 图码
图码2.3 双链表
单链表结点中只有一个指向其后继的指针,使得单链表只能从前往后依次遍历。要访问某个结点的前驱(插入、删除操作时),只能从头开始遍历,访问前驱的时间复杂度为 O(n)。
为了克服单链表的这个缺点,引入了双链表,双链表结点中有两个指针prior和next,分别指向其直接前驱和直接后继。
双链表的主要特性
- 双向遍历由于每个节点都有前后两个指针,因此可以在列表中双向遍历,无需像单链表那样只能从头节点开始向前遍历。
- 插入与删除的便捷性:在双链表中插入或删除一个节点时,只需改变相应节点的前后节点的指针指向即可,操作相对简单高效。
数据结构
- data:数据域,也是节点的值
- prior:指针域,指向前一个结点的指针
- next:指针域,指向下一个结点的指针
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
typedef struct DNode {
int data; // 数据
struct DNode *prior, *next; // 前驱和后继指针
} DNode, *DLinkList;
pTemp = (DNode *)malloc(sizeof(DNode));
pTemp->data = x;
pTemp->next = pHead->next;
pTemp->prior = pHea
// 完整代码:https://totuma.cn
链表结构
💡双链表在单链表结点中增加了一个指向其前驱的指针prior ,因此双链表的按值查找和按位查找的操作与单链表的相同。但双链表在插入和删除操作的实现上,与单链表有着较大的不同。 这是因为“链”变化时也需要对指针 prior 做出修改,其关键是保证在修改的过程中不断链。 此外,双链表可以很方便地找到当前结点的前驱,因此,插入、除操作的时间复杂度仅为 O(1)。
双链表的基本操作实现
单链表的节点在需要时动态分配内存,这意味着不需要像数组那样在创建时预先分配一大片连续内存。因此,单链表在内存使用上更加灵活,可以有效应对内存碎片和动态增长的问题。
由于链表节点是在需要时分配的,可以避免数组因初始化大小不确定而造成的内存浪费。例如,如果数组大小初始化过大,未使用的部分将浪费内存;若初始化过小,则可能需要频繁重新分配和复制。
每个节点需要一个指针域来存储对下一个节点的引用,这意味着相比于数组,单链表在每个节点上都会有额外的内存开销。对于存储小数据的场景,这个开销相对较大,可能导致内存利用率下降。
按位序插入结点
该函数用于在双向链表中按指定位置插入一个新元素。(注意区分位置和下标:位置从1开始,下标从0开始)
在位置 i 插入元素 e,其中 i=1 表示插入到表头,i=length+1 表示插入到表尾。
重点注意下链表为空和不为空时的处理逻辑
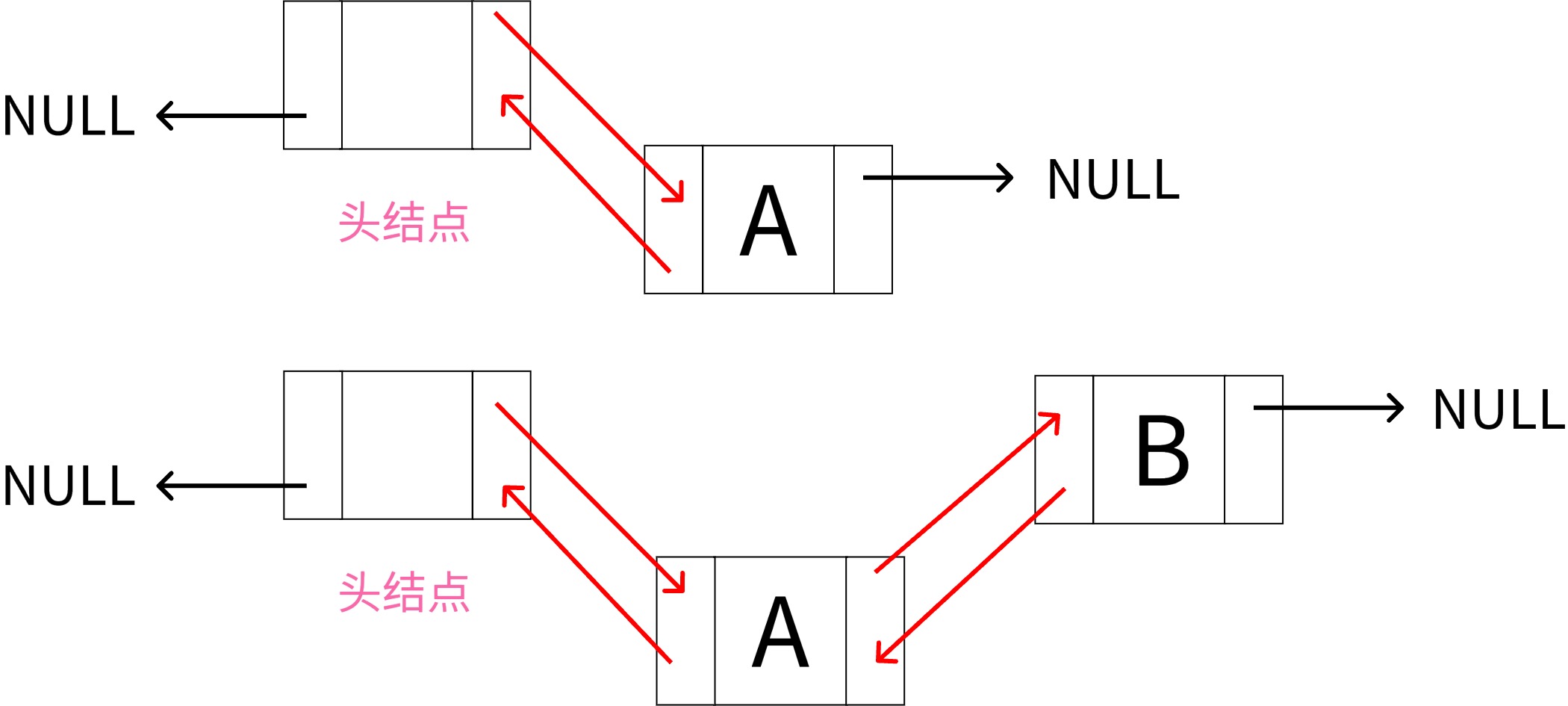
插入时链表空和不空时的区别
按位序插入结点 | 可视化完整可视化
2.3 双方向連結リスト詳解 - 線形リストチュートリアル アニメーションでコードを可視化しよう

データ構造とアルゴリズム学習に必須!「線形リスト(リンクトリスト)」とは?
プログラミングを学び始めて「配列」の次に登場するのが「線形リスト(リンクトリスト)」です。これは、データを鎖のように連結して管理するデータ構造です。本記事では、線形リストの仕組み、特徴、そして実際の応用例について、初心者の方にもわかりやすく解説します。さらに、データ構造とアルゴリズムの可視化学習プラットフォームを活用することで、なぜ理解が深まるのかについても詳しく説明します。
線形リストの基本原理:ポインタで繋がれたデータの列
