os elementos sejam processados na ordem exata de chegada. Este comportamento é crítico em sistemas onde a ordem de chegada deve ser preservada, como em sistemas de impressão, gerenciamento de processos em sistemas operacionais e algoritmos de busca em largura (BFS).
Implementação de Fila com Lista Sequencial (Vetor)
Uma lista sequencial é uma estrutura de dados onde os elementos são armazenados em posições consecutivas de memória, acessíveis por um índice. Para implementar uma fila usando um vetor, precisamos de um array de tamanho fixo (ou dinâmico) e duas variáveis: front (índice do primeiro elemento) e rear (índice do último elemento). Inicialmente, front e rear são definidos como -1 para indicar que a fila está vazia. Quando inserimos um elemento (enqueue), incrementamos rear e colocamos o valor na posição rear do vetor. Quando removemos um elemento (dequeue), retornamos o valor na posição front e incrementamos front. No entanto, essa implementação ingênua tem um problema grave: desperdício de espaço. Conforme os elementos são removidos da frente, as posições anteriores do vetor ficam vazias, mas não podem ser reutilizadas. Para resolver isso, utilizamos o conceito de fila circular.
Fila Circular com Vetor: A Solução Inteligente
A fila circular é uma variação da implementação com vetor que reutiliza as posições liberadas. Em vez de tratar o vetor como uma linha reta, tratamos ele como um círculo. Quando rear ou front atingem o final do vetor, eles voltam para o início (índice 0). Isso é feito usando a operação de módulo (%). Por exemplo, se o vetor tem tamanho N, ao incrementar rear, fazemos rear = (rear + 1) % N. Desta forma, as posições que foram removidas da frente podem ser reutilizadas para novas inserções. A condição de fila vazia continua sendo front == -1 (ou uma condição equivalente). A condição de fila cheia, em uma implementaço circular, geralmente é (rear + 1) % N == front. Isso significa que reservamos uma posição do vetor para distinguir entre fila cheia e fila vazia. A implementação com lista sequencial circular é eficiente em termos de memória e tempo de execução, pois todas as operações (enqueue, dequeue) têm complexidade O(1) – tempo constante.
Vantagens e Desvantagens da Fila com Lista Sequencial
Vantagens: A principal vantagem é a eficiência de acesso. Como os elementos estão armazenados em um vetor, o acesso à memória é rápido e previsível. As operações de enqueue e dequeue são extremamente rápidas (O(1)) quando implementadas corretamente com uma fila circular. Além disso, vetores têm baixo overhead de memória comparado a estruturas baseadas em nós (como listas encadeadas), pois não precisam armazenar ponteiros adicionais. Desvantagens: A principal desvantagem é o tamanho fixo. Uma vez que o vetor é alocado com um tamanho máximo, se a fila ultrapassar esse limite, ocorrerá um estouro (overflow). Para contornar isso, podemos implementar um vetor dinâmico (redimensionável), mas isso envolve copiar todos os elementos para um novo vetor, o que tem custo O(n) ocasionalmente. Outra desvantagem é que, se a fila for muito grande e o tamanho máximo for subutilizado, há desperdício de memória.
Aplicações Clássicas da Fila em Algoritmos
A fila é uma estrutura onipresente em ciência da computação. Uma das aplicações mais conhecidas é o algoritmo de busca em largura (BFS - Breadth-First Search) em grafos. O BFS utiliza uma fila para explorar todos os vértices de um grafo nível por nível. Outra aplicação fundamental é em sistemas operacionais, onde filas são usadas para gerenciar processos (escalonamento de CPU), gerenciar filas de impressão e gerenciar buffers de E/S. Em redes de computadores, filas são usadas em roteadores e switches para armazenar pacotes que aguardam processamento ou transmissão. Em simulações, filas são usadas para modelar sistemas de filas de espera (como caixas de supermercado). Em programação concorrente, filas são usadas como buffers para comunicação entre threads (produtor-consumidor). Até mesmo em algoritmos de cache (como FIFO cache) a fila está presente.
Por que Visualizar uma Fila com Lista Sequencial?
Entender o comportamento interno de uma fila circular pode ser desafiador apenas com código estático. É aí que uma plataforma de visualização de algoritmos e estruturas de dados se torna indispensável. Quando você pode ver os índices front e rear se movendo, os elementos sendo inseridos e removidos, e o vetor sendo tratado como um círculo, o conceito se torna muito mais concreto. A visualização ajuda a internalizar por que a operação de módulo é necessária, como a fila contorna o final do vetor, e como as condições de cheia e vazia são verificadas. Para um estudante de algoritmos, a visualização reduz a abstração e acelera o aprendizado.
