 图码
图码1.1 什么是数据结构?
在计算机世界中,数据结构代表了计算机在内存中存储和组织数据的独特方法。通过不同的排列和组合方式,可以使用户高效且适当的方式访问和使用他们所需的数据。
数据结构的存在使用户能够方便地按需访问和操作他们的数据,有助于以高效而紧凑的方式组织和检索各种类型的数据。
对于接触过计算机基础知识的读者而言,对于下面这个公式应该不会陌生:
算法 + 数据结构 = 程序
提出这一公式并以此作为其一本专著书名Algorithms + Data Structures = Programs的瑞士计算机科学家Niklaus Wirth于1984年获得了图灵奖。
程序(Program)是由数据结构(Data Structure)和算法(Algorithm)组成,这意味着的程序的好和快是直接由程序所采用的数据结构和算法决定的。
❗️ 注意
本章节仅作介绍,涉及到的具体数据结构和算法会在后续章节中详细讲解。
数据结构分类
数据也可以被细分为以下两种类型:
线性结构
非线性结构
线性结构
数据元素按顺序或者线性排列
除了第一个元素和最后一个元素之外,剩余每个元素都有前一个和下一个相邻元素。
有两种技术可以在内存中表示这种线性结构。
数组:存储在连续内存位置的相同数据类型的项目的集合。
链表:通过使用指针或链接的概念来表示的所有元素之间的线性关系。
常见的线性结构例子有:
数组:存储在连续内存位置的元素的集合。
链表:节点的集合,每个节点包含一个元素和对下一个节点的引用。
堆栈:具有后进先出 (LIFO)顺序的元素集合。
队列:具有先进先出 (FIFO)顺序的元素集合。
非线性结构
该结构主要用于表示包含各种元素之间的层次关系的数据。
常见的非线性结构例子有:
图:顶点(节点)和表示顶点之间关系的边的集合。图用于建模和分析网络,例如社交网络或交通网络。
树:树的结构呈现出一个类似根和分支的形状,其中有一个根节点,从根节点出发,分成多个子节点,每个子节点可以又分为更多的子节点,依此类推
各种数据结构的简单介绍
数组(Arrays)
数组是相似数据元素的集合。这些数据元素具有相同的数据类型。
数组的元素存储在连续的内存位置中,并由索引(也称为下标)来指向数据。
在C语言中,数组声明使用以下格式:
- 1
- 2
- 3
ElemType name[size];
//例如
char array[10] = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'
// 完整代码:https://totuma.cn上面的语句声明了一个包含10个元素的数组标记。 在C中,数组索引从零开始。这意味着数组标记将总共包含10个元素。
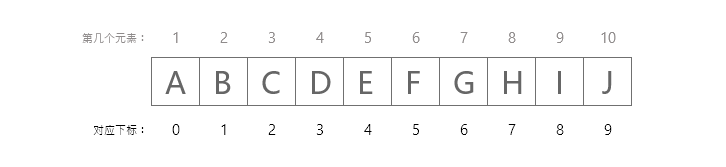
数组下标对应位序
第一个元素将存储在array[0]中,第二个元素将存储在array[1]中,等等。因此,最后一个元素,即第10个元素,将被存储在array[9]中。 在计算机中存储如下图所示。
当我们想要存储大量相同类型的数据时,通常会使用数组。当然,数组也有一些限制,比如:
数组的大小是固定的。
数据元素存储在连续的内存位置中,但是内存中剩余的大小可能不足以容纳当前数组。
元素的插入和删除会很麻烦。
链表(Linked Lists)
链表是一种非常灵活的动态数据结构,其中元素(称为节点)形成一个顺序列表。 与静态数组相比,我们不需要担心链表中将存储多少个元素。这个特性使我们能够编写需要较少维护的健壮程序。在链表中,每个节点都有data域和next指针域:
data域:存放该节点或与该节点对应的任何其他数据的值。
next指针域:指向列表中的下一个节点的指针或链接。
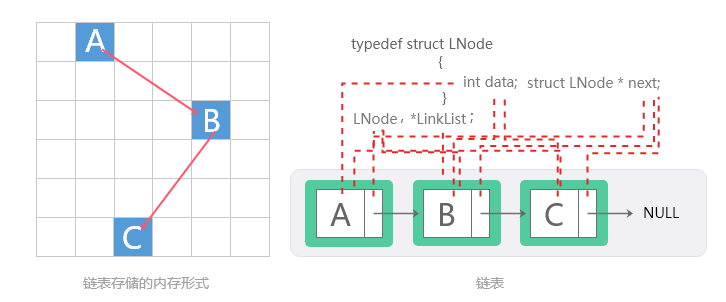
链表结构
列表中的最后一个节点包含一个NULL指针,表明它是当前列表的尾。由于节点的内存是在添加到列表中时动态分配的,因此可以添加到列表中的节点总数仅受可用内存量的限制。具体结构可见下图:
栈(Stacks)
栈是一种线性数据结构, 其中元素的插入和删除只在一端完成,这被称为栈顶。 栈被称为先入后出(LIFO)结构,因为添加到堆栈中的最后一个元素是从堆栈中删除的第一个元素。在计算机的内存中,堆栈可以使用数组或链表来实现。
下面可视化操作显示了一个栈的数组实现。每个栈都有一个与其关联的变量top,用于指向最上面的元素。这是将从中添加或删除元素的位置。
栈支持push 入栈和pop 出栈 操作,push 就是在从栈顶中压入一个元素,pop 就是在栈顶中弹出一个元素,即增和删。
💡 提示
点击下方的入栈、出栈按钮。可以明了的理解到什么是先入后出。
栈 | 可视化完整可视化
1.1 データ構造とは? - データ構造チュートリアル アニメーションでコードを可視化しよう

データ構造とアルゴリズムの可視化学習:線形表・スタック・順序表を徹底解説
データ構造とアルゴリズムの学習は、プログラミングの基礎を築く上で非常に重要です。しかし、抽象的な概念をテキストだけで理解するのは難しいと感じる学習者も多いでしょう。特に「線形表」「スタック」「順序表」といった基本的なデータ構造は、その動作原理を視覚的に捉えることで、格段に理解が深まります。
本記事では、データ構造とアルゴリズムの可視化学習プラットフォームを活用しながら、線形表、スタック、順序表について詳しく解説します。このプラットフォームは、アニメーションやインタラクティブな操作を通じて、データの動きを直感的に理解できるように設計されています。初心者の方でも安心して学習を進められるよう、基礎から応用まで丁寧に説明していきます。
線形表(Linear List)とは?基本概念と特徴
線形表は、データを一列に並べて格納する最も基本的なデータ構造の一つです。要素間には順序関係があり、各要素は前後の要素と明確な位置関係を持っています。日常生活で例えるなら、買い物リストや図書館の本の並び順などが線形表に該当します。
線形表の最大の特徴は、要素が直線的に配置されている点です。各要素はインデックス(添え字)によって識別され、先頭から末尾まで順番にアクセスできます。このシンプルな構造が、多くのアルゴリズムの基盤となっています。
線形表には主に二つの実装方法があります。一つは「配列(順序表)」を用いる方法で、もう一つは「連結リスト」を用いる方法です。配列ベースの実装では、メモリ上に連続した領域を確保し、インデックスによる高速なランダムアクセスが可能です。一方、連結リストでは、各要素が次の要素へのポインタを持ち、動的なメモリ管理が容易です。
可視化学習プラットフォームでは、この線形表の動作をアニメーションで確認できます。要素の追加や削除、検索といった操作がどのように行われるかを、実際にマウスで操作しながら学べるため、抽象的な概念が具体的にイメージできるようになります。
順序表(Sequential List)の詳細:配列による実装
順序表は、線形表を配列(Array)を使って実装したデータ構造です。メモリ上に連続した領域を確保し、各要素を順番に格納します。インデックスが0から始まる点が一般的で、C言語やJava、Pythonなど多くのプログラミング言語で標準的に使用されています。
順序表の最大の利点は、ランダムアクセスが高速であることです。インデックスを指定すれば、どの位置の要素でも一定時間(O(1))で取得できます。例えば、配列の3番目の要素にアクセスする場合、先頭から数える必要はなく、直接そのメモリアドレスを計算してアクセスします。
