 图码
图码2.1 顺序表
💡 让我们以一个现实世界的例子来描述计算机中的数组。
想象你在一个图书馆,这个图书馆里有很多书架,每个书架上都有一排排的书。每本书都有一个特定的位置,你可以通过书架的编号和书的位置找到它。
在计算机中,数组就像这个图书馆中的书架一样。它是一个存储相同类型数据元素的数据结构。每个数据元素都有一个唯一的索引或位置,通过这个索引,你可以访问或修改特定位置的数据元素。
在计算机内存中,数组的元素是依次存储的,就像书架上的书一样。这样,计算机可以通过简单的数学运算来计算出元素的内存地址,从而快速访问数组中的任何元素。
数组是一种有效存储和访问大量相似数据的方式,就像图书馆中的书架一样可以帮助你组织和查找大量书籍。
数组是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。
数组中的元素存储在连续的内存位置中,并由一个索引(也称为下标)引用。下标是一个用于标识数组中的元素位置的序号。
2.1.1 数组的声明
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cnElemType:是我们要存放的数组元素的类型,类型可以是int, float,,double, char,或者其他可以使用的数据类型;
name:是用来表示数组的,称为数组名;
size:当前数组可以存放的最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn❗ 注意:
在本文后续中提到的所有
索引或下标 都是从 0 开始计数。
位序或第几个 都是从 1 开始计数。
在C 或者 C++ 中,数组索引从零开始。
第一个元素存储在array[0]中,第二个元素存储在array[1]中,以此类推。
因此,最后一个元素,即第6个元素,被存储在array[5]中。
在内存中,数组将如图所示进行存储。注意,方括号内写的0、1、2、3、4、5是下标。
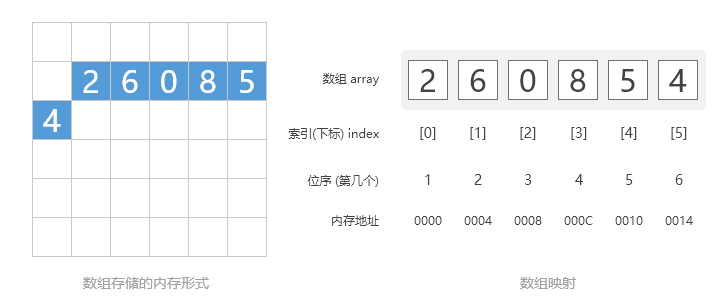
数组及内存结构
1 内存地址的计算
一个int类型的大小在内存中为4bytes。由于数组将其所有数据元素存储在连续的存储器位置中, 因此只需要知道数组首地址,即数组中第一个元素的地址就可以计算出该数组中其他元素的内存地址。
$$公式为:array[index] = base\_address + data\_type\_size \times index$$
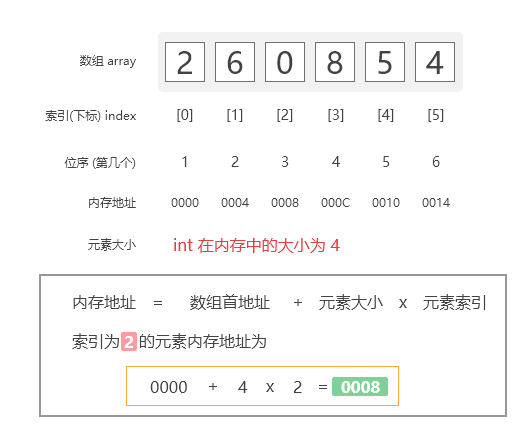
数组内存映射计算
由于数组元素是连续存储在内存的中的,所以我们可以很方便的访问任意一个元素。
就像你在图书馆的书架上查找一本特定的书时,如果你知道它的编号或位置,你可以直接走到该位置,而不必按顺序检查每本书。
在数组中访问元素是非常高效的,可以在$O(1)$时间内随机访问数组中的任意一个元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn在实际编码过程中,我们无需手动计算内存地址,因为每个元素占用大小相同的内存空间,数组元素的起始位置对于计算机也是已知的。 当我们在使用数组的下标来访问元素时,计算机可以通过上述的内存地址计算方法进行计算。
2 修改数组元素
需求:我们将index = 2即第 3 个元素的值修改为3。
操作步骤:
先找到$array[2]$的内存地址,使用上述公式:
$$\begin{split} array[2] &= base\_address + index \times data\_type\_size \\ \Rightarrow array[2] &= 0000 + 2 \times 4\\ \Rightarrow array[2] &= 0008 \end{split}$$
注意上面是计算内存地址,不是赋值
将内存地址为0xFFFF0008的值修改为3。
代码实现比较简单,计算机已自动帮助我们计算内存地址,我们只需提供对应的索引(index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn整个操作的时间复杂度为$O(1)$。
2.1.2 顺序表的介绍
💡 提示:
数组是一种数据结构,用于存储相同类型的元素的集合。
数组是一种顺序存储结构,元素在内存中按照一定的顺序依次存储。
那么数组和线性表的关系是什么呢?
