 图码
图码2.1 顺序表
💡 让我们以一个现实世界的例子来描述计算机中的数组。
想象你在一个图书馆,这个图书馆里有很多书架,每个书架上都有一排排的书。每本书都有一个特定的位置,你可以通过书架的编号和书的位置找到它。
在计算机中,数组就像这个图书馆中的书架一样。它是一个存储相同类型数据元素的数据结构。每个数据元素都有一个唯一的索引或位置,通过这个索引,你可以访问或修改特定位置的数据元素。
在计算机内存中,数组的元素是依次存储的,就像书架上的书一样。这样,计算机可以通过简单的数学运算来计算出元素的内存地址,从而快速访问数组中的任何元素。
数组是一种有效存储和访问大量相似数据的方式,就像图书馆中的书架一样可以帮助你组织和查找大量书籍。
数组是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。
数组中的元素存储在连续的内存位置中,并由一个索引(也称为下标)引用。下标是一个用于标识数组中的元素位置的序号。
2.1.1 数组的声明
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cnElemType:是我们要存放的数组元素的类型,类型可以是int, float,,double, char,或者其他可以使用的数据类型;
name:是用来表示数组的,称为数组名;
size:当前数组可以存放的最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn❗ 注意:
在本文后续中提到的所有
索引或下标 都是从 0 开始计数。
位序或第几个 都是从 1 开始计数。
在C 或者 C++ 中,数组索引从零开始。
第一个元素存储在array[0]中,第二个元素存储在array[1]中,以此类推。
因此,最后一个元素,即第6个元素,被存储在array[5]中。
在内存中,数组将如图所示进行存储。注意,方括号内写的0、1、2、3、4、5是下标。
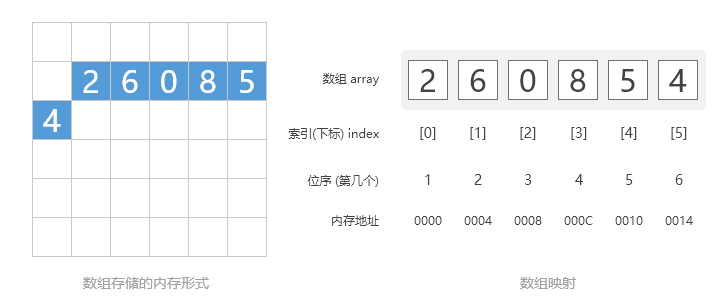
数组及内存结构
1 内存地址的计算
一个int类型的大小在内存中为4bytes。由于数组将其所有数据元素存储在连续的存储器位置中, 因此只需要知道数组首地址,即数组中第一个元素的地址就可以计算出该数组中其他元素的内存地址。
$$公式为:array[index] = base\_address + data\_type\_size \times index$$
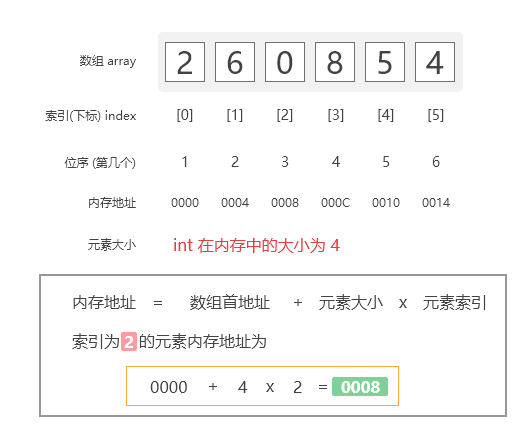
数组内存映射计算
由于数组元素是连续存储在内存的中的,所以我们可以很方便的访问任意一个元素。
就像你在图书馆的书架上查找一本特定的书时,如果你知道它的编号或位置,你可以直接走到该位置,而不必按顺序检查每本书。
在数组中访问元素是非常高效的,可以在$O(1)$时间内随机访问数组中的任意一个元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn在实际编码过程中,我们无需手动计算内存地址,因为每个元素占用大小相同的内存空间,数组元素的起始位置对于计算机也是已知的。 当我们在使用数组的下标来访问元素时,计算机可以通过上述的内存地址计算方法进行计算。
2 修改数组元素
需求:我们将index = 2即第 3 个元素的值修改为3。
操作步骤:
先找到$array[2]$的内存地址,使用上述公式:
$$\begin{split} array[2] &= base\_address + index \times data\_type\_size \\ \Rightarrow array[2] &= 0000 + 2 \times 4\\ \Rightarrow array[2] &= 0008 \end{split}$$
注意上面是计算内存地址,不是赋值
将内存地址为0xFFFF0008的值修改为3。
代码实现比较简单,计算机已自动帮助我们计算内存地址,我们只需提供对应的索引(index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn整个操作的时间复杂度为$O(1)$。
2.1.2 顺序表的介绍
💡 提示:
数组是一种数据结构,用于存储相同类型的元素的集合。
数组是一种顺序存储结构,元素在内存中按照一定的顺序依次存储。
那么数组和线性表的关系是什么呢?