しかし、順序表には欠点もあります。要素の挿入や削除を行う際、後続の要素を全て移動させる必要があるため、最悪の場合O(n)の時間がかかります。例えば、先頭に新しい要素を挿入する場合、既存の全要素を一つずつ後ろにずらさなければなりません。この動作は、要素数が多くなるほど顕なパフォーマンス低下を引き起こします。
可視化プラットフォームでは、この「要素の移動」がどのように発生するかを、カラフルなアニメーションで確認できます。要素がスライドしていく様子を目で追うことで、時間計算量の概念も自然と身につきます。また、メモリの確保や解放のタイミングも視覚的に表示されるため、メモリ管理の理解にも役立ちます。
スタック(Stack)の原理:LIFOの動作メカニズム
スタックは、データの出し入れに特別な制約を持つ線形表の一種です。その動作原理は「Last In, First Out(LIFO)」、つまり「最後に入れたものが最初に出てくる」というルールに基づいています。これは、食堂に積み重ねられたお皿をイメージすると分かりやすいでしょう。最後に積んだお皿が最初に取り出されます。
スタックで定義されている基本的な操作は次の三つです。データを追加する「プッシュ(push)」、データを取り出す「ポップ(pop)」、そして一番上のデータを確認する「ピーク(peek)」または「トップ(top)」です。これらの操作は全て、スタックの最上部(トップ)でのみ行われます。
スタックは、コンピュータサイエンスの様々な場面で活用されています。代表的な応用例としては、関数呼び出しの管理があります。プログラムが関数を呼び出すたびに、その関数のローカル変数や戻り先アドレスがスタックにプッシュされ、関数から戻る際にポップされます。また、ブラウザの「戻る」ボタンや、テキストエディタの「アンドゥ(元に戻す)」機能もスタックの仕組みを利用しています。
可視化学習プラットフォームでは、スタックのプッシュとポップの動作をリアルタイムで観察できます。データが積み上がっていく様子や、取り出される順番をアニメーションで確認することで、LIFOの概念が直感的に理解できるでしょう。また、スタックのサイズが動的に変化する様子も視覚化されるため、メモリ使用量の変化も把握できます。
スタックの実装方法と時間計算量
スタックは、配列(順序表)または連結リストのどちらでも実装可能です。配列を用いた実装では、トップの位置を示す変数(通常はインデックス)を用意し、プッシュ時にはトップをインクリメントしてデータを格納、ポップ時にはトップをデクリメントしてデータを取得します。
配列ベースのスタックでは、プッシュとポップの操作はどちらもO(1)の時間計算量で実行できます。ただし、配列のサイズを超えるデータを格納しようとすると「スタックオーバーフロー」が発生するため、事前に十分なサイズを確保するか、動的に配列を拡張する必要があります。
一方、連結リストを用いた実装では、メモリを動的に確保するため、理論上はスタックのサイズに制限がありません。プッシュ操作はリストの先頭に新しいノードを追加するだけなのでO(1)、ポップ操作も先頭ノードを削除するだけなのでO(1)です。ただし、各ノードにポインタ用のメモリが追加で必要になるというデメリットがあります。
可視化プラットフォームでは、配列実装と連結リスト実装の両方を切り替えて比較できます。それぞれの実装におけるメモリの使用状況や、操作ごとの内部処理の違いを視覚的に確認できるため、抽象的なトレードオフの概念が具体的に理解できます。
線形表とスタックの応用シーン
線形表とスタックは、実践的なプログラミングにおいて非常に多くの場面で活用されています。ここでは代表的な応用例をいくつか紹介します。
線形表は、データベースのレコード管理や、グラフィックス処理における頂点リスト、テキストエディタの文字列管理など、幅広い用途で使用されています。特に、順序表(配列)は、画像処理や数値計算などの分野で、多次元データの格納に欠かせません。例えば、デジタル画像はピクセルデータを二次元配列として管理しており、各画素への高速アクセスを実現しています。
スタックは、構文解析や式の評価にも不可欠です。例えば、電卓アプリで「(3+4)×5」のような数式を計算する際、演算子とオペランドをスタックで管理することで、正しい計算順序を実現しています。また、深さ優先探索(DFS)アルゴリズムでも、探索経路をスタックに記録することで、効率的な探索を可能にしています。
さらに、スタックは再帰処理の内部実装にも使われています。再帰関数を呼び出すたびに、その呼び出し情報がシステムスタックにプッシュされ、関数から戻る際にポップされます。この仕組みを理解することで、再帰アルゴリズムの動作をより深く理解できるようになります。
可視化プラットフォームでは、これらの応用例を実際にシミュレーションできます。例えば、数式計算の過程をステップバイステップで表示したり、深さ優先探索が迷路を解く様子をアニメーションで確認したりできます。理論と実践を結びつけることで、学習効果が大幅に向上します。
可視化学習プラットフォームの機能と利点
データ構造とアルゴリズムの可視化学習プラットフォームは、従来のテキストベースの学習とは一線を画す、多くの優れた機能を提供しています。ここでは、その主要な機能と学習上の利点について詳しく説明します。
第一の機能は、インタラクティブなアニメーション表示です。データの追加や削除、検索といった操作が、実際に画面上で動くアニメーションとして表現されます。例えば、順序表に要素を挿入する際、後続の要素が一つずつ移動する様子を目で追うことができます。この視覚的な体験により、時間計算量の概念が直感的に理解できるようになります。
第二の機能は、コードと動作の連動表示です。プラットフォーム上で実際のプログラムコード(C言語、Java、Pythonなど)を表示しながら、そのコードが実行されるたびにデータ構造の状態が変化します。コードの一行一行がデータにどのような影響を与えるのかを、リアルタイムで確認できます。これにより、抽象的なコードと具体的なデータ構造の対応関係が明確になります。
第三の機能は、ステップ実行とブレークポイントです。学習者は、任意の操作を一時停止したり、一ステップずつ進めたりできます。複雑なアルゴリズムの場合、一度に全ての動作を理解するのは困難ですが、ステップ実行を利用することで、一つ一つの処理をじっくり観察できます。また、特定の状態で停止するブレークポイントを設定すれば、注目したい箇所を重点的に学習できます。
第四の機能は、パラメータの動的変更です。データのサイズや操作の種類、実装方法(配列か連結リトか)などを自由に変更しながら、その影響を観察できます。例えば、順序表の要素数を10から1000に増やした場合、挿入操作にかかる時間がどのように変化するかを、実際のアニメーション速度の変化として体感できます。
これらの機能により、学習者は単に知識を暗記するのではなく、データ構造の本質的な仕組みを理解できるようになります。また、自分のペースで学習を進められるため、理解が不十分な箇所は何度でも繰り返し確認できます。
プラットフォームの効果的な使用方法
可視化学習プラットフォームを最大限に活用するためには、いくつかの効果的な使用方法があります。ここでは、初心者から上級者まで、それぞれのレベルに応じた学習アプローチを紹介します。
