 图码
图码2.4 循环链表
循环链表是一种数据结构,其中最后一个节点的next连接回到第一个节点,形成一个循环。此结构允许连续遍历而不会中断。
循环链表对于日程安排和音乐播放列表等任务特别有用,这允许播放完毕后回到第一首继续播放。
在这小节中,我们将介绍循环链表的基础知识、如何使用它们、它们的优点和缺点以及它们的应用。
什么是循环链表?
循环链表是一种特殊类型的链表,其中所有节点都连接起来形成一个环。
与我们前面讲到的链表不同的是,循环链表中的最后一个节点的next指向第一个节点。这意味着当遍历到尾部时可以继续向头部遍历。
循环链表是从单链表和双链表扩展出来的,因此,循环链表基本只有这两种类型。
循环单链表
在循环单链表中,每个节点只有一个指针,称为next指针。 最后一个节点的next指针指向第一个节点,这样就形成了一个环。在循环单链表中,我们只能沿一个方向遍历链表。
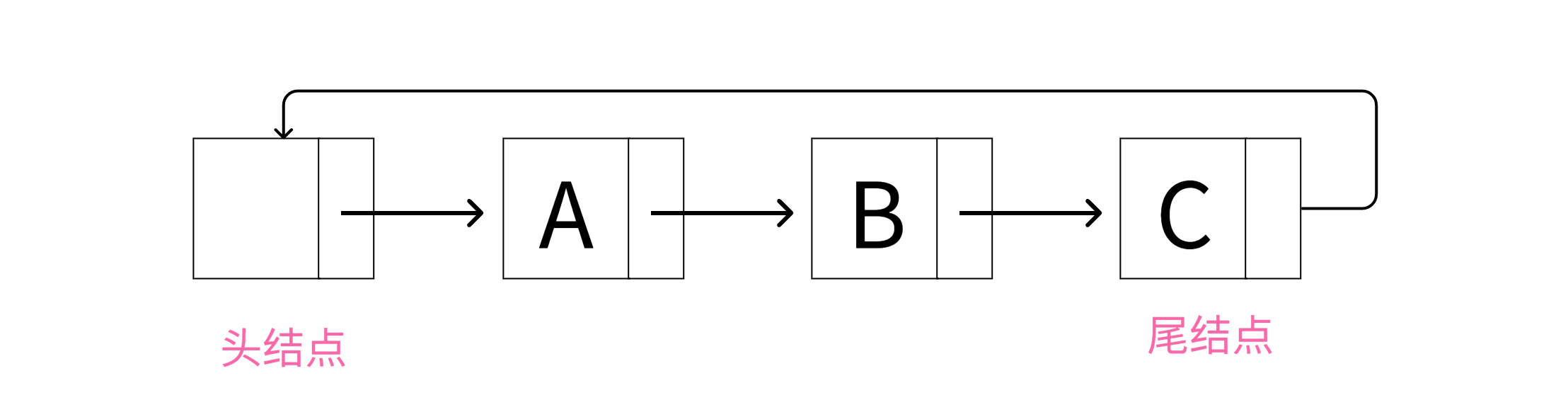
循环单链表结构
数据结构
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
typedef struct LNode {
int data;
struct LNode* next;
} LNode, *LinkList;
LNode* pTemp = (LNode*)malloc(sizeof(LNode));
pTemp->data = e;
pTemp->next = p->next; // 将新节点的next指向p的下一个节点