线性表是一种数据结构,其中元素排列成一条线一样的顺序。
这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继。
线性表包括顺序表(数组实现)和链表等。
数组是一种实现线性表的方式之一。线性表可以通过数组来实现,也可以通过链表等其他结构来实现。
因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一。
通过数组实现的线性表称为顺序表。
1 顺序表的定义
线性表的顺序存储类型结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn定义了一个结构体SqList,包含两个成员变量:data和length。
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素。
2 顺序表的初始化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn这个函数的作用是将传入的顺序表 L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
2 在顺序表中插入元素
在顺序表中插入元素分为以下几种情况:
情况一:顺序表未满:插入在末尾
这种情况比较简单,我们只需要在当前最后一个元素的位置+1处直接赋值
例如:下面可视化窗口中的顺序表被声明为最大容量为10个元素,目前它存储了8个元素
步骤:
在末尾插入的位置为:9下标为:8 插入值5。
继续在末尾位置插入值:10
顺序表未满:插入末尾 | 可视化完整可视化
情况二:顺序表已满:不能再插入元素
上面可视化动画在插入了两个元素以后,顺序表总共有10个元素,那么我们将不能再向它添加元素,这种情况我们是不能进行插入的。
情况三:顺序表未满:插入在中间
如果想要在顺序表中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,给要插入的元素腾出位置,之后再把元素赋值给该索引。
步骤:
当前顺序表中已有8个元素,我们在下标为5位序为6处插入值10
注意代码中 i 为位序,不是下标
数组未满:插入在中间 | 可视化完整可视化
时间复杂度:
最好情况:如果插入操作发生在顺序表的末尾,并且顺序表有足够的空间,那么插入操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接在末尾添加元素不需要移动其他元素。
最坏情况:如果插入操作发生在顺序表的开头,需要将所有元素向后移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况: 平均情况下,需要移动插入位置后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
4 删除顺序表中的元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单。 我们只需要在当前存放元素的长度 -1 (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
步骤:
下面可视化面板中给出了最大容量为10的顺序表。
此时的顺序表内元素为{ 2, 6, 0, 8, 5, 4, 9, 8 },我们把下标为:3,位序为:4的元素删除掉。
❗ 注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它。
删除顺序表元素 | 可视化完整可视化
时间复杂度:
最好情况:如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素。
最差情况:如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况:平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序。
查找顺序表中的值 | 可视化完整可视化
2.1 순차 리스트 상세 설명 - 선형 리스트 튜토리얼 애니메이션으로 코드를 시각화하세요

선형 리스트(Linear List)와 순차 리스트(Sequential List) 완벽 가이드: 자료구조 시작하기
자료구조를 처음 배우는 많은 학생들이 가장 먼저 만나는 개념이 바로 '리스트(List)'입니다. 리스트는 데이터를 순서대로 저장하는 가장 기본적인 자료구조이며, 그중에서도 '순차 리스트(Sequential List)'는 배열(Array)을 기반으로 구현된 가장 직관적인 형태입니다. 이 글에서는 순차 리스트의 핵심 원리부터 실제 코딩 테스트와 개발 현장에서의 활용법까지, 초보자도 쉽게 이해할 수 있도록 자세히 설명합니다.