Funcionalidades de uma Plataforma de Visualização de Algoritmos
Uma boa plataforma de visualização de estruturas de dados oferece muito mais do que apenas animações. Ela deve permitir que o usuário controle o ritmo do aprendizado. Funcionalidades essenciais incluem: controles de passo a passo (avançar, retroceder, pausar), destaque da linha de código correspondente à operação sendo executada, visualização do estado da memória (mostrando os índices e valores do vetor), simulação de operações manuais (inserir e remover elementos clicando em botões), e animação de fila circular (mostrando visualmente como front e rear se movem em círculo). Além disso, a plataforma deve oferecer múltiplos exemplos de aplicações (como BFS ou simulação de fila de impressão) para mostrar o uso prático. A capacidade de alterar o tamanho do vetor e ver como o comportamento muda é outro recurso pedagógico poderoso.
Vantagens de Usar uma Plataforma de Visualização para Aprender Filas
O aprendizado visual tem benefícios comprovados. Para estruturas de dados como filas, a visualização permite que o aluno veja a dinâmica temporal da estrutura. Em vez de imaginar mentalmente como os elementos se movem, o aluno observa diretamente. Isso reduz a carga cognitiva e permite focar nos conceitos fundamentais. Além disso, a plataforma permite a experimentação ativa: o aluno pode testar casos extremos, como inserir em uma fila cheia, remover de uma fila vazia, ou ver o que acontece quando front ultrapassa rear. Essa experimentação é difícil de fazer apenas com código. Outra vantagem é a correlação imediata entre código e execução. Ao ver o código C, Python ou Java sendo executado linha a linha enquanto a fila se modifica, o aluno entende exatamente como cada instrução afeta a estrutura de dados.
Como Usar uma Plataforma de Visualização para Estudar Filas
O uso eficaz de uma plataforma de visualização segue uma metodologia. Primeiro, configure o ambiente: escolha a estrutura "Fila" e o tipo de implementação "Lista Sequencial (Vetor)". Defina um tamanho pequeno para o vetor (por exemplo, 5) para facilitar a visualização. Em seguida, realize operações básicas: insira alguns elementos (enqueue) um por um, observando como rear se move. Depois, remova elementos (dequeue) e veja front se mover. Observe como os índices se comportam. Depois, explore a fila circular: continue inserindo até que rear atinja o final do vetor. Insira mais um elemento e veja como rear "dá a volta" para o início. Tente inserir até que a fila fique cheia. Veja a condição de cheia sendo acionada. Depois, remova alguns elementos e insira novamente, observando a reutilização do espaço. Finalmente, relacione com aplicações: use a plataforma para simular um algoritmo BFS em um grafo pequeno, ou uma fila de impressão. Veja como a fila gerencia a ordem dos elementos. Repita os passos quantas vezes forem necessárias, usando os controles de passo a passo para solidificar o entendimento.
Características Técnicas da Implementação com Vetor
Do ponto de vista de implementação, a fila com vetor requer atenção a detalhes. O tamanho do vetor (capacidade máxima) deve ser definido no momento da criação. As variáveis front e rear são índices inteiros. A operação enqueue(valor) verifica se a fila está cheia. Se não estiver, atualiza rear (circularmente) e insere o valor. Se a fila estava vazia, front também deve ser atualizado. A operação dequeue() verifica se a fila está vazia. Se não estiver, armazena o valor de front, atualiza front (circularmente) e, se a fila ficar vazia após a remoção, rear também deve ser resetado. A complexidade de espaço é O(N), onde N é a capacidade máxima. A complexidade de tempo de todas as operações é O(1). É importante notar que, em linguagens como C, o programador é responsável pelo gerenciamento de memória. Em linguagens como Java ou Python, o vetor é um objeto que gerencia sua própria memória, mas ainda assim tem tamanho fixo a menos que seja redimensionado manualmente.
Comparação com Outras Implementações de Fila
Além da lista sequencial, filas podem ser implementadas com listas encadeadas (linked list). A principal diferença é que a lista encadeada não tem tamanho fixo, permitindo crescimento dinâmico sem a necessidade de redimensionamento. No entanto, cada elemento em uma lista encadeada requer memória extra para o ponteiro do próximo nó, e o acesso aos elementos não é sequencial na memória, o que pode causar mais cache misses. A fila com vetor, por outro lado, tem melhor localidade de referência e menor overhead de memória por elemento, mas sofre com o tamanho fixo. A fila com vetor dinâmico (como ArrayList em Java ou list em Python) tenta combinar o melhor dos dois mundos: oferece redimensionamento automático, mas com custo O(n) ocasional para realocação. Para a maioria dos cenários de aprendizado, a implementação com vetor de tamanho fixo é a mais didática, pois expõe claramente os conceitos de índice, circularidade e gerenciamento de espaço.
Erros Comuns ao Aprender Filas com Vetor
Muitos estudantes cometem erros ao implementar ou entender filas com vetor. Um erro clássico é confundir front e rear, ou não atualizar ambos corretamente quando a fila está vazia. Outro erro é esquecer a condição de fila cheia e tentar inserir em um vetor lotado, causando perda de dados. Na implementação circular, é comum errar a condição de cheia, usando front == rear (que também é a condição de vazia em algumas implementações). A distinção entre fila vazia e fila cheia é um ponto crítico. Também é comum não entender por que uma posição do vetor fica "perdida" na implementação circular (para diferenciar cheia de vazia). A plataforma de visualização ajuda a evitar esses erros, pois o aluno pode ver exatamente o estado do vetor e dos índices a cada operação.