p->next = pTemp; // 更新p的next指向新节点,完成插入操
// 完整代码:https://totuma.cn- data:数据域,也是节点的值
- next:指针域,指向下一个结点的指针
在上面的定义中,每个节点都有data数据域和next指针域,和普通的单链表结构一模一样,唯一区别就是当我们为循环链表创建多个节点时,我们只需要将最后一个节点连接回第一个节点即可。
循环单链表的基本操作实现
创建循环单链表
插入是链表中的基本操作。和普通单链表的唯一区别是将最后一个节点的next连接到第头结点。
插入大概可以分为以下三种情况
1.在空链表中插入新结点
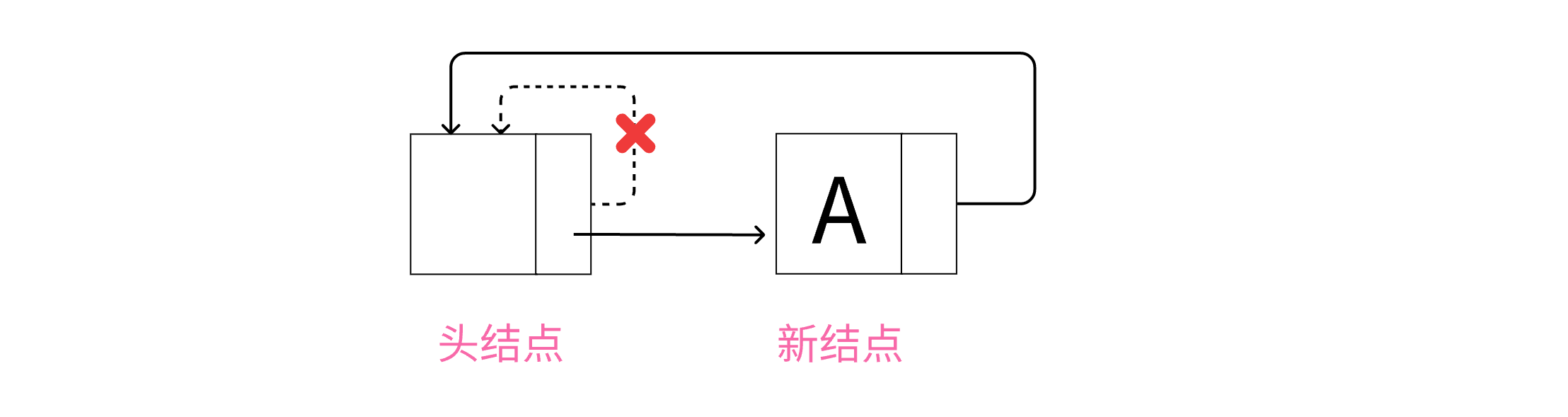
在空链表中插入新结点
这里使用的是带头结点的单链表来实现循环链表,所以链表空的条件是头结点的next指向头结点,即头结点自己指向自己。
在空的循环链表中插入一个节点,需要创建一个新结点,将其next指针指向头结点,以达到循环的目的。
2.在链表中部插入新结点
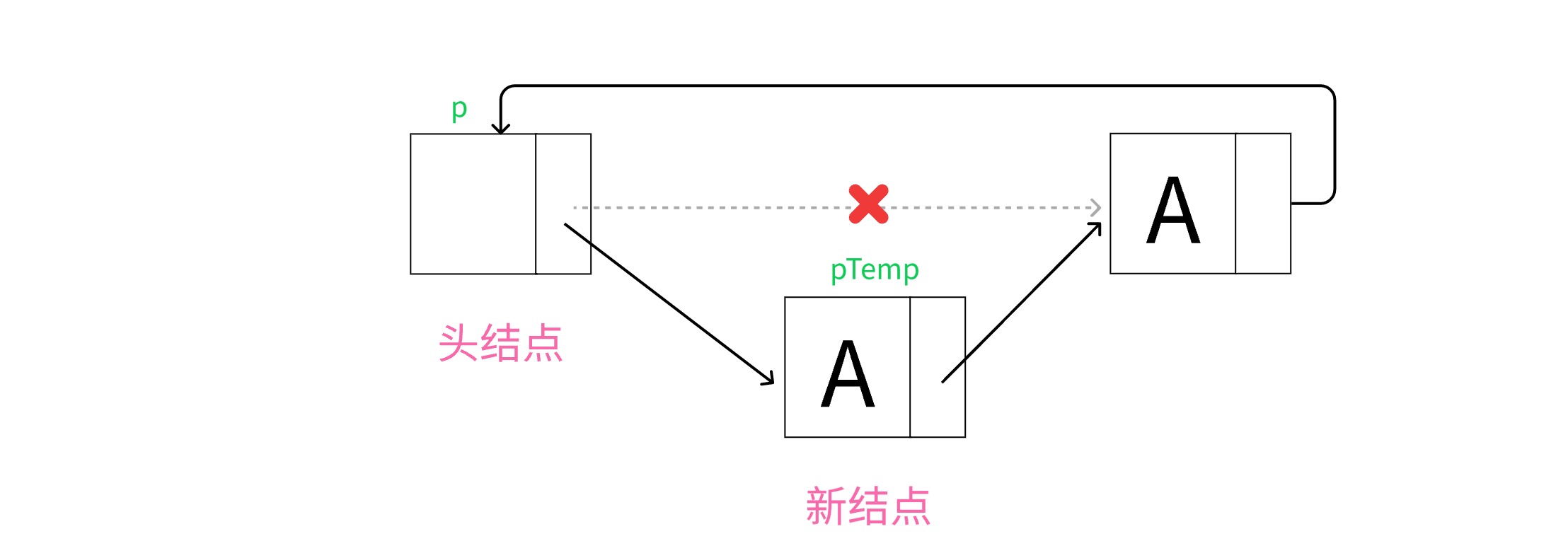
在链表中部插入新结点
和普通单链表操作一样,在中部插入结点并没有改变尾结点next的指向。
3.在链表尾部插入新结点
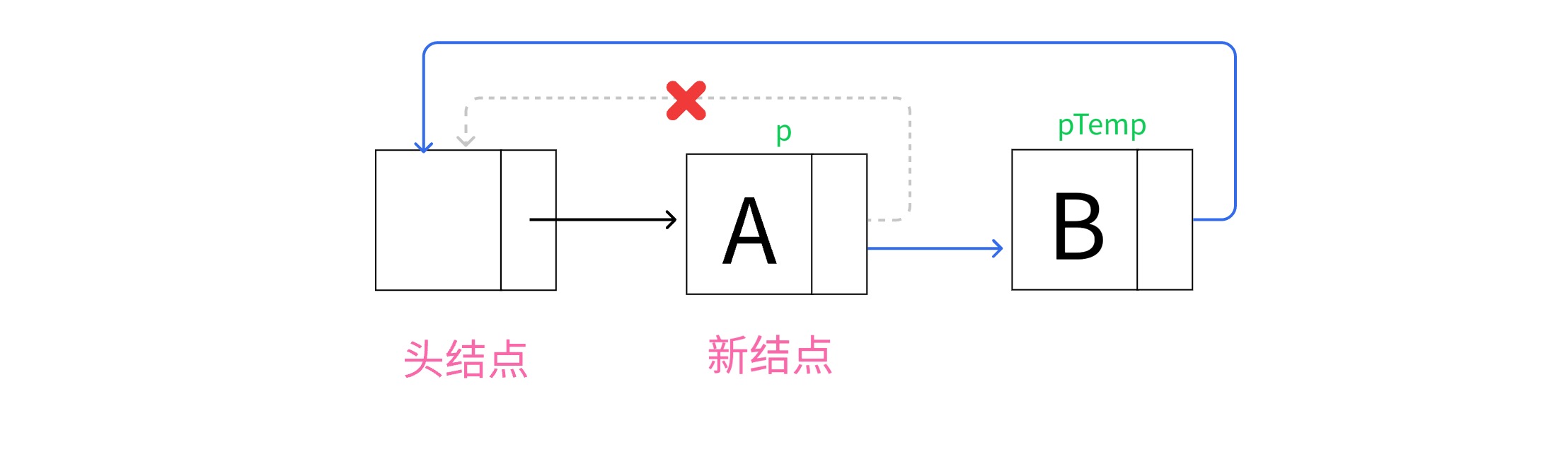
在链表尾部插入新结点
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
typedef struct LNode {
int data;
struct LNode* next;