线性表是一种数据结构,其中元素排列成一条线一样的顺序。
这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继。
线性表包括顺序表(数组实现)和链表等。
数组是一种实现线性表的方式之一。线性表可以通过数组来实现,也可以通过链表等其他结构来实现。
因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一。
通过数组实现的线性表称为顺序表。
1 顺序表的定义
线性表的顺序存储类型结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn定义了一个结构体SqList,包含两个成员变量:data和length。
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素。
2 顺序表的初始化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn这个函数的作用是将传入的顺序表 L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
2 在顺序表中插入元素
在顺序表中插入元素分为以下几种情况:
情况一:顺序表未满:插入在末尾
这种情况比较简单,我们只需要在当前最后一个元素的位置+1处直接赋值
例如:下面可视化窗口中的顺序表被声明为最大容量为10个元素,目前它存储了8个元素
步骤:
在末尾插入的位置为:9下标为:8 插入值5。
继续在末尾位置插入值:10
顺序表未满:插入末尾 | 可视化完整可视化
情况二:顺序表已满:不能再插入元素
上面可视化动画在插入了两个元素以后,顺序表总共有10个元素,那么我们将不能再向它添加元素,这种情况我们是不能进行插入的。
情况三:顺序表未满:插入在中间
如果想要在顺序表中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,给要插入的元素腾出位置,之后再把元素赋值给该索引。
步骤:
当前顺序表中已有8个元素,我们在下标为5位序为6处插入值10
注意代码中 i 为位序,不是下标
数组未满:插入在中间 | 可视化完整可视化
时间复杂度:
最好情况:如果插入操作发生在顺序表的末尾,并且顺序表有足够的空间,那么插入操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接在末尾添加元素不需要移动其他元素。
最坏情况:如果插入操作发生在顺序表的开头,需要将所有元素向后移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况: 平均情况下,需要移动插入位置后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
4 删除顺序表中的元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单。 我们只需要在当前存放元素的长度 -1 (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
步骤:
下面可视化面板中给出了最大容量为10的顺序表。
此时的顺序表内元素为{ 2, 6, 0, 8, 5, 4, 9, 8 },我们把下标为:3,位序为:4的元素删除掉。
❗ 注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它。
删除顺序表元素 | 可视化完整可视化
时间复杂度:
最好情况:如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素。
最差情况:如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况:平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序。
查找顺序表中的值 | 可视化完整可视化
2.1 順序リスト詳解 - 線形リストチュートリアル アニメーションでコードを可視化しよう

【データ構造とアルゴリズム】線形リスト(配列)を完全マスター!初心者向け徹底解説
こんにちは!データ構造とアルゴリズムの学習を始めたばかりの方、あるいは「配列(はいれつ)って結局何が便利なの?」と感じている方に向けて、この記事では線形リストの中でも最も基本的な「順序表(配列)」について、初心者にも分かりやすく解説します。特に、ビジュアライゼーション(可視化)学習ツールを活用することで、抽象的な概念を直感的に理解する方法もご紹介します。
1. 線形表(Linear List)とは?