線形リストは、「ノード」と呼ばれる要素が一列に並んだデータ構造です。各ノードは、自分が保持するデータ(値)と、次のノードを指し示す「ポインタ(参照)」という2つの部分から構成されます。配列のようにメモリ上に連続した領域を確保する必要がなく、各ノードはメモリ上の別々の場所に存在していても、ポンタでつなぐことで論理的な順序を表現します。
例えば、3つのノードA、B、Cがあるとします。ノードAはデータ「10」と次のノードBへのポインタを持ち、ノードBはデータ「20」と次のノードCへのポインタを持ち、ノードCはデータ「30」と「終端(NULL)」を示すポインタを持ちます。このようにして、データが鎖のように連結されているイメージです。
線形リストの種類:単方向リスト、双方向リスト、循環リスト
単方向リスト(Singly Linked List)
最も基本的な線形リストです。各ノードは「データ」と「次のノードへのポインタ」のみを持ちます。リストの先頭から末尾に向かってのみ、順方向にしか移動できません。構造がシンプルで、メモリ使用量が少ないという利点があります。
双方向リスト(Doubly Linked List)
各ノードが「前のノードへのポインタ」と「次のノードへのポインタ」の両方を持つリストです。これにより、リストの前後両方向への移動が可能になります。単方向リストと比較して、特定のノードの削除や挿入がより効率的に行える反面、各ノードが2つのポインタを持つためメモリ消費量が増加します。
循環リスト(Circular Linked List)
リストの末尾ノードのポインタが先頭ノードを指すようにしたリストです。単方向リストと双方向リストの両方で循環構造を作ることができます。リングバッファや、複数のプロセスにCPU時間を均等に割り当てるラウンドロビンスケジューリングなどに利用されます。
線形リストの特徴:配列との比較で理解する
線形リストのメリット
1. 動的なサイズ変更: 配列と異なり、リストのサイズは実行時に自由に変更できます。新しい要素を追加する際に、メモリの再割り当てや大量のデータコピーが不要です。
2. 挿入と削除が高速: リストの先頭や中間に要素を挿入・削除する場合、ポインタの付け替えだけで完了します。配列のように、要素を詰めるためのシフト処理が不要です。
3. メモリの効率的利用: 配列は連続したメモリ領域を必要としますが、線形リストはメモリ上の空いている場所を断片的に利用できます。
線形リストのデメリット
1. ランダムアクセスが低速: 配列はインデックスを指定すれば即座に要素にアクセスできますが、線形リストは先頭から順にポインタをたどる必要があるため、特定の要素にアクセスするのにO(n)の時間がかかります。
2. ポインタのための追加メモリ: 各ノードがポインタを保持するため、データ自体以外にメモリを消費します。
3. キャッシュ効率の低下: ノードがメモリ上に分散して存在するため、CPUキャッシュのヒット率が低下し、大量データの連続アクセスでは配列より低速になる場合があります。
線形リストの主要操作と時間計算量
線形リストの基本的な操作には、検索、挿入、削除があります。それぞれの操作の時間計算量を理解することは、アルゴリズム設計において重要です。
検索(Search): 特定の値を持つノードを見つけるには、先頭から順にポインタをたどる必要があるため、平均でO(n)の時間がかかります。
先頭への挿入(Insert at Head): 新しいノードをリストの先頭に追加る場合、新しいノードのポインタを現在の先頭ノードに向け、リストの先頭ポインタを新しいノードに更新するだけなので、O(1)で実行できます。
末尾への挿入(Insert at Tail): 末尾にノードを追加する場合、末尾ノードまでたどる必要があるため、末尾ポインタを保持していなければO(n)の時間がかかります。末尾ポインタを常に保持する実装ではO(1)で可能です。