O Papel da Visualização na Depuração de Algoritmos
Para além do aprendizado inicial, a visualização é uma ferramenta poderosa de depuração. Quando um algoritmo que usa fila não funciona como esperado, ser capaz de ver o estado interno da fila em cada etapa pode revelar bugs sutis. Por exemplo, em uma implementação de BFS, se a fila não estiver gerenciando corretamente a ordem, a visualização mostra imediatamente onde a ordem foi quebrada. A plataforma de visualização permite que o estudante ou desenvolvedor "entre" na execução do algoritmo, algo que é difícil de fazer apenas com print statements ou debuggers tradicionais. Isso acelera drasticamente o ciclo de aprendizado e correção de erros.
Exemplos Práticos de Uso da Fila em Cenários Reais
Vamos detalhar alguns cenários onde a fila com vetor é aplicada. Em um sistema de fila de impressão, documentos são enviados para uma fila. O primeiro documento enviado é o primeiro a ser impresso. Se a fila for implementada com um vetor, o tamanho máximo da fila limita o número de documentos na fila de espera. Em um buffer de teclado, as teclas digitadas são armazenadas em uma fila até que o sistema as processe. Se o buffer encher (fila cheia), teclas podem ser perdidas. Em algoritmos de roteamento, pacotes são enfileirados em portas de saída. A implementação com vetor é comum em hardware devido à sua simplicidade e previsibilidade. Em simulações de atendimento (como call centers), filas modelam o tempo de espera dos clientes. A visualização desses cenários em uma plataforma ajuda o aluno a conectar a estrutura abstrata com problemas do mundo real.
Integração da Fila com Outras Estruturas de Dados
A fila frequentemente trabalha em conjunto com outras estruturas. Por exemplo, em algoritmos de busca em largura (BFS), a fila é usada em conjunto com um conjunto de vértices visitados (geralmente implementado como um vetor booleano ou um hash set). Em algoritmos de cache, a fila FIFO é combinada com uma tabela hash para verificar rapidamente se um item está no cache. Em sistemas produtor-consumidor, a fila é compartilhada entre threads, e mecanismos de sincronização (como semáforos) são usados para evitar condições de corrida. Uma plataforma de visualização que permite ver a interação entre múltiplas estruturas de dados é ainda mais valiosa para entender sistemas complexos.
Considerações de Desempenho e Memória
Ao escolher uma implementação de fila, é importante considerar o contexto. Se o tamanho máximo da fila é conhecido e relativamente pequeno, a fila com vetor é a escolha ideal devido à sua eficiência. Se o tamanho é imprevisível ou muito grande, uma lista encadeada pode ser melhor, apesar do overhead de memória. Em sistemas embarcados ou de tempo real, onde a previsibilidade é crucial, a fila com vetor de tamanho fixo é frequentemente a única opção viável, pois evita alocações dinâmicas de memória. A plataforma de visualização pode incluir módulos que mostram estatísticas de desempenho (como número de operações por segundo, uso de memória) para ajudar o aluno a entender essas compensações.
Como a Plataforma de Visualização Acelera o Aprendizado
Estudos mostram que a aprendizagem baseada em visualização interativa pode reduzir o tempo necessário para dominar conceitos complexos em até 50%. Para filas, a visualização permite que o aluno forme um modelo mental preciso do comportamento da estrutura. Em vez de decorar regras abstratas, o aluno constrói intuição. A capacidade de "brincar" com a estrutura, testando diferentes sequências de operações, promove a descoberta ativa. Além disso, a plataforma pode oferecer feedback imediato: se o aluno tentar uma operação inválida (como dequeue em fila vazia), a plataforma mostra uma mensagem de erro e explica o motivo. Isso transforma o erro em uma oportunidade de aprendizado.
Conclusão: Domine Filas com Visualização
A fila implementada com lista sequencial (vetor) é uma das estruturas de dados mais importantes e elegantes da computação. Seu princípio FIFO é a base de inúmeros algoritmos e sistemas. Embora a implementação seja relativamente simples, os detalhes da fila circular e do gerenciamento de índices podem ser desafiadores para iniciantes. Uma plataforma de visualização de algoritmos e estruturas de dados é a ferramenta ideal para superar esses desafios. Ela transforma conceitos abstratos em imagens dinâmicas e interativas, permitindo que o aluno explore, experimente e, finalmente, compreenda profundamente o funcionamento interno da fila. Ao usar uma plataforma que oferece visualização passo a passo, destaque de código e simulação de aplicações reais, o estudante não apenas aprende a teoria, mas desenvolve a intuição prática necessária para aplicar filas em seus próprios projetos. Invista tempo em visualização e veja seu entendimento sobre estruturas de dados se transformar.