線形表(リニアリスト)は、データを一列に並べて格納する最もシンプルなデータ構造です。イメージとしては、本棚に本を隙間なく並べるようなものです。線形表には大きく分けて「順序表(配列)」と「連結リスト」の2種類がありますが、この記事ではまず順序表に焦点を当てます。
順序表は、メモリ上で連続した領域にデータを格納します。つまり、データは「隣り合った部屋」に順番に収められているイメージです。この特徴により、インデックス(添え字)を使った高速なアクセスが可能になります。
2. 順序表(配列)の仕組みと基本原理
順序表は、固定長の配列として実装されることが多いです。たとえば、整数を5つ格納できる配列を宣言すると、メモリ上に5つの連続したブロックが確保されます。
各ブロックには0から始まるインデックスが割り振られており、arr[0]、arr[1]、arr[2]…のようにアクセスします。このインデックスを使って、O(1)(定数時間)で任意の要素を読み書きできるのが最大の強みです。
ただし、要素の挿入や削除には注意が必要です。たとえば、先頭に新しいデータを挿入する場合、後続の要素をすべて1つずつ後ろにずらす必要があるため、平均してO(n)の時間がかかります。これが順序表のトレードオフです。
3. 順序表の特徴:メリットとデメリット
メリット
- 高速なランダムアクセス:インデックスを指定すれば、どの要素にも一瞬でアクセスできます。
- メモリ効率が良い:連結リストのようにポインタを格納するための余分なメモリが不要です。
- キャッシュに優しい:データが連続しているため、CPUキャッシュのヒット率が高くなります。
デメリット
- 挿入・削除が遅い:特に先頭や中央への挿入・削除では、多くの要素を移動させる必要があります。
- サイズが固定(または拡張にコストがかかる):静的な配列は宣言時にサイズが決まります。動的に拡張する場合は、新しい配列を作成してコピーする必要があります。
4. 順序表の代表的な操作と時間計算量
ここでは、順序表でよく行われる操作とその計算量をまとめます。
| 操作 | 時間計算量 | 説明 |
|---|---|---|
| アクセス(arr[i]) | O(1) | インデックス指定で即座に取得 |
| 先頭への挿入 | O(n) | 全要素を1つずつ後ろにずらす |
| 末尾への挿入 | O(1)(平均) | 空き容量があればそのまま追加 |
| 先頭の削除 | O(n) | 全要素を1つずつ前にずらす |
| 末尾の削除 | O(1) | 最後の要素を削除するだけ |
| 値の検索 | O(n) | 線形探索が必要(ソート済みなら二分探索でO(log n)) |
このように、「読み取りが多いが書き込み(挿入・削除)が少ない」というシチュエーションで順序表は真価を発揮します。
5. 順序表の応用シーン
順序表は、あらゆるプログラムの基礎として使われています。具体的な応用例をいくつか挙げます。
- 静的データの管理:曜日や月の名前、固定の設定値など、変更が少ないデータ。
- バッファ(一時記憶):画像処理や音声処理で、連続したデータを一時的に格納するリングバッファなど。
- スタックやキューの実装:配列を使ってスタック(LIFO)やキュー(FIFO)を効率的に実装できます。
- ソートアルゴリズムの対象:クイックソートやマージソートなど、多くのソートは配列を前提としています。
- 動的計画法(DP):DPテーブルは多次元配列として表現されることが多いです。
これらの応用例からも分かるように、順序表はアルゴリズム学習の第一歩であり、同時に実務でも頻繁に登場する重要なデータ構造です。
6. データ構造とアルゴリズムの可視化学習プラットフォームのご紹介
さて、ここまで順序表の理論を説明してきましたが、「実際に動きを見ながら理解したい」という方に最適なのが、データ構造可視化学習プラットフォームです。私たちのプラットフォームは、以下のような特徴を持っています。
- インタラクティブなアニメーション:配列への挿入や削除の際に、要素がずれていく様子をアニメーションで確認できます。
- コードと連動した可視化:PythonやJavaScriptのコードを実行すると、その動作がリアルタイムで図示されます。
- ステップ実行機能:1行ずつコードを実行し、そのたびにデータ構造がどう変化するかを追跡できます。
- 練習問題と即時フィードバック:順序表に関するクイズやコーディング課題を解くと、可視化付きで解説が表示されます。
このプラットフォームを使えば、「なぜ挿入にO(n)かかるのか」が目で見てわかるため、暗記ではなく本質的な理解が得られます。
7. 可視化プラットフォームの具体的な使い方(順序表の場合)
ここでは、実際に当プラットフォームで順序表を学習する流れを簡単にご紹介します。
- トップページから「線形表 > 順序表」を選択:すると、空の配列が表示された画面に遷移します。
- サンプルコードを読み込む:デフォルトで用意された「要素の追加」「挿入」「削除」のコードをワンクリックでセットできます。
- 実行ボタンを押す:コードが1行ずつハイライトされ、それに合わせて配列の要素が動きます。
- 自分でコードを書いてみる:エディタに自由にコードを入力し、実行ボタンで可視化。たとえば「先頭に100を挿入」というコードを書けば、全要素が後ろにずれるアニメーションが再生されます。
- ステップ実行で細かく確認:特に挿入や削除の内部処理を追いたい場合は、ステップ実行モードで1行ずつ進められます。
このように、「見て、触って、コードを書く」という3つのアクションを通じて、自然と順序表の動作原理が身につきます。
8. なぜ可視化が学習に効果的なのか?