初心者の方は、まず基本的な操作から始めることをお勧めします。例えば、順序表であれば、要素の追加と削除を繰り返し実行しながら、インデックスの変化や要素の移動を観察してください。スタックであれば、プッシュとポップを交互に行い、LIFOの動作原理を体感しましょう。最初はゆっくりと、一つの操作に集中することが大切です。
次に、複数の操作を組み合わせたシナリオを試してみましょう。例えば、順序表で「先頭に要素を追加→末尾の要素を削除→特定の位置に要素を挿入」といった一連の流れを実行します。このとき、各操作がデータ構造にどのような影響を与えるか、また時間計算量がどのように変化するかを観察してください。
中級者の方は、異なる実装方法の比較に挑戦してみてください。同じ線形表でも、配列実装と連結リスト実装では、操作ごとのパフォーマンスが異なります。プラットフォーム上で両方を切り替えながら、同じ操作を実行し、アニメーションの速度やメモリ使用量の違いを確認しましょう。この比較体験が、データ構造のトレードオフを理解する上で非常に役立ちます。
上級者の方は、実際のアルゴリズムと組み合わせた学習が効果的です。例えば、スタックを使って深さ優先探索を実装する場合、プラットフォーム上で探索の過程を可視化しながら、スタックの状態変化を観察します。また、順序表を使ってソートアルゴリズム(バブルソートやクイックソートなど)を実行する場合も、要素の比較と交換の様子をアニメーションで確認できます。
さらに、プラットフォームには学習の捗を記録する機能や、理解度をチェックするクイズ機能も備わっています。定期的にクイズに挑戦することで、自分の理解度を客観的に評価し、弱点を把握できます。また、他の学習者と結果を共有できるコミュニティ機能を活用すれば、モチベーションの維持にもつながります。
学習上の注意点とよくある誤解
可視化学習プラットフォームを使用する際に、いくつかの注意点とよくある誤解について理解しておくことが重要です。これらを事前に把握しておくことで、より効率的に学習を進められます。
一つ目の注意点は、可視化はあくまで理解を助けるツールであり、それ自体が目的ではないということです。アニメーションを見るだけで満足してしまうと、実際のプログラミングで応用する力が身につきません。可視化で概念を理解した後は、必ず自分でコードを書いて実装してみることをお勧めします。プラットフォーム上で表示されるコードを参考に、自分の手でタイピングすることで、理解が確実なものになります。
二つ目の注意点は、時間計算量の概念を過信しないことです。可視化プラッフォームでは、操作の速度がアニメーションの速度として表現されますが、これは実際のコンピュータ上の実行速度とは異なります。あくまで相対的な比較として捉え、実際のパフォーマンスは別途ベンチマークテストなどで確認する必要があります。
よくある誤解として、スタックとキューを混同してしまうケースがあります。スタックはLIFO(後入れ先出し)ですが、キューはFIFO(先入れ先出し)です。可視化プラットフォームでは、両者を並べて比較表示できる機能があるため、それぞれの動作の違いを明確に理解できます。また、順序表と連結リストの違いについても、可視化を通じて明確に区別できるようになります。
もう一つの誤解は、すべてのデータ構造に万能な実装方法があると思い込むことです。実際には、使用する状況や要件によって、最適なデータ構造や実装方法は異なります。可視化プラットフォームで様々なケースを試すことで、どのような状況でどのデータ構造を選ぶべきか、という判断力が養われます。
まとめ:可視化学習でデータ構造をマスターしよう
本記事では、データ構造とアルゴリズムの可視化学習プラットフォームを活用しながら、線形表、順序表、スタックについて詳しく解説してきました。これらの基本的なデータ構造は、コンピュータサイエンスのあらゆる分野で応用される重要な概念です。
線形表はデータを一列に並べる基本構造であり、順序表はその配列実装、スタックはLIFOの制約を持つ特殊な線形表です。それぞれに特徴や得意な操作、苦手な操作があり、それらを理解することが効率的なプログラミングにつながります。
可視化学習プラットフォームの最大の強みは、抽象的な概念を視覚的かつインタラクティブに体験できる点です。アニメーションによる動作の確認、コードと状態の連動表示、ステップ実行による詳細な観察、パラメータ変更による影響の確認など、多彩な機能が学習を支援します。これらの機能を効果的に活用することで、従来のテキスト学習では得られなかった深い理解が得られるでしょう。
データ構造の学習は、プログラマとしての成長に欠かせないステップです。可視化学習プラットフォームを活用して、楽しみながら確実にスキルを向上させてください。ぜひ今日から、実際にプラットフォームにアクセスして、線形表やスタックのアニメーションを操作してみてください。新しい発見と理解が待っています。
队列(Queues)
队列是一种先进先出(FIFO)的数据结构,其中首先插入的元素是第一个要取出的元素。 队列中的元素在队尾添加,然后在队头删除。 与栈一样,队列也可以通过使用数组或链表来实现。 每个队列都有队头和队尾,分别指向可以进行删除和插入的位置。
队列 | 可视化完整可视化
1.1 データ構造とは? - データ構造チュートリアル アニメーションでコードを可視化しよう
キュー(待ち行列)とは?順序表(配列)を用いた基本構造を徹底解説
データ構造とアルゴリズムの学習において、「キュー(Queue)」は最も基本的かつ重要な概念の一つです。キューは「先入れ先出し(FIFO: First-In-First-Out)」の原則に従うデータ構造であり、日常生活における「列(待ち行列)」と同じ仕組みを持っています。本記事では、キューを順序表(配列)を用いて実装する方法、その動作原理、特徴、そして実際の応用シーンについて、初心者にもわかりやすく解説します。
キュー(Queue)の基本原理:FIFOとは
キューは、最初に追加された要素が最初に取り出されるデータ構造です。これを「先入れ先出し(FIFO)」と呼びます。例えば、スーパーマーケットのレジに並ぶ人々を想像してください。一番最初に並んだ人が最初に会計を済ませて列を離れます。これがキューの基本的な動作です。
キューに対して行う主な操作は以下の3つです。
エンキュー(enqueue):キューの末尾に新しい要素を追加する操作です。これは列の最後尾に人が並ぶことに相当します。
デキュー(dequeue):キューの先頭から要素を取り出す操作です。これは列の先頭にいた人が会計を終えて去ることに相当します。
フロント(front):キューの先頭にある要素を参照する操作です。要素は削除されず、値を見るだけです。
順序表(配列)を用いたキューの実装方法
順序表、すなわち配列(Array)を使用してキューを実装する方法は、プログラミング学習の初期段階で非常に重要です。配列はメモリ上に連続してデータを格納するため、インデックスを使って高速にアクセスできるという利点があります。
配列を用いたキューの基本的な実装では、以下の変数を管理します。
配列(array):実際にデータを格納するための固定長の配列です。
フロント(front):キューの先頭要素のインデックスを指します。
リア(rear):キューの末尾要素のインデックスを指します。
サイズ(size):現在キューに格納されている要素の数です。
エンキュー操作では、リアの位置を1つ進めて、その位置に新しい要素を格納します。デキュー操作では、フロントの位置を1つ進めて、元のフロント位置の要素を論理的に削除します。