中間への挿入(Insert in Middle): 特定のノードの後に挿入する場合、そのノードを見つけるための検索にO(n)、ポインタの付け替え自体はO(1)です。
削除(Delete): 特定のノードを削除する場合も、削除対象のノードを見つける検索にO(n)かかります。双方向リストでは、削除対象ノードがわかっていればO(1)で削除できます。
線形リストの応用例:実際のソフトウェアでの使われ方
線形リストは、多くの実用的なソフトウェアやシステムで活用されています。代表的な応用例をいくつか紹介します。
1. ファイルシステム: 多くのオペレーティングシステムでは、ファイルのデータブロックを管理するために線形リストが使用されています。特に、ファイルが断片的に保存される場合、各ブロックをリンクトリストで連結して管理します。
2. 画像ビューアやメディアプレイヤー: 複数の画像や楽曲を連続して表示・再生するアプリケーションでは、再生リストの管理に双方向リストがよく使われます。「次へ」「前へ」の移動が効率的に行えます。
3. アンドゥ・リドゥ機能: テキストエディタやグラフィックソフトウェアの操作履歴を管理する際に、双方向リストが利用されます。各操作をノードとして保存し、アンドゥ(前のノードへ移動)とリドゥ(次のノードへ移動)を効率的に実現します。
4. グラフの隣接リスト表現: グラフ理論において、各頂点に隣接する頂点のリストを保持するために線形リストが使用されます。特に疎なグラフ(辺の数が少ないグラフ)では、メモリ効率が良くなります。
5. ハッシュテーブルのチェイン法: ハッシュテーブルで衝突が発生し場、同じハッシュ値を持つデータを線形リストで連結して管理する方法があります。
データ構造可視化プラットフォームの活用:線形リストを「見える化」する
線形リストの概念は、テキストや図だけでは理解が難しい場合があります。特に、ポインタの動きやノードの挿入・削除の過程を追うことは、初心者にとって大きな壁です。ここで役立つのが、データ構造とアルゴリズムの可視化学習プラットフォームです。
可視化プラットフォームの主な機能
1. アニメーションによる動作表示: ノードの挿入、削除、検索などの操作が、アニメーションでリアルタイムに表示されます。ポインタがどのように変化するか、ノードがどのように移動するかを視覚的に確認できます。
2. インタラクティブな操作: ユーザーが自分でデータを追加・削除し、その結果を即座に可視化できます。例えば、数値を入力して「挿入」ボタンを押すと、新しいノードがリストに追加される様子がアニメーションで表示されます。
3. ステップ実行機能: 複雑なアルゴリズム(例:線形リストを使ったマージソート)を1ステップずつ実行し、各ステップでのデータ構造の状態を確認できます。
4. コードと連動した表示: 実際のプログラムコード(C言語、Java、Pythonなど)と、そのコードが実行されるたびに変化するデータ構造の状態を同時に表示する機能もあります。コードとデータ構造の対応関係を理解するのに役立ちます。
5. 複数のデータ構造の比較: 同じ操作を配列と線形リストで行った場合のパフォーマンスの違いを、視覚的に比較できる機能も備えています。
可視化プラットフォームの利点
1. 直感的な理解: 抽象的な概念である「ポインタ」や「ノードの連結」が、視覚的に表示されることで、頭の中でイメージしやすくなります。
2. 誤解の防止: 「線形リストの挿入は配列より速い」という知識だけでは不十分です。なぜ速いのか、どのような状況で速いのかを、実際の動作を見ながら理解できます。
3. 自己学習の促進: 自分のペースで何度でも操作を試すことができ、間違えた場合もすぐにフィードバックを得られます。