순차 리스트(Sequential List)란 무엇인가?
순차 리스트는 메모리상에 데이터를 연속적으로 저장하는 자료구조입니다. 쉽게 말해, 책장에 책을 빈틈없이 나란히 꽂아두는 것과 같습니다. 모든 데이터가 메모리상에서 한 줄로 붙어 있기 때문에, 특정 위치의 데이터를 찾을 때 매우 빠릅니다. 예를 들어, 3번째 데이터를 찾고 싶다면 배열의 시작 주소에서 (3-1)만큼만 이동하면 바로 접근할 수 있습니다. 이렇게 인덱스(Index)를 통해 직접 접근하는 방식을 '랜덤 액세스(Random Access)'라고 부릅니다.
순차 리스트는 프로그래밍 언어에서 가장 기본적인 배열(Array)과 동일한 개념으로 이해할 수 있습니다. C언어의 int arr[10], Java의 int[] arr, Python의 list 등이 모두 순차 리스트의 구현체입니다. 하지만 언어에 따라 내부 동작 방식이 조금씩 다를 수 있으므로, 자료구조의 본질적인 원리를 이해하는 것이 중요합니다.
순차 리스트의 핵심 특징과 장단점
순차 리스트의 가장 큰 특징은 '메모리 연속성'입니다. 모든 요소가 메모리 주소상에서 연속적으로 배치되어 있기 때문에, 다음과 같은 장점이 있습니다.
첫째, 데이터 접근 속도가 매우 빠릅니다. 인덱스만 알면 O(1) 시간 복잡도로 바로 데이터를 읽거나 쓸 수 있습니다. 이는 데이터 검색이 빈번한 애플리케이션에서 큰 강점이 됩니다.
둘째, 메모리 효율성이 높습니다. 각 데이터 사이에 추가적인 포인터(Link)를 저장할 필요가 없기 때문에, 데이터 자체만을 위한 순수한 메모리 공간만 사용합니다.
셋째, 캐시(Cache) 친화적입니다. 연속된 메모리 공간을 사용하기 때문에 CPU 캐시의 지역성(Locality) 원리를 잘 활용할 수 있어, 실제 실행 속도가 더욱 빨라집니다.
하지만 단점도 명확합니다. 데이터의 삽입과 삭제가 비효율적입니다. 배열 중간에 새로운 데이터를 추가하려면, 그 이후의 모든 데이터를 한 칸씩 뒤로 밀어야 합니다. 최악의 경우 O(n)의 시간이 소요됩니다. 또한, 배열의 크기가 고정되어 있어 런타임 중에 크기를 변경하기 어렵습니다. 미리 큰 배열을 할당하면 메모리가 낭비되고, 너무 작게 할당하면 데이터를 더 저장할 수 없게 됩니다.
순차 리스트의 기본 연산: 삽입, 삭제, 검색
순차 리스트에서 가장 중요한 연산은 크게 세 가지입니다. 먼저 '삽입(Insert)' 연산을 살펴보겠습니다. 리스트의 맨 끝에 데이터를 추가하는 것은 O(1)로 매우 간단합니다. 하지만 리스트의 맨 앞이나 중간에 데이터를 삽입하려면, 삽입 위치 이후의 모든 요소를 한 칸씩 뒤로 이동시켜야 합니다. 이때 데이터 이동 횟수는 n에 비례하므로 O(n)의 시간이 걸립니다.
'삭제(Delete)' 연산도 비슷합니다. 마지막 요소를 삭제하는 것은 O(1)이지만, 중간의 요소를 삭제하면 그 뒤의 모든 요소를 앞으로 한 칸씩 당겨와야 합니다. 삭제 역시 O(n)의 시간 복잡도를 가집니다.