Próximos Passos no Aprendizado de Estruturas de Dados
Depois de dominar a fila com vetor, o próximo passo natural é estudar a fila com lista encadeada, comparando as diferenças de implementação e desempenho. Em seguida, explore estruturas relacionadas como deque (fila dupla), fila de prioridade (geralmente implementada com heap) e fila circular em mais detalhes. A plataforma de visualização ideal deve oferecer suporte para todas essas variações, permitindo que o aluno veja as semelhanças e diferenças entre elas. Além disso, pratique a implementação de algoritmos que usam filas, como BFS, e use a visualização para depurar e otimizar seu código. Lembre-se: a melhor maneira de aprender estruturas de dados é combinando estudo teórico com prática interativa e visual. Use a plataforma como seu laboratório pessoal de algoritmos.
树(Tree)
树是一种非线性的数据结构,它由一组按 分层顺序排列的节点组成。 其中一个节点被指定为根节点,其余的节点可以被划分为不相交的集合,这样每个集合都是根的一个子树。
树的最简单的形式是二叉树。 二叉树由一个根节点和左右子树组成,其中两个子树也是二叉树。每个节点都包含一个数据元素、一个指向左子树的左指针和一个指向右子树的右指针。根元素是由一个“根”指针指向的最顶部的节点。
二叉树 | 可视化完整可视化
1.1 O que é uma Estrutura de Dados? - Tutorial de Estruturas de Dados Visualize seu código com animações
O que são Árvores Binárias de Busca (BST) e Listas Ligadas?
No mundo da ciência da computação, estruturas de dados são a base para organizar e armazenar informações de forma eficiente. Duas das estruturas mais fundamentais e amplamente utilizadas são a Árvore Binária de Busca (Binary Search Tree - BST) e a Lista Ligada (Linked List). Enquanto a lista ligada oferece uma maneira simples e dinâmica de armazenar sequências de dados, a árvore binária de busca proporciona uma capacidade excepcional de pesquisa e ordenação. Compreender como essas estruturas funcionam, suas diferenças e aplicações é essencial para qualquer estudante de algoritmos e estruturas de dados.
Princípios Fundamentais da Lista Ligada (Linked List)
Uma lista ligada é uma estrutura de dados linear onde cada elemento, chamado de nó, contém dois campos: o dado em si e um ponteiro (ou referência) para o próximo nó da sequência. Diferente de um array tradicional, os elementos de uma lista ligada não estão armazenados em posições contíguas de memória. Isso significa que a lista pode crescer ou encolher dinamicamente, sem a necessidade de realocar todo o conjunto de dados. Existem variações como a lista ligada simples (cada nó aponta apenas para o próximo), a lista duplamente ligada (cada nó aponta para o próximo e para o anterior) e a lista circular (o último nó aponta para o primeiro).
Vantagens e Desvantagens da Lista Ligada
A principal vantagem da lista ligada é a inserção e remoção eficientes de elementos, especialmente no início ou no final da lista, desde que se tenha a referência adequada. Em contraste com arrays, essas operações não exigem o deslocamento de outros elementos. No entanto, uma desvantagem significativa é o acesso sequencial: para acessar o n-ésimo elemento, é necessário percorrer a lista a partir do primeiro nó, resultando em complexidade O(n) para operações de busca por índice. Além disso, o uso de ponteiros adicionais consome mais memória em comparação com arrays.
Princípios da Árvore Binária de Busca (Binary Search Tree)
Uma Árvore Binária de Busca (BST) é uma estrutura de dados hierárquica, não linear, composta por nós. Cada nó possui um valor e, no máximo, dois filhos: o filho à esquerda e o filho à direita. A propriedade fundamental que define uma BST é a seguinte: para qualquer nó, todos os valores na subárvore esquerda são menores que o valor do nó, e todos os valores na subárvore direita são maiores que o valor do nó. Essa propriedade é recursiva, ou seja, vale para cada subárvore.
Operações em uma Árvore Binária de Busca
As operações principais em uma BST são inserção, busca e remoção. A busca é extremamente eficiente: começando pela raiz, compara-se o valor desejado com o valor do nó atual. Se for menor, a busca continua na subárvore esquerda; se for maior, na subárvore direita. Esse processo reduz o espaço de busca pela metade a cada passo, resultando em complexidade O(log n) em média, onde n é o número de nós. A inserção segue a mesma lógica, encontrando a posição correta para o novo nó. A remoção é mais complexa, especialmente quando o nó a ser removido possui dois filhos, exigindo a substituição pelo nó sucessor ou predecessor em ordem.
Comparação: Árvore Binária de Busca vs Lista Ligada
A principal diferença entre uma BST e uma lista ligada está na eficiência das operações. Enquanto a lista ligada oferece inserção e remoção O(1) no início (com a referência correta) e busca O(n), a BST oferece busca, inserção e remoção O(log n) em média. No entanto, a BST é mais complexa de implementar e pode se degenerar em uma lista ligada (comportamento O(n)) se os dados inseridos estiverem ordenados (por exemplo, 1, 2, 3, 4...), a menos que seja utilizada uma variação balanceada, como a Árvore AVL ou Rubro-Negra. A lista ligada, por sua vez, é ideal para implementações de filas, pilhas e listas de tarefas onde a ordem sequencial é importante e as operações de inserção/remoção são frequentes.