配列による単純なキューの問題点:擬似的なオーバーフロー
単純な配列でキューを実装した場合、デキューを繰り返すと配列の前方に使用できない空き領域が発生します。この現象を「擬似的なオーバーフロー」と呼びます。具体的には、フロントのインデックスがどんどん後ろに移動していき、配列の先頭部分が無駄になってしまうのです。
例えば、配列のサイズが5で、エンキューを5回行い、その後デキューを3回行ったとします。このとき、配列の先頭2つの要素は空いていますが、リアは配列の末尾にあるため、新しい要素を追加しようとすると「配列が満杯」というエラーが発生します。実際には配列の前半部分は空いているにもかかわらです。
この問題を解決するために、次に説明する「循環キュー(リングバッファ)」という概念が登場します。
循環キュー(リングバッファ)による解決策
循環キュー(Circular Queue)は、配列の末尾と先頭を論理的に接続することで、擬似的なオーバーフロー問題を解決します。配列をリング状の構造として扱い、リアやフロントが配列の末尾に達したら、再び先頭に戻るようにします。
循環キューの実装では、フロントとリアのインデックスを更新する際に、配列のサイズで剰余演算(モジュロ演算)を行います。例えば、配列のサイズが5の場合、リアのインデックスが4(末尾)からさらに1つ進むと、(4+1) % 5 = 0となり、先頭に戻ります。
循環キューでは、キューが空か満杯かを判定するために、いくつかの方法があります。一般的な方法としては、1つの要素分の空きを常に確保しておく方法や、サイズ変数を別途管理する方法があります。
順序表(配列)キューの時間計算量と空間計算量
配列を用いたキューの各操作の時間計算量は以下の通りです。
エンキュー(enqueue):O(1)(定数時間)。配列の末尾に要素を追加するだけなので、非常に高速です。
デキュー(dequeue):O(1)(定数時間)。フロントのインデックスを進めるだけなので、これも高速です。ただし、単純な配列実装で要素を実際に削除して詰め直す場合はO(n)になります。
フロント(front):O(1)(定数時間)。フロントのインデックスが指す要素を参照するだけです。
空間計算量:O(n)。n個の要素を格納するために、配列のサイズ分のメモリを消費します。循環キューでも同様にO(n)の空間が必要です。
キュー(順序表)の特徴と長所・短所
配列を用いたキューの最大の長所は、すべての基本操作がO(1)の定数時間で実行できる点です。これは非常に効率的であり、リアルタイムシステムやパフォーマンスが重要なアプリケーションに適しています。
また、配列はメモリの局所性が高いため、キャッシュメモリの効果を受けやすく、実際の実行速度も高速です。さらに、実装が比較的シンプルで初心者にも理解しやすいという利点もあります。
一方、短所としては以下の点が挙げられます。
固定サイズ:配列は宣言時にサイズを決定する必要があり、動的に拡張することができません。キューに格納できる最大要素数が事前に決まってしまいます。これを解決するために、動的配列(ArrayListなど)を使用する方法もありますが、その場合はリサイズのコストが発生します。
メモリの無駄:循環キューを使用しない単純な実装では、デキュー操作によって配列の前方に空き領域が発生し、メモリを効率的に利用できません。
要素の削除が論理的:デキュー操作では要素が実際にメモリから削除されるわけではなく、フロントのインデックスが移動するだけです。そのため、配列内には削除された要素のデータが残り続けます。
キューの代表的な応用シーン
キューはコンピュータサイエンスのさまざまな分野で利用されています。以下に代表的な応用例を紹介します。
CPUスケジューリング:ペーティングシステムにおいて、複数のプロセスを実行する順番を管理するためにキューが使用されます。ラウンドロビン方式などのスケジューリングアルゴリズムでは、キューが中心的な役割を果たします。
プリンタのスプーリング:複数のアプリケーションから送信された印刷ジョブを、プリンタが処理する順番を管理するためにキューが使用されます。最初に送信されたジョブが最初に印刷されます。
メッセージキューシステム:分散システムやマイクロサービスアーキテクチャにおいて、サービス間の非同期通信を実現するためにメッセージキューが使用されます。RabbitMQやApache Kafkaなどのメッセージブローカーは、キューを基本構造として利用しています。
Webサーバーのリクエスト管理:多数のクライアントからのHTTPリクエストを処理する際、サーバーはリクエストをキューに格納し、順番に処理します。これにより、サーバーの負荷を平準化することができます。
幅優先探索(BFS):グラフやツリーの探索アルゴリズムである幅優先探索では、訪問するノードを管理するためにキューが使用されます。これはキューがFIFOの性質を持つため、同じ深さのノードを順番に探索できるからです。
キャッシュシステム:FIFO方式のキャッシュ置き換えアルゴリズムでは、キューを使用してキャッシュエントリの管理を行います。最も古いエントリから順に追い出されます。
キューとスタックの違い:重要な比較ポイント
データ構造の学習において、キューとスタックはよく比較されます。両者の最大の違いは、要素の取り出し順序です。
キューはFIFO(先入れ先出し)であり、最初に入れた要素が最初に出てきます。一方、スタックはLIFO(後入れ先出し)であり、最後に入れた要素が最初に出てきます。
スタックの例としては、机の上に積み重ねた書類を想像してください。一番上に置いた書類(最後に追加したもの)を最初に取り出します。これがLIFOの動作です。
キューの操作はエンキューとデキューと呼ばれるのに対し、スタックの操作はプッシュ(push)とポップ(pop)と呼ばれます。この用語の違いも覚えておくと良いでしょう。
配列によるキュー実装とリンクリストによる実装の比較
キューを実装する方法として、配列(順序表)の他に、リンクリスト(連結リスト)を使用する方法もあります。それぞれに長所と短所があります。
配列実装の長所:メモリの局所性が高く、キャッシュに乗りやすいため高速です。また、インデックスによるランダムアクセスが可能です(ただしキューでは通常使用しません)。
配列実装の短所:サイズが固定されており、動的な拡張が難しいです。また、循環キューを使用しないとメモリ効率が悪くなります。
リンクリスト実装の長所:動的にサイズを変更できるため、メモリを効率的に使用できます。要素の追加・削除がO(1)で行えます。
リンクリスト実装の短所:各ノードに次のノードへのポインタを格納するための追加メモリが必要です。また、メモリの局所性が低いため、キャッシュミスが発生しやすく、実際の実行速度は配列実装に劣る場合があります。
データ構造可視化学習プラットフォームの紹介
キュやその他のデータ構造を学習する際、実際の動作を視覚的に確認できる「データ構造可視化学習プラットフォーム」は非常に有効なツールです。このプラットフォームでは、コードの実行に伴ってデータ構造がどのように変化するかをアニメーションで確認することができます。
可視化プラットフォームの主な機能
リアルタイムアニメーション:エンキュー操作やデキュー操作が行われるたびに、配列上の要素の動きがアニメーションで表示されます。フロントやリアのポインタがどのように移動するかも視覚的に確認できます。