'검색(Search)' 연산은 두 가지로 나눌 수 있습니다. 인덱스를 알고 있는 경우에는 O(1)로 바로 접근 가능합니다. 하지만 특정 값을 가진 데이터를 찾으려면, 처음부터 순차적으로 비교해야 하므로 O(n)의 시간이 소요됩니다. 단, 데이터가 정렬되어 있다면 이진 탐색(Binary Search)을 통해 O(log n)으로 검색 속도를 크게 향상시킬 수 있습니다.
순차 리스트의 실제 응용 사례
순차 리스트는 실무에서 매우 다양하게 사용됩니다. 첫 번째로, 데이터베이스 시스템에서 사용되는 '힙(Heap)' 자료구조의 기반이 됩니다. 힙은 배열을 사용하여 구현하며, 우선순위 큐(Priority Queue)의 핵심 구성 요소입니다.
두 번째로, 게임 프로그래밍에서 몬스터나 오브젝트를 관리할 때 사용됩니다. 고정된 개수의 오브젝트를 빠르게 접근해야 하는 상황에서 배열 기반의 순차 리스트가 탁월한 성능을 발휘합니다.
세 번째로, 그래픽스와 이미지 처리에서 픽셀 데이터를 저장할 때 필수적으로 사용됩니다. 2차원 배열은 사실상 순차 리스트의 확장판이며, 모든 이미지 데이터는 결국 1차원 배열로 메모리에 저장됩니다.
네 번째로, 운영체제의 프로세스 관리 테이블(PCB Table)에서도 순차 리스트가 사용됩니다. 각 프로세스에 고유한 인덱스(PID)를 부여하여 빠르게 접근할 수 있도록 합니다.
순차 리스트 vs 연결 리스트: 언제 무엇을 선택할까?
많은 학습자들이 순차 리스트와 연결 리스트(Linked List) 사이에서 혼란을 겪습니다. 두 자료구조의 선택 기준은 명확합니다. 데이터의 '읽기'가 빈번하고, 삽입/삭제가 거의 발생하지 않는다면 순차 리스트가 적합합니다. 반대로, 데이터의 삽입과 삭제가 매우 빈번하고, 특정 위치의 데이터를 자주 읽지 않는다면 연결 리스트가 더 좋은 선택입니다.
예를 들어, 학생 100명의 시험 점수를 저장하고 순위를 매기는 프로그램을 만든다면 순차 리스트가 좋습니다. 점수는 한 번 입력되면 거의 변경되지 않고, 빠른 접근이 필요하기 때문입니다. 반면, 쇼핑몰의 장바구니 기능을 구현한다면 연결 리스트가 더 적합합니다. 사용자가 상품을 계속 추가하고 삭제하기 때문입니다.
실제 개발에서는 두 자료구조를 혼합여 사용하는 경우도 많습니다. 예를 들어, Java의 ArrayList는 순차 리스트의 장점을 살리면서도, 내부적으로 배열을 재할당하여 동적으로 크기를 조절합니다. 이렇게 하면 대부분의 경우 빠른 접근 속도를 유지하면서, 삽입/삭제의 단점을 일부 보완할 수 있습니다.
순차 리스트 구현 시 주의할 점
순차 리스트를 직접 구현하거나 사용할 때 몇 가지 중요한 주의사항이 있습니다. 첫째, 배열의 인덱스 범위를 항상 확인해야 합니다. 대부분의 프로그래밍 언어에서 배열 인덱스는 0부터 시작하며, 할당된 크기를 벗어난 접근은 '버퍼 오버플로우(Buffer Overflow)'와 같은 심각한 오류를 발생시킬 수 있습니다.
둘째, 배열의 크기 변경이 필요할 때는 기존 배열보다 더 큰 새 배열을 할당하고, 모든 데이터를 복사한 후 기존 배열을 해제해야 합니다. 이 과정은 O(n)의 시간이 소요되므로, 너무 자주 발생하지 않도록 초기 배열 크기를 적절히 설정하는 것이 중요합니다.