Aplicações Práticas da Lista Ligada
Listas ligadas são amplamente utilizadas em sistemas onde a alocação dinâmica de memória é crucial. Exemplos incluem a implementação de filas e pilhas em sistemas operacionais, a representação de listas de reprodução em aplicativos de música (onde é fácil pular para a próxima ou anterior faixa), e a gestão de memória livre em alocadores dinâmicos. Em editores de texto, listas ligadas podem ser usadas para representar o buffer de texto, facilitando inserções e remoções de caracteres em qualquer posição.
Aplicações Práticas da Árvore Binária de Busca
BSTs são a espinha dorsal de muitos sistemas que exigem busca e ordenação eficientes. Bancos de dados utilizam variações de BSTs (como árvores B) para indexar registros, permitindo consultas rápidas por chave primária. Sistemas de arquivos usam BSTs para organizar diretórios e arquivos. Em compiladores, BSTs são usadas para construir tabelas de símbolos, onde é necessário buscar rapidamente por identificadores. Algoritmos de machine learning, como Random Forests, utilizam árvores de decisão, que são uma forma especializada de árvore binária. Além disso, BSTs são fundamentais para implementar mapas e conjuntos em linguagens de programação (como std::map em C++ ou TreeMap em Java).
O Papel da Visualização no Aprendizado de Estruturas de Dados
Para estudantes de algoritmos, entender conceitos abstratos como ponteiros, recursão e balanceamento de árvores pode ser desafiador. A visualização dinâmica é uma ferramenta poderosa que transforma conceitos teóricos em experiências visuais interativas. Um plataforma de visualização de estruturas de dados permite que o aluno veja exatamente como uma lista ligada é construída nó a nó, ou como uma BST realiza uma busca, inserção ou remoção passo a passo. Isso acelera o aprendizado e solidifica a compreensão dos mecanismos internos.
Funcionalidades de uma Plataforma de Visualização de Algoritmos
Uma plataforma eficaz de visualização de estruturas de dados deve oferecer diversas funcionalidades. Primeiramente, deve permitir a criação e manipulação visual de estruturas como listas ligadas, BSTs, árvores AVL e muito mais. O usuário deve poder adicionar, remover e buscar elementos com um simples clique, vendo a estrutura se modificar em tempo real. A plataforma deve exibir código-fonte (em linguagens como Python, Java ou C++) simultaneamente à visualização, destacando a linha de código sendo executada durante cada operação. Isso conecta a lógica do código ao comportamento visual. Além disso, a capacidade de controlar a velocidade da animação e de executar operações passo a passo é crucial para que o aluno possa analisar cada detalhe do processo.
Como a Visualização Ajuda no Estudo de Listas Ligadas
Ao visualizar uma lista ligada, o estudante pode ver claramente como os nós estão conectados por setas (representando os ponteiros). Inserir um novo nó no meio da lista mostra exatamente como os ponteiros do nó anterior e do novo nó são ajustados. Remover um nó revela como o ponteiro do nó anterior "pula" o nó removido, conectando-se ao próximo. A visualização ajuda a entender por que a inserção e remoção são O(1) se você já tem a referência, mas a busca é O(n), pois é necessário percorrer toda a estrutura para encontrar um elemento específico.
Como a Visualização Ajuda no Estudo de Árvores Binárias de Busca
Para BSTs, a visualização é ainda mais impactante. O estudante pode ver a propriedade fundamental da BST em ação: ao inserir o valor 5, ele vai para a esquerda da raiz (que é 10) e para a direita do nó 3. A busca pelo valor 7 mostra o algoritmo descartando metade da árvore a cada passo. A remoção de um nó com dois filhos (por exemplo, o nó 10) ilustra o conceito de sucessor em ordem (o menor nó da subárvore direita) ou predecessor. A visualização de árvores balanceadas, como AVL, mostra como as rotações (simples e duplas) restauram o balanceamento após uma inserção, mantendo a altura da árvore em O(log n).
Vantagens de Usar uma Plataforma de Visualização Interativa
O uso de uma plataforma de visualização traz múltiplos benefícios. Primeiro, a aprendizagem ativa: o aluno não é um mero espectador, mas pode interagir com a estrutura, testando casos extremos. Segundo, a correção de conceitos errôneos: ver visualmente como uma estrutura se comporta ajuda a corrigir interpretações equivocadas. Terceiro, a
Dicas para Estudantes Usarem a Plataforma de Visualização
Para maximizar o aprendizado, siga estas dicas ao usar uma plataforma de visualização de estruturas de dados. Comece com estruturas simples, como listas ligadas, antes de avançar para árvores e grafos. Execute cada operação passo a passo, observando as mudanças nos ponteiros e na estrutura. Tente prever o resultado de uma operação antes de executá-la. Por exemplo, antes de inserir um número em uma BST, pense em qual posição ele será colocado. Use a plataforma para testar casos extremos, como inserir elementos em ordem crescente em uma BST (para ver a degeneração em lista) ou remover a raiz de uma árvore. Sempre relacione a visualização com o código exibido na tela. Por fim, pratique a implementação das estruturas em uma linguagem de programação após a visualização, para consolidar o conhecimento.