ステップ実行機能:1行ずつコードを実行しながら、その都度データ構造の状態を確認できます。これにより、各操作が内部でどのように行われているかを詳細に理解することができます。
複数の実装方法の比較:配列による実装とリンクリストによる実装を並べて表示し、両者の違いを視覚的に比較することができます。
カスタムデータ入力:自分で任意のデータを入力して、キューがどのように動作するかを実験できます。例えば、エンキューとデキューの順序を変えてみることで、FIFOの原則をより深く理解できます。
エラーケースの可視化:空のキューに対してデキュー操作を行った場合や、満杯のキューに対してエンキュー操作を行った場合に、どのようなエラーが発生するかを視覚的に確認できます。
可視化プラットフォームを活用した学習のメリット
データ構造の可視化学習には、以下のような多くのメリットがあります。
抽象概念の具体化:キューやポインタの動きといった抽象的な概念を、実際のアニメーションとして目で見て確認できるため、理解が格段に深まります。
誤解の防止:テキストだけの学習では、内部の動作を誤解してしまうことがあります。可視化ツールを使用することで、正しい動作を直感的に理解できます。
デバッグスキルの向上:実際にコードを書きながら可視化ツールを使用することで、バグが発生した際にデータ構造の状態を確認する習慣が身につきます。これは実践的なデバッグスキルの向上につながります。
効率的な学習:可視化によって理解が早まるため、学習時間を短縮することができます。また、視覚的な記憶は長期記憶に残りやすいという利点もあります。
インタラクティブな学習体験:自分で操作しながら学べるため、受動的な学習よりも能動的な学習が促進されます。これにより、学習意欲の維持にもつながります。
可視化プラットフォームの使い方:キュー学習の具体的手順
データ構造可視化学習プラットフォームを使用してキューを学習する際の、具体的な手順を紹介します。
ステップ1:配列ベースのキュー実装を選択:プラットフォーム上で、配列を用いたキューの実装を選択します。初期状態では空の配列が表示され、フロントとリアのポインタが初期位置にあります。
ステップ2:エンキュー操作を実行:エンキューボタンをクリックするか、対応するコードを実行します。配列の末尾(リアの位置)に新しい要素が追加され、リのポインタが1つ進む様子がアニメーションで表示されます。
ステップ3:デキュー操作を行:デキューボタンをクリックします。フロントのポインタが指す要素がハイライト表示され、その後フロントのポインタが1つ進みます。要素自体は配列に残りますが、論理的には削除された状態になります。
ステップ4:循環キューの動作を確認:配列の末尾まで要素を追加した後、さらにエンキューを実行します。リアのポインタが配列の先頭に戻る様子を確認できます。これにより、循環キューの概念が視覚的に理解できます。
ステップ5:エラーケースを体験:空のキューでデキューを実行してみます。エラーメッセージが表示され、なぜエラーが発生するのかを説明するポップアップが表示されます。
キューに関するよくある質問と誤解
キューを学習する際に、初心者がよく抱く質問や誤解について解説します。
質問1:キューとスタックの違いは何ですか?:キューはFIFO(先入れ先出し)、スタックはLIFO(後入れ先出し)です。日常生活での例えると、キューはレジに並ぶ列、スタックは積み重ねた皿です。
質問2:配列でキューを実装するとき、なぜ循環構造が必要なのですか?:循環構造を使用しないと、デキューを繰り返した際に配列の前方に空き領域が発生し、メモリを効率的に利用できなくなります。循環構造により、空き領域を再利用できるようになります。
質問3:キューはどのような場面で使われますか?:CPUスケジューリング、プリンタのジョブ管理、メッセージキュー、幅優先探索など、さまざまな場面で使用されます。共通するのは「順番を守って処理する」必要がある場面です。
誤解1:デキューは要素を物理的に削除する:配列実装の場合、デキューはフロントのインデックスを進めるだけで、要素自体は配列に残り続けます。要素が実際に削除されるわけではありません。
誤解2:キューは常に配列で実装される:キューはリンクリストや両端キュー(デック)など、さまざまな方法で実装できます。配列はその一つの方法に過ぎません。
キューを学習する際のロードマップ
キューを効率的に学習するためのロードマップを紹介します。
ステップ1:基本概念の理解:FIFOの原則、エンキューとデキューの操作を理解します。日常生活の例を使って概念を掴みましょう。
ステップ2:配列による実装の学習:単純な配列キューと循環キューの実装方法を学びます。フロントとリアのポインタの動きを理解することが重要です。
ステップ3:可視化ツールでの確認:データ構造可視化プラットフォームを使用して、実際の動作を視覚的に確認します。自分で操作しながら学習することで理解が深まります。
ステップ4:リンクリストによる実装の学習:リンクリストを使用したキューの実装方法を学び、配列実装との違いを比較します。
ステップ5:実際のコーディング:自分でキューを実装するコードを書いてみます。まずは簡単なものから始め、徐々に機能を追加していきます。
ステップ6:応用問題への挑戦:キューを使用したアルゴリズム問題(幅優先探索、スライディングウィンドなど)に挑戦します。
まとめ:キュー(順序表)の学習ポイント
本記事では、順序表(配列)を用いたキューの実装について、基本原理から応用までを詳しく解説しました。キューはFIFO(先入れ先出し)の原則に従うデータ構造であり、エンキューとデキューの操作がO(1)の定数時間で実行できることが最大の特徴です。
配列による実装では、循環キューを使用することで擬似的なオーバーフロー問題を解決できます。キューはCPUスケジューリング、メッセージキュー、幅優先探索など、さまざまな分野で応用されています。
データ構造可視化学習プラットフォームを活用することで、キューの内部動作を視覚的に理解し、より深い学習効果を得ることができます。実際にコードを書きながら可視化ツールを使用することで、理論と実践の両方をバランスよく学ぶことができるでしょう。
キューはデータ構造の基本であり、これを理解することは、より複雑なデータ構造やアルゴリズムを学ぶための重要な基盤となります。ぜひ、可視化ツールを活用しながら、キューの学習を進めてください。
树(Tree)
树是一种非线性的数据结构,它由一组按 分层顺序排列的节点组成。 其中一个节点被指定为根节点,其余的节点可以被划分为不相交的集合,这样每个集合都是根的一个子树。
树的最简单的形式是二叉树。 二叉树由一个根节点和左右子树组成,其中两个子树也是二叉树。每个节点都包含一个数据元素、一个指向左子树的左指针和一个指向右子树的右指针。根元素是由一个“根”指针指向的最顶部的节点。
二叉树 | 可视化完整可视化
1.1 データ構造とは? - データ構造チュートリアル アニメーションでコードを可視化しよう
データ構造とアルゴリズムの可視化学習:木、二分探索、連結リストを徹底解説
データ構造とアルゴリズムは、ソフトウェア開発において最も重要な基礎知識の一つです。しかし、その抽象的な概念を理解することは多くの学習者にとって難しい課題です。特に「木(ツリー)」「二分探索」「連結リスト」といったテーマは、初学者がつまずきやすいポイントです。本記事では、これらのデータ構造とアルゴリズムについて、原理から応用例まで詳しく解説します。また、私たちのデータ構造可視化学習プラットフォームを活用することで、どのように理解を深められるかについても紹介します。