셋째, 언어별로 배열의 동작 방식을 정확히 이해해야 합니다. C/C++에서는 배이 포인터와 밀접하게 연결되어 있고, Java에서는 배열이 객체로 취급됩니다. Python의 리스트는 사실 동적 배열(Dynamic Array)로 구현되어 있어, 일반적인 배열보다 더 많은 기능을 제공합니다.
데이터 구조 시각화 플랫폼으로 순차 리스트 학습하기
자료구조를 공부할 때 가장 어려운 부분 중 하나는 추상적인 개념을 머릿속으로 그리는 것입니다. 특히 순차 리스트에서 데이터가 이동하는 과정, 메모리 할당과 해제, 포인터의 변화 등을 텍스트만으로 이해하는 것은 매우 어렵습니다. 이때 '자료구조 시각화 플랫폼(Data Structure Visualization Platform)'이 큰 도움이 됩니다.
저희 플랫폼은 순차 리스트의 모든 연산을 실시간 애니메이션으로 보여줍니다. 사용자가 직접 데이터를 삽입하거나 삭제할 때마다, 메모리상에서 데이터가 어떻게 이동하는지, 인덱스가 어떻게 변화하는지, 시간 복잡도가 어떻게 적용되는지를 시각적으로 바로 확인할 수 있습니다.
예를 들어, 리스트의 3번 위치에 새로운 숫자 42를 삽입하는 과정을 시뮬레이션하면, 화면에서 3번 이후의 모든 요소가 한 칸씩 뒤로 밀리는 모습을 애니메이션으로 보여줍니다. 동시에 '이동 횟수', '시간 복잡도', '메모리 사용량' 등의 지표가 실시간으로 업데이트되어, 추상적인 개념을 구체적인 수치로 확인할 수 있습니다.
시각화 플랫폼의 주요 기능과 활용 방법
저희 플랫폼은 단순한 시각화를 넘어, 학습 효율을 극대화하기 위한 다양한 기능을 제공합니다. 첫 번째 기능은 '단계별 실행(Step-by-Step Execution)'입니다. 한 번에 모든 연산이 실행되는 것이 아니라, 사용자가 '다음 단계' 버튼을 누를 때마다 한 단계씩 진행됩니다. 이를 통해 각 단계에서 어떤 일이 발생하는지 충분히 관찰하고 이해할 수 있습니다.
두 번째 기능은 '속도 조절'입니다. 초보자는 느린 속도로 천천히 따라가면서 이해하고, 숙련자는 빠른 속도로 전체 흐름을 복습할 수 있습니다. 또한, 특정 지점에서 일시 정지하여 현재 상태를 자세히 분석할 수도 있습니다.
세 번째 기능은 '코드 연동'입니다. 화면 왼쪽에는 시각화된 자료구조가, 오른쪽에는 실제 실행되는 코드가 함께 표시됩니다. 사용자가 시각화 화면에서 데이터를 조작하면, 해당하는 코드가 자동으로 하이라이트됩니다. 반대로, 코드를 직접 수정하면 시각화 화면이 즉시 업데이트됩니다. 이렇게 코드와 시각화를 동시에 학습하면, 추상적인 코드가 실제로 어떻게 동작하는지 완벽하게 이해할 수 있습니다.
네 번째 기능은 '오류 시뮬레이션'입니다. 일부러 잘못된 연산(예: 빈 리스트에서 데이터 삭제, 배열 범위를 초과한 인덱스 접근)을 수행하면, 어떤 오류가 발생하고 왜 그런 오류가 발생하는지를 시각적으로 보여줍니다. 이를 통해 실무에서 자주 발생하는 실수를 미리 경험하고 예방할 수 있습니다.
순차 리스트 학습 로드맵: 초급부터 고급까지
저희 플랫폼을 활용한 효과적인 학습 방법을 단계별로 소개합니다. 1단계에서는 '기본 조작'을 익힙니다. 순차 리스트를 생성하고, 데이터를 추가하고, 특정 위치의 데이터를 읽고, 데이터를 수정하는 기본적인 연산을 시각화와 함께 반복 학습합니다.