Conclusão: A Importância da Visualização para o Domínio de Algoritmos
Dominar estruturas de dados como listas ligadas e árvores binárias de busca é um passo crucial na jornada de qualquer programador. A complexidade inerente a esses conceitos pode ser significativamente reduzida através do uso de ferramentas de visualização interativas. Uma plataforma dedicada não apenas torna o aprendizado mais envolvente, mas também fornece uma compreensão profunda e intuitiva do comportamento dinâmico dessas estruturas. Ao combinar a teoria com a prática visual, o estudante estará mais bem preparado para aplicar esses conceitos em projetos reais, resolver problemas complexos e ter sucesso em desafios técnicos. Invista tempo na exploração visual e veja seu entendimento sobre algoritmos e estruturas de dados se transformar.
图(Graphs)
图是一种非线性的数据结构,它是连接这些顶点的顶点(也称为节点)和边的集合。图通常被视为树结构的泛化,其中树节点之间不是纯粹的父子关系,节点之间的任何复杂关系。在树状结构中,节点可以有任意数量的子节点,但只有一个父节点,但是在图中却没有这些限制。
图的数据结构 | 可视化完整可视化
1.1 O que é uma Estrutura de Dados? - Tutorial de Estruturas de Dados Visualize seu código com animações
O que são Grafos na Estrutura de Dados?
Grafos são uma estrutura de dados não linear fundamental na ciência da computação. Diferente de listas ou árvores, um grafo é composto por um conjunto de vértices (também chamados de nós) e um conjunto de arestas que conectam pares de vértices. Essa estrutura permite representar relações complexas entre objetos, como redes de computadores, rotas de navegação, conexões em redes sociais e até mesmo dependências entre tarefas em um projeto. Para um estudante de algoritmos, entender a estrutura de armazenamento de grafos é o primeiro passo para dominar algoritmos avançados como busca em largura (BFS), busca em profundidade (DFS), Dijkstra e Floyd-Warshall.
Princípios Fundamentais da Estrutura de Armazenamento de Grafos
O armazenamento de um grafo em memória depende de como as conexões entre os vértices são representadas. Existem duas abordagens principais: a matriz de adjacência e a lista de adjacência. A matriz de adjacência utiliza uma tabela bidimensional onde cada célula indica se existe uma aresta entre dois vértices. Já a lista de adjacência armazena, para cada vértice, uma lista de todos os vértices aos quais ele está conectado. A escolha entre essas representações impacta diretamente a eficiência de operações como inserção, remoção e consulta de arestas, além do consumo de memória.
Matriz de Adjacência: Vantagens e Desvantagens
A matriz de adjacência é uma representação simples e intuitiva. Para um grafo com N vértices, criamos uma matriz N x N. Se o grafo não for ponderado, usamos valores booleanos (0 ou 1) para indicar a ausência ou presença de uma aresta. Em grafos ponderados, armazenamos o peso da aresta na célula correspondente. A principal vantagem é que verificar se dois vértices são adjacentes é uma operação de tempo constante O(1). No entanto, a desvantagem é o alto consumo de memória: para grafos densos (com muitas arestas), a matriz é eficiente, mas para grafos esparsos (poucas arestas), a maior parte da matriz fica vazia, desperdiçando espaço. Além disso, adicionar um novo vértice exige redimensionar toda a matriz.
Lista de Adjacência: Eficiência para Grafos Esparsos
A lista de adjacência é a representação mais comum em implementações reais de algoritmos. Para cada vértice, mantemos uma lista (geralmente implementada como um vetor dinâmico, lista encadeada ou conjunto) de seus vizinhos. Em grafos ponderados, cada elemento da lista armazena também o peso da aresta. A grande vantagem é a economia de memória em grafos esparsos, pois armazenamos apenas as arestas que realmente existem. A desvantagem é que verificar a existência de uma aresta específica pode levar tempo O(grau do vértice), embora isso possa ser otimizado com conjuntos hash. Para algoritmos que precisam percorrer todos os vizinhos de um vértice (como BFS e DFS), a lista de adjacência é naturalmente eficiente.
Aplicações Práticas dos Grafos no Mundo Real
Os grafos estão presentes em inúmeras aplicações do dia a dia. Em sistemas de GPS, os vértices representam cruzamentos e as arestas representam ruas, com pesos indicando distância ou tempo de viagem. Algoritmos como Dijkstra encontram a menor rota. Em redes sociais, os vértices são usuários e as arestas representam amizades ou seguidores, permitindo recomendar conexões ou detectar comunidades. Em sistemas de recomendação, grafos bipartidos conectam usuários a produtos. Em engenharia de software, grafos de dependência são usados para gerenciar pacotes e bibliotecas. Em biologia, grafos modelam interações entre proteínas. Para quem está aprendendo estrutura de dados, visualizar essas aplicações ajuda a conectar a teoria com a prática.