木(ツリー)データ構造の基礎
木は、階層関係を表現するためのデータ構造です。現実世界では、家系図、組織図、ファイルシステムのディレクトリ構造など、様々な場面で木構造が使われています。木は「ノード(節点)」と「エッジ(辺)」で構成され、根(ルート)から枝分かれしていく構造を持ちます。
木の最大の特徴は、循環がないことです。これはグラフと異なる点であり、この性質があるため検索や挿入が効率的に行えます。木の基本的な用語として、「親ノード」「子ノード」「葉ノード(リーフ)」「深さ」「高さ」などを理解することが重要です。
特に重要なのが「二分木」です。二分木は各ノードが最大2つの子ノード(左の子と右の子)を持つ木です。二分木の中でも、すべての葉ノードが同じ深さにある「完全二分木」や、左の子<親<右の子という順序関係を常に保つ「二分探索木」が特に重要です。
木構造の操作には、深さ優先探索(DFS)と幅優先探索(BFS)という二つの基本的な探索方法があります。DFSには行きがけ順、通りがけ順、帰りがけ順という三つのバリエーションがあり、それぞれ異なる順序でノードを訪問します。これらの概念を可視化ツールで実際に動かしながら学ぶことで、直感的な理解が得られます。
二分探索の原理と応用
二分探索は、ソート済みのデータに対して効率的に目的の値を探し出すアルゴリズムです。このアルゴリズムの考え方は、探索範囲を半分ずつに絞り込んでいくというシンプルなものです。配列の中央の値と目的の値を比較し、目的の値が小さければ左半分、大きければ右半分に絞り込みます。この操作を繰り返すことで、データ数がnの場合、最大でもlog₂(n)回の比較で目的の値に到達できます。
二分探索の時間計算量はO(log n)であり、線形探索のO(n)と比較すると、大規模なデータに対して圧倒的に高速です。例えば、100万件のデータから目的の値を探す場合、線形探索では平均50万回の比較が必要ですが、二分探索では最大20回の比較で済みます。
二分探索を実装する際の注意点として、データが事前にソートされている必要があること、そして配列のインデックス管理を正確に行うことが挙げられます。多くの初学者が「オフバイワンエラー」に悩まされるポイントです。可視化ツールを使えば、各ステップでどの範囲を探索しているのかが一目でわかり、このようなエラーを防ぐ理解が得られます。
二分探索の応用例としては、辞書検索、バグ修正の二分法、数学的な方程式の解の近似計算などがあります。また、二分探索木では、この二分探索の考え方を木構造に応用しており、挿入、削除、検索を効率的に行えるようにしています。
連結リストの仕組みと特徴
連結リストは、要素を線形に並べたデータ構造ですが、配列とは異なりメモリ上で連続した領域を必要としません。各要素は「ノード」と呼ばれ、データと次のノードへのポインタ(参照)を持ちます。単方向連結リスト、双方向連結リスト、循環連結リストなどの種類があります。
連結リストの最大の利点は、要素の挿入と削除がO(1)で行えることです。配列では要素を途中に挿入する際、後続の要素をすべてずらす必要があるためO(n)の時間がかかりますが、連結リストではポインタの付け替えだけで済みます。一方、連結リストの欠点は、任意の位置の要素にアクセスするのにO(n)の時間がかかることです。配列ではインデックスを使ってO(1)でアクセスできるのとは対照的です。
連結リストは、メモリの動的割り当てが必要な場面や、要素数が頻繁に変化する場面で威力を発揮します。具体的な応用例としては、OSのプロセス管理、画像編集ソフトのアンドゥ機能、音楽プレイヤーのプレイリストなどがあります。
連結リストの操作を理解する上で重要なのは、ポインタの概念です。特に「ダミーノード」の使用や「二重ポインタ」の考え方は、多くの学習者にとって難しい部分です。可視化ツールを使えば、各ノードがどのようにリンクされているか、挿入や削除の際にポインタがどのように変化するかを、アニメーションで確認できます。
木、二分探索、連結リストの関連性
これら三つのテーマは、一見すると独立した概念のように思えますが、実際には深く関連しています。例えば、二分探索木は木構造と二分探索の考え方を組み合わせたものです。また、連結リストは木の表現方法の一つとして使われることがあります。特に「子兄弟表現法」では、木の各ノードが持つ子ノードを連結リストで管理します。
さらに、ハッシュテーブルのチェイン法では、衝突が発生した要素を連結リストで管理します。このように、データ構造は単独で使われるよりも、組み合わせて使われることが多いのです。可視化学習プラットフォームでは、これらのデータ構造がどのように連携するかを、統合的なビューで確認できます。
また、赤黒木やAVL木といった平衡二分探索木は、二分探索木の操作を効率化するために発展したものです。これらの高度なデータ構造も、基本となる木構造と二分探索の理解があれば、スムーズに学習できます。
データ構造可視化学習プラットフォームの機能と利点
私たちのデータ構造可視化学習プラットフォームは、抽象的な概念を視覚的に理解するための強力なツールです。主な機能として、以下のものがあります。
まず、ステップバイステップのアニメーション機能です。各アルゴリズムの実行過程を、一歩ずつ追いながら確認できます。これにより、データがどのように変化するのか、ポインタがどのように移動するのかを、自分のペースで理解できます。
次に、インタラクティブな操作機能です。ユーザー自身がデータを追加・削・索する操作を行い、その結果をリアルタイムで確認できます。例えば、二分探索木に新しいノードを挿入する際、どのような経路で目的の位置にたどり着くのかを視覚的に追跡できます。
また、複数のアルゴリズムを比較する機能も備えています。同じデータに対して線形探索と二分探索を実行し、その速度差を実感できます。これにより、なぜアルゴリズムの選択が重要なのかを、体感的に学べます。
さらに、コードと可視化の連携機能があります。表示されているアニメーションと、実際のソースコードを並べて表示することで、抽象的なコードが具体的に何をしているのかを理解できます。対応言語はPython、Java、C++、JavaScriptなど、主要なプログラミング言語をカバーしています。
可視化ツールを使った効果的な学習方法
可視化ツールを最大限に活用するための学習手順を紹介します。まず、テキストや動画で基本的な概念を学びます。次に、可視化ツールでそのアルゴリズムを実行し、理論と実際の動作を結びつけます。このとき、単に見るだけでなく、自分で「もしこの値を挿入したらどうなるか」「この順序で削除したら木の形はどう変わるか」といった仮説を立て、それをツールで検証する能動的な学習が効果的です。
特に重要なのは、エッジケース(境界条件)を自分で試すことです。例えば、二分探索で目的の値が配列の最初や最後にある場合、または存在しない場合にどうなるかを確認します。連結リストでは、空のリストへの挿入や、最後のノードの削除といったケースを試します。これらのエッジケースは、実際のプログラミングでバグの原因になりやすい部分です。
また、可視化ツールには速度調整機能があるため、最初はゆっくりとした速度で各ステップを確認し、理解が進んだら速度を上げて全体の流れを把握するという学習方法も有効です。