2단계에서는 '삽입과 삭제'에 집중합니다. 리스트의 맨 앞, 중간, 맨 끝에 데이터를 삽입하고 삭제할 때의 시간 차이를 직접 관찰합니다. 각 연산이 완료된 후의 메모리 상태 변화를 면밀히 살펴보면서, 왜 중간 삽입이 느린지 체감할 수 있습니다.
3단계에서는 '동적 배열'의 개념을 학습합니다. 고정 크기 배열의 한계를 경험한 후, 크기가 자동으로 늘어나는 동적 배열을 구현해 봅니다. 배열이 가득 찼을 때 새로운 배열을 할당하고 데이터를 복사하는 과정을 시각화하여, '재할당(Reallocation)'의 개념을 명확히 이해합니다.
4단계에서는 '응용 문제'를 풀어봅니다. 순차 리스트를 활용한 다양한 알고리즘 문제(예: 구간 합 구하기, 슬라이딩 윈도우, 투 포인터)를 시각화 플랫폼 위에서 직접 코딩하고 실행해 봅니다. 실제 코딩 테스트와 유사한 환경에서 연습할 수 있어 실전 감각을 키울 수 있습니다.
순차 리스트의 성능 최적화 기법
순차 리스트를 실제 프로젝트에서 사용할 때 성능을 최적화하는 몇 가지 고급 기법이 있습니다. 첫 번째는 '메모리 풀(Memory Pool)' 기법입니다. 미리 큰 메모리 블록을 할당해 두고, 필요할 때마다 조각조각 사용하는 방식입니다. 이렇게 하면 메모리 할당과 해제에 드는 오버헤드를 크게 줄일 수 있습니다.
두 번째는 '지연 삭제(Lazy Deletion)'입니다. 데이터를 실제로 삭제하지 않고, 삭제되었다는 표시만 해둡니다. 나중에 한꺼번에 정리하는 방식으로, 삭제 연산의 비용을 분산시킬 수 있습니다. 데이터베이스 시스템에서 자주 사용하는 기법입니다.
세 번째는 '루프 언롤링(Loop Unrolling)'입니다. 배열을 순회할 때 반복문의 조건 검사 횟수를 줄이기 위해, 한 번에 여러 개의 데이터를 처리하는 기법입니다. 컴파일러 최적화와 함께 사용하면 성능을 크게 향상시킬 수 있습니다.
네 번째는 '캐시 최적화'입니다. 배열의 접근 패턴을 CPU 캐시에 맞게 조정합니다. 예를 들어, 2차원 배열을 순회할 때 행 우선(Row-major) 방식으로 접근하면 열 우선(Column-major) 방식보다 캐시 효율이 훨씬 높아집니다.
순차 리스트와 관련된 주요 알고리즘
순차 리스트를 기반으로 동작하는 중요한 알고리즘들을 함께 학습하면 시너지 효과를 얻을 수 있습니다. 첫 번째는 '정렬 알고리즘'입니다. 퀵 정렬(Quick Sort), 병합 정렬(Merge Sort), 힙 정렬(Heap Sort) 등 대부분의 정렬 알고리즘은 배열을 기반으로 동작합니다. 시각화 플랫폼에서 각 정렬 알고리즘이 배열의 요소를 어떻게 비교하고 교환하는지 관찰하면, 알고리즘의 원리를 훨씬 쉽게 이해할 수 있습니다.
두 번째는 '탐색 알고리즘'입니다. 이진 탐색(Binary Search)은 정렬된 배열에서만 사용할 수 있지만, O(log n)의 매우 빠른 속도를 자랑합니다. 선형 탐색(Linear Search)과 이진 탐색의 차이를 시각화 플랫폼에서 직접 비교해 보면, 알고리즘의 효율성을 체감할 수 있습니다.
세 번째는 '구간 트리(Segment Tree)'와 '펜윅 트리(Fenwick Tree)'입니다. 이 고급 자료구조들은 모두 배열을 기반으로 구현되며, 구간 합이나 구간 최대/최소값을 빠르게 계산하는 데 사용됩니다. 순차 리스트의 기본 개념을 확실히 이해한 후에 도전하면 좋습니다.