Grafos Direcionados vs. Não Direcionados
Uma classificação importante é entre grafos direcionados e não direcionados. Em grafos não direcionados, as arestas não têm direção: se existe uma aresta entre A e B, a conexão é bidirecional. Em grafos direcionados (digrafos), cada aresta tem uma direção, indo de um vértice de origem para um vértice de destino. A estrutura de armazenamento precisa refletir essa diferença. Na matriz de adjacência, grafos direcionados podem ter valores diferentes em [i][j] e [j][i]. Na lista de adjacência, para grafos direcionados, adicionamos o vértice destino apenas na lista do vértice origem. Para grafos não direcionados, adicionamos em ambas as listas. Compreender essa distinção é crucial para implementar algoritmos corretamente.
Grafos Ponderados e Não Ponderados
Outra variação fundamental são os grafos ponderados, onde cada aresta possui um peso numérico. Esses pesos podem representar distância, custo, capacidade ou qualquer métrica relevante. Na matriz de adjacência, os pesos substituem os valores booleanos. Na lista de adjacência, cada elemento da lista passa a ser uma estrutura contendo o vértice vizinho e o peso da aresta. Algoritmos como o de Dijkstra e Bellman-Ford dependem dessa representação para calcular caminhos mínimos. Grafos não ponderados são um caso especial onde todas as arestas têm peso unitário, simplificando a implementação de algoritmos de busca.
Como a Visualização Interativa Facilita o Aprendizado
Estudar grafos apenas com código e diagramas estáticos pode ser desafiador. Um plataforma de visualização de estruturas de dados permite que você veja exatamente como a matriz de adjacência e a lista de adjacência se comportam em tempo real. Você pode adicionar e remover vértices e arestas, e observar instantaneamente como a estrutura de armazenamento é atualizada. Isso transforma conceitos abstratos em experiências visuais concretas. Por exemplo, ao construir um grafo manualmente, você pode ver como a matriz de adjacência cresce quadraticamente com o número de vértices, enquanto a lista de adjacência cresce linearmente com o número de arestas.
Funcionalidades da Plataforma de Visualização
Nossa plataforma oferece um ambiente completo para explorar grafos. Você pode criar grafos direcionados ou não direcionados, ponderados ou não ponderados. A interface permite clicar para adicionar vértices e arrastar para criar arestas. O painel de controle mostra simultaneamente a representação gráfica do grafo e a estrutura de dados subjacente (matriz ou lista). Você pode alternar entre as duas representações para comparar o consumo de memória e a eficiência de operações. Além disso, a plataforma oferece animações passo a passo para algoritmos como BFS, DFS e Dijkstra, destacando como cada algoritmo percorre a estrutura de armazenamento.
Vantagens de Usar a Plataforma para Estudar Grafos
Uma das maiores dificuldades ao aprender grafos é entender a diferença entre a abstração matemática e a implementação computacional. A plataforma preenche essa lacuna. Você pode, por exemplo, criar um grafo com 100 vértices e comparar visualmente o espaço ocupado pela matriz de adjacência (10.000 células) versus a lista de adjacência (apenas as arestas existentes). Isso solidifica o entendimento sobre quando usar cada representação. Outra vantagem é a capacidade de depurar algoritmos: ao executar uma busca em profundidade, você vê exatamente quais vértices estão na pilha de chamadas e como a estrutura de armazenamento é consultada a cada passo.
Passo a Passo: Como Usar a Ferramenta de Visualização
Para começar, acesse a seção de grafos na plataforma. Você verá uma tela em branco e uma barra de ferramentas. Clique no botão "Adicionar Vértice" e clique na tela para posicionar os nós. Para criar uma aresta, selecione a ferramenta "Aresta" e clique em dois vértices consecutivos. Se o grafo for ponderado, uma janela solicitará o peso. No painel lateral, escolha entre visualizar a matriz de adjacência ou a lista de adjacência. Você pode exportar o grafo como código Python ou Java para usar em seus próprios projetos. A plataforma também oferece exemplos pré-carregados, como um grafo de rede social ou um mapa de rotas, para que você possa experimentar sem precisar criar tudo do zero.
Exemplo Prático: Comparando Matriz e Lista
Vamos criar um grafo simples com 5 vértices (A, B, C, D, E) e 4 arestas: A-B, A-C, B-D, C-E. Na matriz de adjacência, teremos uma tabela 5x5 com apenas 8 células preenchidas (considerando grafos não direcionados, cada aresta ocupa duas células). Na lista de adjacência, teremos: A: [B, C], B: [A, D], C: [A, E], D: [B], E: [C]. Visualmente, a lista ocupa muito menos espaço. Agora, adicione mais 10 arestas aleatórias. Observe como a matriz começa a ficar mais preenchida, enquanto a lista cresce proporcionalmente. Essa experiência visual ajuda a internalizar o conceito de densidade de grafos.