} LNode, *LinkList;
LNode* pTemp = (LNode*)malloc(sizeof(LNode));
pTemp->data = e;
pTemp->next = p->next; // 将新节点的next指向p的下一个节点
p->next = pTemp; // 更新p的next指向新节点,完成插入操
// 完整代码:https://totuma.cn上面三种情况,都可以统一为同一操作:
1.找到待插入位置的前驱结点,即p;
2.创建新结点pTemp;
3.使pTemp的next指向p的next;
(如果是空链表,那么p的next指向头结点本身。如果是在末尾插入,p的next同样也是指向头结点)
4.使p的next指向pTemp;
按位序插入结点 | 可视化完整可视化
2.4 순환 단일 연결 리스트 상세 설명 - 선형 리스트 튜토리얼 애니메이션으로 코드를 시각화하세요

선형 리스트와 연결 리스트: 자료구조 시각화 학습 가이드
자료구조와 알고리즘을 처음 공부할 때 많은 학습자가 '선형 리스트(Linear List)'와 '연결 리스트(Linked List)'의 차이점에서 혼란을 느낍니다. 이 글에서는 두 개념의 핵심 원리와 실제 응용 사례를 쉬운 언어로 풀어내고, 시각화 학습 플랫폼을 통해 어떻게 효과적으로 익힐 수 있는지 자세히 설명합니다. 특히 한국어 사용자를 위해 번역체가 아닌 자연스러운 표현을 사용했으며, 검색 엔진이 내용을 잘 이해할 수 있도록 구조화했습니다.