자주 하는 질문과 오해
순차 리스트를 공부할 때 많은 학생들이 하는 질문들을 정리했습니다. 첫째, "배열과 순차 리스트는 완전히 같은 것인가요?" 엄밀히 말하면, 배열은 순차 리스트를 구현하는 하나의 방법입니다. 하지만 대부분의 프로그래밍 언어에서 배열은 순차 리스트의 특성을 그대로 가지므로, 실무에서는 같은 개념으로 봐도 무방합니다.
둘째, "Python의 리스트는 왜 배열처럼 동작하나요?" Python의 리스트는 사실 동적 배열(Dynamic Array)로 구현되어 있습니다. 내부적으로는 연속된 메모리 공간을 사용하지만, 크기가 자동으로 조절된다는 점에서 전통적인 배열과 다릅니다. 하지만 인덱스 접근이 O(1)이라는 점은 동일합니다.
셋째, "순차 리스트는 언제나 나쁜 선택인가요?" 절대 그렇지 않습니다. 데이터의 크기가 고정되어 있거나, 삽입/삭제보다 읽기 연산이 훨씬 많다면 순차 리스트가 최고의 선택입니다. 또한, 메모리가 제한된 임베디드 시스템에서는 연결 리스트의 포인터 오버헤드가 부담스러울 수 있으므로, 순차 리스트가 더 적합합니다.
넷째, "어떤 자료구조를 먼저 배워야 하나요?" 자료구조 학습의 표준 로드맵은 순차 리스트 → 연결 리스트 → 스택/큐 → 트리 → 그래프 순서입니다. 순차 리스트는 가장 기본이 되는 자료구조이므로, 반드시 먼저 완벽하게 이해하고 넘어가야 합니다.
마치며: 시각화 플랫폼으로 자료구조 마스터하기
자료구조와 알고리즘은 이론으로만 공부해서는 절대 실력이 늘지 않습니다. 직접 코드를 작성해 보고, 눈으로 데이터가 움직이는 모습을 보면서 직관을 키워야 합니다. 저희 데이터 구조 시각화 학습 플랫폼은 이러한 과정을 가장 효율적으로 도와주는 도구입니다.
순 리스트 하나만 제대로 이해해도, 이후에 배울 모든 자료구조의 기초가 탄탄해집니다. 지금 바로 플랫폼에 접속하여, 직접 배열을 만들고 데이터를 삽입하고 삭제해 보세요. 눈앞에서 펼쳐지는 데이터의 움직임을 보면서, 자료구조가 단순한 이론이 아니라 살아 움직이는 도구임을 느낄 수 있을 것입니다.
앞으로도 저희 플랫폼은 순차 리스트를 포함한 모든 주요 자료구조와 알고리즘에 대한 상세한 시각화 자료를 지속적으로 업데이트할 예정입니다. 함께 배우고 성장하는 커뮤니티가 되어, 모두가 자료구조 마스터가 되는 그날까지 최선을 다해 지원하겠습니다.
时间复杂度:
最好情况:要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为$O(1)$,即常数时间复杂度。
最坏情况:要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中。在这种情况下,时间复杂度为$O(n)$,其中$n$是顺序表中元素的个数。
平均情况:平均情况的时间复杂度通常是$O(\frac n 2)$,因为平均而言,我们可以认为要查找的元素在顺序表的中间位置。但是在大$O$表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是$O(n)$。
2.1.3 顺序表数组实现的优点与缺点
1 优点
随机访问速度快:由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 $O(1)$。这使得数组在需要频繁随机访问元素的情况下非常高效。
节约空间:相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间。
缓存友好:由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势。
2 缺点
固定大小:数组的大小是固定的,一旦创建后就不能动态改变。如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销。
插入和删除操作效率低:在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 $O(n)$。这使得数组在频繁插入和删除操作的场景下效率较低。
不适合存储变长数据:由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求。