4. デバッグスキルの向上: プログラムのバグを探す際に、データ構造の状態を可視化できると、問題の原因を特定しやすくなります。
可視化プラットフォームの具体的な使い方
まず、プラットフォームにアクセスし、「線形リスト(リンクトリスト)」のモジュールを選択します。次に、初期状態のリストが表示されます。画面上のボタンを使って、以下の操作を試してみてください。
1. ノードの追加: 「値」を入力し、「先頭に追加」または「末尾に追加」ボタンをクリックします。新しいノードが生成され、ポインタが自動的に接続される様子がアニメーションで表示されます。
2. ノードの削除: 削除したいノードをクリックして選択し、「削除」ボタンを押します。削除対象のノードを指していたポインタが、その次のノードに付け替えられ、対象ノードがリストから外れる過程が表示されます。
3. ノードの検索: 検索したい値を入力して「検索」ボタンを押ます。先頭のノードから順にポインタが移動し、目的のノードが見つかるまでの経路がハイライ表示されます。
4. アルゴリズムの実行: 例えば「リストの反転」アルゴリズムを選択すると、各ステップでポインタがどのように変化するかが、アニメーションで表示されます。
これらの操作を繰り返すことで、線形リストの動作原理が自然と身につきます。また、異なる種類のリスト(単方向、双方向、循環)を切り替えて比較することも可能です。
学習のポイント:線形リストをマスターするために
線形リストを完全に理解するためには、以下のポイントに注目して学習を進めると効果的です。
1. ポインタの概念を徹底的に理解する: ポインタは「次のノードの場所を示す矢印」です。この矢印の向きを変えることで、リストの構造が変わります。
2. 紙の上でシミュレーションする: 可視化プラットフォームを使う前に、紙とペンを使って自分でノードとポインタを書き、挿入や削除の操作を手動でシミュレーションしてみましょう。
3. エッジケースを意識する: 空のリストへの挿入、最後のノードの削除、1つだけのノードがあるリストでの操作など、特なケースでアルゴリズムが正しく動作するかを確認しましょう。
4. 実際にコードを書いてみる: 可視化プラットフォームで理解した内容を、実際にプログラミング言語で実装してみましょう。自分でコードを書くことで、理解が格段に深まります。
まとめ:可視化プラットフォームで線形リストをマスターしよう
線形リストは、データ構造とアルゴリズムの学習において、避けて通れない重要なテーマです。配列とは異なる特性を持ち、動的なデータ管理や頻繁な挿入・削除が必要な場面で力を発揮します。しかし、その仕組みは初心者にとって直感的に理解しにくい部分もあります。
データ構造可視化学習プラットフォームを活用することで、抽象的な概念を視覚的に捉え、実際の動作を体験しながら学習できます。アニメーション、インタラクティブな操作、コードとの連携などの機能により、線形リストの原理、特徴、応用を効率的に習得できるでしょう。ぜひ、このプラットフォームを使って、線形リストの理解を深めてください。次のステップとして、スタックやキューなどの応用データ構造の学習にも挑戦してみましょう。
按位序删除结点
该函数用于按位序删除节点的功能。具体来说,当参数 i 为 1 时,删除链表的 头节点;当 i 等于链表长度时,删除链表的 尾节点。
重点注意下链表为空和不为空时的处理逻辑

删除时链表空和不空时的区别
按位序删除结点 | 可视化完整可视化
2.3 双方向連結リスト詳解 - 線形リストチュートリアル アニメーションでコードを可視化しよう
データ構造とアルゴリズム学習に必須!「線形リスト(リンクトリスト)」とは?