各データ構造とアルゴリズムの応用シナリオ
木構造の実践的な応用例として、HTMLのDOMツリーがあります。Webページの構造は木として表現され、JavaScriptを使って効率的に操作できます。また、コンパイラの構文解析では、プログラムの構造を抽象構文木(AST)で表現します。データベースのインデックスにはB木やB+木が使われており、大量のデータから高速に検索を行うことを可能にしています。
二分探索の応用例として、機械学習のハイパーパラメータチューニングがあります。グリッドサーチやランダムサーチの代わりに、二分探索の考え方を応用したベイズ最適化が使われることもあります。また、ゲーム開発では、二分探索を使って衝突判定や当たり判定を効率化することがあります。
連結リストの応用例として、ブラウザの戻る・進む機能があります。これは双方向連結リストで実装されており、ユーザーが訪れたページを前後に移動できます。また、メモリ管理のフリーリストや、グラフの隣接リスト表現にも連結リストが使われています。
学習の際に陥りやすい誤解とその解決法
多くの学習者が最初に陥る誤解は、木と二分探索木を混同することです。すべての木が二分探索木であるわけではなく、二分探索木は左の子<親<右の子という特別な条件を満たす木です。可視化ツールで実際に条件を満たさない木を作成し、検索がうまくいないことを確認することで、この違いが明確になります。
また、二分探索の再帰的実装において、ベースケースの設定を誤るケースが多く見られます。可視化ツールでスタックの状態を確認しながら学習することで、再帰の動作原理を正しく理解できます。
連結リストについては、「ポインタ」という抽象的な概念が理解の障壁になることがあります。可視化ツールでは、ポインタを矢印で表現し、その矢印がどのノードを指しているのかを明確に表示することで、この概念を直感的に理解できます。
まとめ:可視化学習でデータ構造をマスターする
データ構造とアルゴリズムの学習において、可視化ツールは強力な味方です。木、二分探索、連結リストといった基本概念は、実際に動きを見ながら学ぶことで、単なる暗記ではなく本質的な理解が得られます。私たちの可視化学習プラットフォームは、初心者から上級者まで、すべての学習者に最適な学習体験を提供します。
まずは基本的な二分探索木の操作から始め、徐々に平衡木やグラフアルゴリズムへと学習を進めることをお勧めします。各ステップで可視化ツールを活用することで、複雑な概念も確実に理解できるようになります。データ構造とアルゴリズムの習得は、プログラマとしての成長に不可欠です。ぜひ、可視化ツールを活用して、効率的に学習を進めてください。
私たちのプラットフォームは無料で利用でき、ブラウザ上で動作するため、インストールの必要はありません。今すぐアクセスして、データ構造の世界を視覚的に探索してみましょう。学習の進捗に応じて、より高度なトピックにも挑戦できるよう、コンテンツを定期的に更新しています。
图(Graphs)
图是一种非线性的数据结构,它是连接这些顶点的顶点(也称为节点)和边的集合。图通常被视为树结构的泛化,其中树节点之间不是纯粹的父子关系,节点之间的任何复杂关系。在树状结构中,节点可以有任意数量的子节点,但只有一个父节点,但是在图中却没有这些限制。
图的数据结构 | 可视化完整可视化
1.1 データ構造とは? - データ構造チュートリアル アニメーションでコードを可視化しよう
グラフの記憶構造とは?データ構造とアルゴリズム学習の基本
グラフは、データ構造とアルゴリズムの分野において非常に重要な概念です。グラフは「ノード(頂点)」と「エッジ(辺)」の集合で構成され、現実世界のさまざまな関係性をモデル化できます。例えば、ソーシャルネットワークの友達関係、地図上の道路ネットワーク、Webページ間のリンク構造など、多くの場面でグラフが利用されています。本記事では、グラフの記憶構造(格納方法)について、初心者にもわかりやすく解説します。
グラフの基本概念:ノードとエッジ
グラフは、ノード(頂点)とエッジ(辺)から成り立っています。ノードはデータの単位を表し、エッジはノード間の関係を表します。例えば、友達関係をグラフで表す場合、各人物がノードとなり、友達同士を結ぶ線がエッジとなります。エッジには方向がある「有向グラフ」と方向がない「無向グラフ」の2種類があります。有向グラフではエッジに矢印が付き、一方方向の関係を示します。無向グラフではエッジに方向がなく、双方向の関係を示します。
グラフの記憶構造:主要な2つの方法
グラフをコンピュータ上で扱うためには、効率的な記憶構造が必要です。代表的な記憶構造として、「隣接行列」と「隣接リスト」の2つがあります。それぞれに特徴があり、使用する場面によって適切な方法を選ぶことが重要です。
隣接行列によるグラフの表現
隣接行列は、グラフのノード数をNとしたとき、N×Nの2次元配列(行列)を使ってグラフを表現します。行列の各要素は、対応するノード間にエッジが存在するかどうかを示します。無向グラフの場合は対称行列になり、有向グラフの場合は非対称行列になります。重み付きグラフでは、エッジの重みを数値で格納します。隣接行列の最大の利点は、2つのノード間のエッジの有無をO(1)で確認できることです。しかし、ノード数が多い場合、メモリ消費量がN^2に比例するため、大規模なグラフには不向きです。
隣接リストによるグラフの表現
隣接リストは、各ノードに対して、そのノードに隣接するノードのリストを保持する方法です。具体的には、配列の各要素に連結リストや動的配列を持たせ、エッジで結ばれたノードを格納します。隣接リストの利点は、メモリ使用量がエッジの数に比例することです。そのため、疎なグラフ(エッジが少ないグラフ)に対して非常に効率的です。ただし、特定のエッジの有無を確認するには、リストを走査する必要があるため、最悪でO(degree)の時間がかかります。
その他のグラフ記憶構造
隣接行列と隣接リスト以外にも、グラフを表現する方法はいくつか存在します。「エッジリスト」は、すべてのエッジを(始点, 終点, 重み)のタプルとして単純にリストに格納する方法です。実装が非常に簡単で、特にエッジの追加や削除が頻繁に行われない場合に適しています。「圧縮隣接リスト」は、隣接リストをさらに効率化したもので、大規模グラフの処理に用いられます。「次数行列」や「ラプラシアン行列」は、グラフ理論の高度な解析で使用される特殊な行列で。
グラフ記憶構造の選び方:実践的な指針
グラフの記憶構造を選ぶ際には、以下の要素を考慮する必要があります。ノード数とエッジ数の比率(密度)、実行する操作の種類(エッジの有無確認、隣接ノードの列挙、エッジの追加・削除など)、メモリ制約、そして実装のしやすさです。一般的には、密なグラフ(エッジが多いグラフ)には隣接行列、疎なグラフには隣接リストが推奨されます。また、アルゴリズムの特性も考慮しましょう。例えば、ダイクストラ法や幅優先探索では隣接リストが効率的ですが、ワーシャルフロイド法では隣接行列が適しています。
グラフ記憶構造の応用例
グラフの記憶構造は、多くの実践的なアプリケーションで使用されています。ソーシャルネットワーク分析では、ユーザー間のつながりを隣接リストで管理し、友達推薦やコミュニティ検出を行います。GPSナビゲーションシステムでは、交差点をノード、道路をエッジとするグラフを隣接リストで表現し、最短経路を計算します。Web検索エンジンは、Webページをノード、ハイパーリンクをエッジとする有向グラフを大規模に処理し、PageRankなどのアルゴリズムを実行します。さらに、分子構造の解析や交通ネットワークの最適化など、グラフの応用範囲は非常に広いです。