1. 선형 리스트(Linear List)란 무엇인가?
선형 리스트는 데이터를 일렬로 나열한 가장 기본적인 자료구조입니다. 배열(Array)이 대표적인 예이며, 모든 요소가 메모리상에 연속적으로 저장됩니다. 예를 들어 int arr[5] = {10, 20, 30, 40, 50}과 같이 선언하면 10, 20, 30, 40, 50이 메모리 주소 1000, 1004, 1008, 1012, 1016에 차례대로 위치합니다.
장점: 인덱스를 사용하여 특정 위치의 데이터를 즉시 조회할 수 있습니다(시간복잡도 O(1)). 예를 들어 arr[3]을 호출하면 40을 바로 얻을 수 있습니다. 또한 캐시 지역성이 높아 순차 접근 속도가 빠릅니다.
단점: 크기가 고정되어 있어 실행 중에 크기를 변경하기 어렵습니다. 중간에 데이터를 삽입하거나 삭제할 때는 뒤에 있는 모든 요소를 이동시켜야 하므로 O(n)의 시간이 소요됩니다. 예를 들어 10, 20, 30, 40, 50에서 20과 30 사이에 25를 넣으려면 30, 40, 50을 한 칸씩 뒤로 밀어야 합니다.
2. 연결 리스트(Linked List)의 개념과 동작 원리
연결 리스트는 노드(Node)라고 불리는 단위가 포인터(Pointer)로 서로 연결된 구조입니다. 각 노드는 데이터를 저장하는 필드와 다음 노드를 가리키는 링크(Link) 필드로 구성됩니다. 첫 번째 노드는 헤드(Head)라고 부르며, 마지막 노드의 링크는 NULL을 가리킵니다.
단일 연결 리스트(Singly Linked List): 한 방향으로만 이동할 수 있습니다. head → [10|next] → [20|next] → [30|NULL] 형태입니다. 특정 위치에 데이터를 삽입하려면 앞 노드의 링크를 새 노드로 바꾸고 새 노드의 링크를 다음 노드로 설정하면 됩니다. 배열과 달리 요소 이동이 필요 없으므로 O(1)에 삽입이 가능합니다(단, 삽입 위치를 찾는 탐색은 O(n)).
이중 연결 리스트(Doubly Linked List): 각 노드가 이전 노드와 다음 노드를 모두 가리키는 링크를 가집니다. head ↔ [prev|10|next] ↔ [prev|20|next] ↔ [prev|30|NULL] 형태입니다. 양방향 탐색이 가능하여 특정 노드의 앞뒤를 쉽게 알 수 있습니다.
원형 연결 리스트(Circular Linked List): 마지막 노드의 링크가 첫 번째 노드를 가리킵니다. head → [10|next] → [20|next] → [30|next] → head. 이 구조는 순환 큐나 음악 플레이리스트처럼 반복 순회가 필요한 상황에 유용합니다.
3. 선형 리스트와 연결 리스트의 비교 분석
두 자료구조는 각기 다른 트레이드오프를 가집니다. 아래는 핵심 차이점입니다.
메모리 사용: 배열은 데이터만 저장하지만 연결 리스트는 링크 필드를 위해 추가 메모리를 사용합니다. 예를 들어 정수형 데이터 1,000개를 저장할 때 배열은 4KB(4바이트*1000)면 충분하지만, 연결 리스트는 링크 포인터(8바이트)까지 포함해 약 12KB가 필요합니다.
접근 속도: 배열은 인덱스로 O(1)에 접근할 수 있습니다. 반면 연결 리스트는 k번째 노드에 접근하려면 head부터 k번 이동해야 하므로 O(n)이 걸립니다. 따라서 빈번한 검색이 필요한 작업에는 배열이 유리합니다.
삽입/삭제: 배열은 중간 삽입 시 O(n)의 이동 비용이 들지만, 연결 리스트는 링크 조작만으로 O(1)에 처리할 수 있습니다(노드 위치를 알고 있을 경우). 예를 들어 실시간 게임에서 플레이어 목록을 자주 추가/제거해야 한다면 연결 리스트가 적합합니다.