プログラミングを学び始めて「配列」の次に登場するのが「線形リスト(リンクトリスト)」です。これは、データを鎖のように連結して管理するデータ構造です。本記事では、線形リストの仕組み、特徴、そして実際の応用例について、初心者の方にもわかりやすく解説します。さらに、データ構造とアルゴリズムの可視化学習プラットフォームを活用することで、なぜ理解が深まるのかについても詳しく説明します。
線形リストの基本原理:ポインタで繋がれたデータの列
線形リストは、「ノード」と呼ばれる要素が一列に並んだデータ構造です。各ノードは、自分が保持するデータ(値)と、次のノードを指し示す「ポインタ(参照)」という2つの部分から構成されます。配列のようにメモリ上に連続した領域を確保する必要がなく、各ノードはメモリ上の別々の場所に存在していても、ポンタでつなぐことで論理的な順序を表現します。
例えば、3つのノードA、B、Cがあるとします。ノードAはデータ「10」と次のノードBへのポインタを持ち、ノードBはデータ「20」と次のノードCへのポインタを持ち、ノードCはデータ「30」と「終端(NULL)」を示すポインタを持ちます。このようにして、データが鎖のように連結されているイメージです。
線形リストの種類:単方向リスト、双方向リスト、循環リスト
単方向リスト(Singly Linked List)
最も基本的な線形リストです。各ノードは「データ」と「次のノードへのポインタ」のみを持ちます。リストの先頭から末尾に向かってのみ、順方向にしか移動できません。構造がシンプルで、メモリ使用量が少ないという利点があります。
双方向リスト(Doubly Linked List)
各ノードが「前のノードへのポインタ」と「次のノードへのポインタ」の両方を持つリストです。これにより、リストの前後両方向への移動が可能になります。単方向リストと比較して、特定のノードの削除や挿入がより効率的に行える反面、各ノードが2つのポインタを持つためメモリ消費量が増加します。
循環リスト(Circular Linked List)
リストの末尾ノードのポインタが先頭ノードを指すようにしたリストです。単方向リストと双方向リストの両方で循環構造を作ることができます。リングバッファや、複数のプロセスにCPU時間を均等に割り当てるラウンドロビンスケジューリングなどに利用されます。
線形リストの特徴:配列との比較で理解する
線形リストのメリット
1. 動的なサイズ変更: 配列と異なり、リストのサイズは実行時に自由に変更できます。新しい要素を追加する際に、メモリの再割り当てや大量のデータコピーが不要です。
2. 挿入と削除が高速: リストの先頭や中間に要素を挿入・削除する場合、ポインタの付け替えだけで完了します。配列のように、要素を詰めるためのシフト処理が不要です。
3. メモリの効率的利用: 配列は連続したメモリ領域を必要としますが、線形リストはメモリ上の空いている場所を断片的に利用できます。
線形リストのデメリット
1. ランダムアクセスが低速: 配列はインデックスを指定すれば即座に要素にアクセスできますが、線形リストは先頭から順にポインタをたどる必要があるため、特定の要素にアクセスするのにO(n)の時間がかかります。
2. ポインタのための追加メモリ: 各ノードがポインタを保持するため、データ自体以外にメモリを消費します。
3. キャッシュ効率の低下: ノードがメモリ上に分散して存在するため、CPUキャッシュのヒット率が低下し、大量データの連続アクセスでは配列より低速になる場合があります。
線形リストの主要操作と時間計算量
線形リストの基本的な操作には、検索、挿入、削除があります。それぞれの操作の時間計算量を理解することは、アルゴリズム設計において重要です。