データ構造とアルゴリズムは、抽象的な概念です。特に初心者の場合、「メモリ上でデータがどう動くのか」をイメージするのが難しいと感じることが多いでしょう。可視化ツールを使うと、以下のようなメリットがあります。
- 直感的な理解:テキストや数式だけでは伝わりにくい「ずらす」「連結する」といった動作が、目で見てわかります。
- 誤解の防止:「配列の挿入はO(1)だと思っていた」という誤解が、実際のアニメーションを見ることで解消されます。
- 記憶の定着:視覚と聴覚(操作音やナレーション)を組み合わせることで、記憶に残りやすくなります。
- 自己ペースで学習可能:何度でも繰り返しアニメーションを再生でき、自分のタイミングで停止・確認できます。
当プラットフォームは、これらの効果を最大化するために設計されています。特に、「初学者がつまずきやすいポイント」を重点的に可視化しているため、独学でもスムーズに理解を深められます。
9. 順序表を学ぶ際の注意点とよくある質問
最後に、順序表を学習する上でよくある疑問や注意点をまとめます。
- Q: 配列サイズを動的に変えたい場合はどうすればいい?
A: 多くの言語では「動的配列(ArrayListやvector)」が用意されています。内部では、容量がいっぱいになると新しい大きな配列を作成し、全要素をコピーします(このコピーにO(n)かかるため、償却計算量はO(1)になります)。 - Q: 連結リストとどちらを選ぶべき?
A: アクセス頻度が高く、挿入削除が少ないなら順序表。逆に挿入削除が頻繁で、アクセスは少ないなら連結リストが適しています。 - Q: 多次元配列も順序表の一種ですか?
A: はい。2次元配列もメモリ上では1次元の連続領域として格納されることが多く、順序表の応用です。
これらの疑問も、可視化プラットフォーム上で実際に動かしながら確認すると、より深く理解できます。
10. まとめ:順序表マスターして次のステップへ
この記事では、線形表の一種である順序表(配列)について、原理・特徴・応用・学習方法を詳しく解説しました。順序表は、データ構造とアルゴリズムの基礎中の基礎であり、これをしっかり理解することで、スタック、キュー、ハッシュテーブル、グラフなど、より高度な構造への理解が格段にスムーズになります。
そして、可視化学習プラットフォームを活用すれば、抽象的な概念も「見える化」されて、学習効率が飛躍的に向上します。ぜひ、当プラットフォームで実際に手を動かしながら、順序表の動作を体感してみてください。
次のステップとしては、「連結リスト」や「スタックとキュー」の可視化にも挑戦してみましょう。当プラットフォームでは、すべての基本データ構造に対応したインタラクティブな教材を用意しています。
それでは、楽しいアルゴリズム学習ライフを!
関連キーワード:データ構造 可視化, アルゴリズム 学習, 配列 仕組み, 線形リスト, 順序表 挿入 削除, 初心者 プロラミング, 動的配列, 計算量 O(1) O(n)
时间复杂度:
最好情况:要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为$O(1)$,即常数时间复杂度。
最坏情况:要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中。在这种情况下,时间复杂度为$O(n)$,其中$n$是顺序表中元素的个数。
平均情况:平均情况的时间复杂度通常是$O(\frac n 2)$,因为平均而言,我们可以认为要查找的元素在顺序表的中间位置。但是在大$O$表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是$O(n)$。
2.1.3 顺序表数组实现的优点与缺点
1 优点
随机访问速度快:由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 $O(1)$。这使得数组在需要频繁随机访问元素的情况下非常高效。
节约空间:相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间。
缓存友好:由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势。
2 缺点
固定大小:数组的大小是固定的,一旦创建后就不能动态改变。如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销。
插入和删除操作效率低:在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 $O(n)$。这使得数组在频繁插入和删除操作的场景下效率较低。
不适合存储变长数据:由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求。