캐시 지역성: 배열은 연속 메모리이므로 CPU 캐시 효율이 높습니다. 연결 리스트는 노드가 메모리 곳곳에 흩어져 있어 캐시 미스가 자주 발생할 수 있습니다. 대규모 데이터를 순차적으로 읽을 때 배열이 2~5배 더 빠를 수 있습니다.
4. 연결 리스트의 주요 응용 분야
연결 리스트는 다양한 실전 시스템에서 핵심 역할을 합니다. 몇 가지 대표적인 사례를 살펴보겠습니다.
운영체제의 프로세스 스케줄링: 라운드 로빈(Round Robin) 방식에서 준비 큐(Ready Queue)는 원형 연결 리스트로 구현됩니다. 각 프로세스가 일정 시간 동안 CPU를 사용하고 다음 프로세스로 넘어갈 때, 리스트의 head를 이동시키기만 하면 됩니다.
이미지 편집기의 실행 취소(Undo) 기능: 사용자의 작업 내역을 이중 연결 리스트로 저장합니다. Ctrl+Z를 누르면 현재 노드의 이전 노드로 이동하고, Ctrl+Y를 누르면 다음 노드로 이동합니다. 이때 리스트의 양방향 특성이 매우 유용합니다.
음악 재생 플레이리스트: 사용자가 다음 곡이나 이전 곡을 선택할 때 원형 연결 리스트를 사용하면 마지막 곡에서 첫 곡으로 자연스럽게 넘어갈 수 있습니다. 또한 특정 곡을 추가하거나 제거할 때도 연결 리스트의 삽입/삭제가 효율적입니다.
브라우저 방문 기록: 사용자가 뒤로 가기/앞으로 가기 버튼을 누를 때마다 이중 연결 리스트의 노드 이동이 발생합니다. 각 노드는 방문한 URL과 타임스탬프를 저장합니다.
해시 테이블의 체이닝(Chaining): 해시 충돌을 해결하기 위해 각 버킷(Bucket)에 연결 리스트를 사용합니다. 동일한 해시 값을 가진 데이터를 리스트로 결하여 저장합니다.
5. 연결 리스트의 변형과 고급 개념
기본 연결 리스트 외에도 다양한 변형이 존재합니다. 학습자는 이를 이해하면 더 복잡한 알고리즘을 다룰 수 있습니다.
헤드 포인터가 없는 연결 리스트: 첫 번째 노드가 항상 특별한 값을 가지는 더미 노드(Dummy Node)를 사용하는 경우도 있습니다. 이렇게 하면 빈 리스트나 첫 번째 노드 삭제를 일반화된 코드로 처리할 수 있습니다.
블록 연결 리스트(Unrolled Linked List): 각 노드가 여러 개의 데이터를 저장하는 배열을 가집니다. 예를 들어 한 노드에 16개의 정수를 저장하고, 노드 간에는 포인터로 연결합니다. 이 구조는 캐시 지역성과 삽입/삭제 성능 사이의 균형을 제공합니다.
스킵 리스트(Skip List): 연결 리스트에 다중 레벨 인덱스를 추가한 자료구조입니다. 검색 시간이 O(log n)으로 향상되며, 레디스(Redis)와 같은 고성능 데이터베이스에서 사용됩니다.
6. 시각화 학습 플랫폼의 필요성
연결 리스트는 추상적인 포인터 개념이 많아 초보자가 머릿속으로 그리기 어렵습니다. 예를 들어 '노드의 next를 temp에 저장하고, prev의 next를 새 노드로 바꾼다'는 설명만으로는 정확한 동작을 이해하기 힘듭니다. 이때 시각화 플랫폼이 큰 도움이 됩니다.
시각화 도구는 각 노드를 박스로 표현하고, 포인터를 화살표로 나타내어 데이터의 이동을 실시간으로 보여줍니다. 사용자가 삽입, 삭제, 탐색 버튼을 클릭할 때마다 메모리 상태가 어떻게 변하는지 애니메이션으로 확인할 수 있습니다. 이는 '보면서 배우는 학습(Visual Learning)' 효과를 극대화합니다.
7. 자료구조 시각화 플랫폼의 주요 기능
효과적인 시각화 플랫폼은 다음과 같은 기능을 제공해야 합니다.
단계별 실행(Step-by-Step Execution): 사용자가 한 줄의 코드나 한 번의 연산을 실행할 때마다 자료구조의 상태가 업데이트됩니다. 예를 들어 '노드 3을 위치 2에 삽입'을 선택하면, 먼저 새 노드가 생성되고, 링크가 변경되는 과정을 한 프레임씩 볼 수 있습니다.