検索(Search): 特定の値を持つノードを見つけるには、先頭から順にポインタをたどる必要があるため、平均でO(n)の時間がかかります。
先頭への挿入(Insert at Head): 新しいノードをリストの先頭に追加る場合、新しいノードのポインタを現在の先頭ノードに向け、リストの先頭ポインタを新しいノードに更新するだけなので、O(1)で実行できます。
末尾への挿入(Insert at Tail): 末尾にノードを追加する場合、末尾ノードまでたどる必要があるため、末尾ポインタを保持していなければO(n)の時間がかかります。末尾ポインタを常に保持する実装ではO(1)で可能です。
中間への挿入(Insert in Middle): 特定のノードの後に挿入する場合、そのノードを見つけるための検索にO(n)、ポインタの付け替え自体はO(1)です。
削除(Delete): 特定のノードを削除する場合も、削除対象のノードを見つける検索にO(n)かかります。双方向リストでは、削除対象ノードがわかっていればO(1)で削除できます。
線形リストの応用例:実際のソフトウェアでの使われ方
線形リストは、多くの実用的なソフトウェアやシステムで活用されています。代表的な応用例をいくつか紹介します。
1. ファイルシステム: 多くのオペレーティングシステムでは、ファイルのデータブロックを管理するために線形リストが使用されています。特に、ファイルが断片的に保存される場合、各ブロックをリンクトリストで連結して管理します。
2. 画像ビューアやメディアプレイヤー: 複数の画像や楽曲を連続して表示・再生するアプリケーションでは、再生リストの管理に双方向リストがよく使われます。「次へ」「前へ」の移動が効率的に行えます。
3. アンドゥ・リドゥ機能: テキストエディタやグラフィックソフトウェアの操作履歴を管理する際に、双方向リストが利用されます。各操作をノードとして保存し、アンドゥ(前のノードへ移動)とリドゥ(次のノードへ移動)を効率的に実現します。
4. グラフの隣接リスト表現: グラフ理論において、各頂点に隣接する頂点のリストを保持するために線形リストが使用されます。特に疎なグラフ(辺の数が少ないグラフ)では、メモリ効率が良くなります。
5. ハッシュテーブルのチェイン法: ハッシュテーブルで衝突が発生し場、同じハッシュ値を持つデータを線形リストで連結して管理する方法があります。
データ構造可視化プラットフォームの活用:線形リストを「見える化」する
線形リストの概念は、テキストや図だけでは理解が難しい場合があります。特に、ポインタの動きやノードの挿入・削除の過程を追うことは、初心者にとって大きな壁です。ここで役立つのが、データ構造とアルゴリズムの可視化学習プラットフォームです。
可視化プラットフォームの主な機能
1. アニメーションによる動作表示: ノードの挿入、削除、検索などの操作が、アニメーションでリアルタイムに表示されます。ポインタがどのように変化するか、ノードがどのように移動するかを視覚的に確認できます。
2. インタラクティブな操作: ユーザーが自分でデータを追加・削除し、その結果を即座に可視化できます。例えば、数値を入力して「挿入」ボタンを押すと、新しいノードがリストに追加される様子がアニメーションで表示されます。
3. ステップ実行機能: 複雑なアルゴリズム(例:線形リストを使ったマージソート)を1ステップずつ実行し、各ステップでのデータ構造の状態を確認できます。
4. コードと連動した表示: 実際のプログラムコード(C言語、Java、Pythonなど)と、そのコードが実行されるたびに変化するデータ構造の状態を同時に表示する機能もあります。コードとデータ構造の対応関係を理解するのに役立ちます。
5. 複数のデータ構造の比較: 同じ操作を配列と線形リストで行った場合のパフォーマンスの違いを、視覚的に比較できる機能も備えています。