Algoritmos que Dependem da Estrutura de Armazenamento
A escolha entre matriz e lista de adjacência afeta diretamente o desempenho dos algoritmos. O algoritmo de Floyd-Warshall, que calcula caminhos mínimos entre todos os pares de vértices, naturalmente usa matriz de adjacência porque precisa acessar constantemente todas as combinações de vértices. Já algoritmos de busca como BFS e DFS são mais eficientes com lista de adjacência, pois eles percorrem os vizinhos de cada vértice. Algoritmos de ordenação topológica também se beneficiam da lista de adjacência. A plataforma permite que você execute esses algoritmos com ambas as representações e meça o tempo de execução, fornecendo uma compreensão prática da complexidade computacional.
Erros Comuns ao Aprender Grafos e Como Evitá-los
Um erro comum é confundir o número de vértices com o número de arestas ao analisar a complexidade de espaço. Outro erro é implementar a lista de adjacência usando arrays fixos, sem considerar a necessidade de redimensionamento dinâmico. Na visualização interativa, você pode cometer esses erros intencionalmente e ver as consequências em tempo real. Por exemplo, tente criar um grafo com 1000 vértices usando matriz de adjacência: a plataforma mostrará um alerta sobre o consumo excessivo de memória. Isso ensina na prática por que a lista de adjacência é preferível para grafos esparsos.
Integração com Outras Estruturas de Dados
Grafos frequentemente trabalham em conjunto com outras estruturas. Filas são usadas em BFS, pilhas em DFS, e heaps (filas de prioridade) no algoritmo de Dijkstra. Nossa plataforma permite visualizar essas estruturas auxiliares simultaneamente. Ao executar o algoritmo de Dijkstra, você vê o grafo sendo explorado, a fila de prioridade sendo atualizada e as distâncias sendo registradas em um array. Essa visão integrada mostra como diferentes estruturas de dados colaboram para resolver problemas complexos, algo que é difícil de entender apenas com código estático.
Casos de Uso Avançados: Grafos com Pesos Negativos e Ciclos
A plataforma também suporta casos especiais como arestas com pesos negativos e detecção de ciclos. Você pode criar um grafo com pesos negativos e executar o algoritmo de Bellman-Ford para ver como ele lida com essas situações. A visualização mostra claramente as iterações de relaxamento das arestas. Para detecção de ciclos em grafos direcionados, você pode usar o algoritmo baseado em DFS e observar como as cores dos vértices (branco, cinza, preto) indicam o progresso da busca. Esses recursos avançados são essenciais para estudantes que estão se preparando para competições de programação ou entrevistas técnicas.
Benefícios para Diferentes Perfis de Estudantes
Iniciantes se beneficiam da natureza visual e interativa, que reduz a abstração. Estudantes intermediários podem experimentar com diferentes configurações e ver o impacto no desempenho. Avançados podem usar a plataforma para prototipar rapidamente novos algoritmos e verificar seu comportamento em casos extremos. Professores podem usar a ferramenta em sala de aula para demonstrar conceitos em tempo real. A plataforma também gera código automaticamente a partir do grafo criado, facilitando a transição da visualização para a implementação prática.
Conclusão: Domine Grafos com Visualização Interativa
Dominar a estrutura de armazenamento de grafos é essencial para qualquer profissional de tecnologia que trabalhe com algoritmos complexos. A matriz de adjacência e a lista de adjacência são ferramentas poderosas, cada uma com seus pontos fortes e fracos. Através da visualização interativa, você não apenas aprende a teoria, mas desenvolve intuição prática sobre quando e como usar cada representação. Nossa plataforma foi projetada para acelerar esse aprendizado, transformando horas de estudo teórico em minutos de experimentação prática. Comece hoje mesmo a explorar o mundo dos grafos de uma forma que nenhum livro didático pode oferecer.
Próximos Passos no Aprendizado
Depois de dominar a estrutura de armazenamento, recomendamos explorar algoritmos de caminho mínimo, árvores geradoras mínimas (Kruskal e Prim), fluxo em redes (Ford-Fulkerson) e componentes fortemente conectados (algoritmo de Kosaraju). Todos esses tópicos estão disponíveis na plataforma com visualizações dedicadas. Acompanhe também nossa seção de desafios, onde você pode testar seus conhecimentos resolvendo problemas reais com a ajuda das ferramentas visuais. Lembre-se: a melhor maneira de aprender estruturas de dados é vendo-as em ação, e nossa plataforma foi criada exatamente para isso.
❗️ 注意:
请注意,与树不同,图没有任何根节点。相反,图中的每个节点都可以与图中的每一个节点进行连接。当两个节点通过一条边连接时,这两个节点被称为相邻节点。例如,在上图中,节点A有两个邻居:B和D。