データ構造可視化プラットフォームの機能と利点
グラフの記憶構造を深く理解するためには、実際に動作を確認しながら学習することが効果的です。データ構造可視化プラットフォームは、グラフの構築、探索、更新のプロセスをアニメーションで表示することで、抽象的な概念を直感的に理解できるように支援します。具体的な機能として、ノードやエッジの追加・削除操作の可視化、隣接行列と隣接リストの相互変換のデモンストレーション、各アルゴリズムのステップごとの実行トレースなどがあります。特に、グラフの記憶構造がアルゴリズムのパフォーマンスにどのように影響するかを視覚的に比較できる点が大きな利点です。
可視化プラットフォームの使い方:学習効率を最大化する
可視化プラットフォームを効果的に使用するためには、以下の手順を推奨します。まず、基本的なグラフの種類(無向グラフ、有向グラフ、重み付きグラフ)を選択し、小さなグラフを手動で作成してみましょう。次に、隣接行列と隣接リストの2つの表示モードを切り替えながら、それぞれの構造がどのように情報を保持しているかを観察します。そして、代表的なグラフアルゴリズム(深さ優先探索、幅優先探索、ダイクストラ法など)を実行し、各ステップでデータ構造がどのように変化するかを追跡します。最後に、自分で問題を設定し、どの記憶構造が最適かを考えながら実装してみると、理解がさらに深まります。
グラフ記憶構造の学習におけるよくある誤解
グラフ記憶構造を学習する際、初心者が陥りやすい誤解がいくつかあります。一つ目は、「隣接行列は常に非効率」という思い込みです。実際には、密なグラフやエッジの有無を頻繁に確認する処理では、隣接行列の方が効率的な場合があります。二つ目は、「隣接リストは常にメモリ効率が良い」という誤解です。エッジ数がノード数の二乗に近い密なグラフでは、隣接リストの方がメモリオーバーヘッドが大きくなる可能性があります。三つ目は、「グラフの表現方法はアルゴリズムに影響しない」という考え方です。実際には、同じアルゴリズムでも、使用する記憶構造によって時間計算量や空間計算量が大きく変わります。これらの誤解を解消するためにも、可視化プラットフォームで実際に比較しながら学習することが有効です。
グラフ記憶構造の高度なトピック
基本的な記憶構造を理解した後は、より高度なトピックに進むことができます。「疎行列」の表現方法は、大規模なグラフを扱う際に重要です。CSR(Compressed Sparse Row)形式やCSC(Compressed Sparse Column)形式は、隣接行列を効率的に圧縮する手法で、多くのグラフ処理ライブラリで採用されています。「グラフデータベース」は、グラフ構造をネイティブに保存・検索できるデータベースで、Neo4jなどが有名です。「動的グラフ」では、ノードやエッジの追加・削除が頻繁に発生するため、それに適した記憶構造が必要です。また、「ハイパーグラフ」や「マルチグラフ」など、標準的なグラフを拡張した構造も存在し、それぞれに適した記憶方法が研究されています。
グラフ記憶構造とアルゴリズムの関係
グラフアルゴリズムの効率は、選択した記憶構造に大きく依存します。例えば、ダイクストラ法による最短経路探索では、隣接リストと優先度付きキューを組み合わせることでO((V+E)logV)の時間計算量を実現できます。一方、隣接行列を使用するとO(V^2)となり、大規模グラフでは実用的ではありません。幅優先探索(BFS)や深さ優先探索(DFS)では、隣接リストを使用するとO(V+E)で動作しますが、隣接行列を使用するとO(V^2)になります。クラスカル法やプリム法による最小全域木の計算でも、グラフの密度に応じて適切な記憶構造を選ぶことが重要です。このように、アルゴリズムとデータ構造は密接に関連しており、両方を理解することで効率的なプログラムを作成できます。
実践的なコーディング例:隣接リストの実装
具体的な実装イメージを持つことは、理解を深める上で重要です。隣接リストは、多くのプログラミング言語で簡単に実装できます。例えば、Pythonでは辞書とリストを使って表現できます。ノードをキー、隣接ノードのリストを値とする辞書を作成し、エッジを追加するたびにリストにノードを追加します。無向グラフの場合は、両方向のエッジを追加する必要があります。重み付きグラフの場合は、リストの要素をタプル(隣接ノード, 重み)にします。Javaでは、ArrayListの配列を使用する方法が一般的です。C++では、vectorの配列やlistの配列を使用します。可視化プラットフォームでは、これらの実装をコードレベルで確認し、実行結果と対応付けて学習することができます。
グラフ記憶構造のパフォーマンス比較
グラフ記憶構造の性能を比較する際には、以下の指標を考慮します。メモリ使用量は、隣接行列がO(V^2)、隣接リストがO(V+E)、エッジリストがO(E)です。エッジの有無確認は、隣接行列がO(1)、隣接リストがO(degree)、エッジリストがO(E)です。隣接ノードの列挙は、隣接行列がO(V)、隣接リストがO(degree)、エッジリストがO(E)です。エッジの追加は、隣接行列がO(1)、隣接リストがO(1)(リストの末尾に追加する場合)、エッジリストがO(1)です。これらの特性を理解した上で、アプリケーショの要件に合わせて最適な構造を選択することが重要です。可視化プラットフォームでは、実際に異なるサイズのグラフでこれらのパフォーマンスを計測し、比較することができます。
グラフ記憶構造の学習リソースと可視化ツール
グラフ記憶構造を効果的に学習するためには、複数のリソースを組み合わせることが推奨されます。理論的な理解には、データ構造とアルゴリズムの教科書やオンライン講座が役立ちます。実践的なスキルを身につけるには、LeetCodeやAtCoderなどの競技プログラミングサイトでグラフ問題を解くことが効果的です。そして、可視化プラットフォームは、理論と実践の橋渡し役として機能します。特に、複雑なグラフアルゴリズムの動作をステップバイステップで確認できる点が、他の学習方法にはない利点です。当プラットフォームでは、隣接行列と隣接リストの両方の表示に対応しており、ワンクリックで切り替えながら学習を進めることができます。
まとめ:グラフ記憶構造の習得がもたらすもの
グラフの記憶構造は、データ構造とアルゴリズムの学習において避けて通れない重要なトピックです。隣接行列と隣接リストという2つの基本的な表現方法を理解し、それぞれの長所と所を把握することで、効率的なプログラムを作成できるようになります。さらに、可視化プラットフォームを活用することで、抽象的な概念を具体的にイメージしながら学習を進めることができます。グラフ記憶構造の知識は、ソフトウェアエンジニアリング、データサイエンス、人工知能など、幅広い分野で応用可能です。ぜひ、当プラットフォームで実際に手を動かしながら、グラフの世界を探求してみてください。
❗️ 注意:
请注意,与树不同,图没有任何根节点。相反,图中的每个节点都可以与图中的每一个节点进行连接。当两个节点通过一条边连接时,这两个节点被称为相邻节点。例如,在上图中,节点A有两个邻居:B和D。