可視化プラットフォームの利点
1. 直感的な理解: 抽象的な概念である「ポインタ」や「ノードの連結」が、視覚的に表示されることで、頭の中でイメージしやすくなります。
2. 誤解の防止: 「線形リストの挿入は配列より速い」という知識だけでは不十分です。なぜ速いのか、どのような状況で速いのかを、実際の動作を見ながら理解できます。
3. 自己学習の促進: 自分のペースで何度でも操作を試すことができ、間違えた場合もすぐにフィードバックを得られます。
4. デバッグスキルの向上: プログラムのバグを探す際に、データ構造の状態を可視化できると、問題の原因を特定しやすくなります。
可視化プラットフォームの具体的な使い方
まず、プラットフォームにアクセスし、「線形リスト(リンクトリスト)」のモジュールを選択します。次に、初期状態のリストが表示されます。画面上のボタンを使って、以下の操作を試してみてください。
1. ノードの追加: 「値」を入力し、「先頭に追加」または「末尾に追加」ボタンをクリックします。新しいノードが生成され、ポインタが自動的に接続される様子がアニメーションで表示されます。
2. ノードの削除: 削除したいノードをクリックして選択し、「削除」ボタンを押します。削除対象のノードを指していたポインタが、その次のノードに付け替えられ、対象ノードがリストから外れる過程が表示されます。
3. ノードの検索: 検索したい値を入力して「検索」ボタンを押ます。先頭のノードから順にポインタが移動し、目的のノードが見つかるまでの経路がハイライ表示されます。
4. アルゴリズムの実行: 例えば「リストの反転」アルゴリズムを選択すると、各ステップでポインタがどのように変化するかが、アニメーションで表示されます。
これらの操作を繰り返すことで、線形リストの動作原理が自然と身につきます。また、異なる種類のリスト(単方向、双方向、循環)を切り替えて比較することも可能です。
学習のポイント:線形リストをマスターするために
線形リストを完全に理解するためには、以下のポイントに注目して学習を進めると効果的です。
1. ポインタの概念を徹底的に理解する: ポインタは「次のノードの場所を示す矢印」です。この矢印の向きを変えることで、リストの構造が変わります。
2. 紙の上でシミュレーションする: 可視化プラットフォームを使う前に、紙とペンを使って自分でノードとポインタを書き、挿入や削除の操作を手動でシミュレーションしてみましょう。
3. エッジケースを意識する: 空のリストへの挿入、最後のノードの削除、1つだけのノードがあるリストでの操作など、特なケースでアルゴリズムが正しく動作するかを確認しましょう。
4. 実際にコードを書いてみる: 可視化プラットフォームで理解した内容を、実際にプログラミング言語で実装してみましょう。自分でコードを書くことで、理解が格段に深まります。
まとめ:可視化プラットフォームで線形リストをマスターしよう
線形リストは、データ構造とアルゴリズムの学習において、避けて通れない重要なテーマです。配列とは異なる特性を持ち、動的なデータ管理や頻繁な挿入・削除が必要な場面で力を発揮します。しかし、その仕組みは初心者にとって直感的に理解しにくい部分もあります。
データ構造可視化学習プラットフォームを活用することで、抽象的な概念を視覚的に捉え、実際の動作を体験しながら学習できます。アニメーション、インタラクティブな操作、コードとの連携などの機能により、線形リストの原理、特徴、応用を効率的に習得できるでしょう。ぜひ、このプラットフォームを使って、線形リストの理解を深めてください。次のステップとして、スタックやキューなどの応用データ構造の学習にも挑戦してみましょう。