메모리 뷰(Memory View): 각 노드가 실제 메모리 주소(가상)에 어떻게 배치되는지 보여줍니다. 배열과 달리 연결 리스트의 노드가 불연속적으로 위치한다는 점을 직관적으로 이해할 수 있습니다.
코드 연동(Code Sync): 사용자가 파이썬, 자바, C++ 등 특정 언어로 작성한 코드가 실행될 때, 해당 코드 라인이 하이라이트되고 자료구조가 동시에 변합니다. 예를 들어 'node.next = prev.next'라는 코드가 실행되면 화살표가 실제로 이동하는 것을 볼 수 있습니다.
사용자 정의 데이터: 학습자가 직접 데이터 값을 입력하거나 노드 개수를 조절할 수 있어야 합니다. 5개의 노드로 테스트하다가 100개의 노드로 확장했을 때 성능 차이를 체감할 수 있습니다.
오류 시뮬레이션: 의도적으로 NULL 포인터 역참조나 무한 루프 상황을 만들어보고, 디버깅하는 과정을 시각화할 수 있습니다. 이는 실제 프로그래밍에서 발생할 수 있는 버그를 예방하는 데 도움이 됩니다.
8. 플랫폼을 활용한 학습 방법
다음은 시각화 플랫폼을 최대한 활용하는 구체적인 학습 로드맵입니다.
1단계: 기본 구조 익히기 - 단일 연결 리스트의 노드 생성, head 설정, NULL 처리 등 기본 개념을 시각화 도구로 10번 정도 반복해서 살펴봅니다. 각 노드의 next 포인터가 어떻게 연결되는지 손으로 따라 그려보는 것도 좋습니다.
2단계: 핵심 연습 문제 풀기 - "리스트의 끝에 노드 추가", "특정 값을 가진 노드 삭제", "리스트 뒤집기" 같은 기본 연산을 시각화하면서 직접 구현해봅니다. 플랫폼의 '단계별 실행' 기능을 켜고 한 줄 한 줄 확인합니다.
3단계: 고급 알고리즘 시각화 - 두 리스트의 병합, 중간 노드 찾기(토끼와 거북이 알고리즘), 사이클 탐지(Floyd's Cycle Detection) 등을 시각화합니다. 특히 사이클이 있는 리스트에서 포인터가 어떻게 움직이는지 애니메이션으로 보면 이해도가 훨씬 높아집니다.
4단계: 실제 코드와 비교 - 플랫폼에서 제공하는 코드 템플릿을 자신이 사용하는 언어로 변환해보고, 동일한 시각화 결과가 나오는지 확인합니다. 예를 들어 파이썬으로 구현한 연결 리스트와 자바로 구현한 연결 리스트의 시각화를 비교해볼 수 있습니다.
5단계: 성능 측정 - 플랫폼의 '데이터 크기 조절' 기능을 이용해 노드가 10개, 100개, 1000개일 때 삽입/삭제 시간을 측정합니다. 배열과 연결 리스트의 차이를 직접 눈으로 확인하면 빅오 표기법이 더 와닿습니다.
9. 시각화 플랫폼의 기술적 장점
이 플랫폼은 단순한 그림이 아니라 실제 실행 엔진을 기반으로 합니다. 내부적으로는 자바스크립트로 구현된 가상 메모리 모델이 동작하며, 사용자의 모든 조작이 즉시 반영됩니다. 예를 들어 사용자가 '노드 삭제' 버튼을 누르면, 가비지 컬렉션(Garbage Collection) 시뮬레이션까지 보여주어 메모리 관리 개념까지 함께 학습할 수 있습니다.
또한 모든 시각화는 HTML5 Canvas 위에 렌더링되므로 별도의 플러그인 설치 없이 웹 브라우저에서 바로 실행됩니다. 모바일 환경에서도 터치 제스처를 지원하여 태블릿으로도 학습이 가능합니다.
10. 학습자에게 추천하는 추가 자료
연결 리스트를 더 깊이 공부하고 싶다면 다음 주제를 시각화 플랫폼에서 함께 살펴보세요.
다중 연결 리스트(Multi-level Linked List): 각 노드가 여러 개의 링크를 가지는 구조입니다. 예를 들어 2차원 연결 리스트는 행과 열을 모두 연결하여 희소 행렬(Sparse Matrix)을 표현할 수 있습니다.
자기 조정 리스트(Self-organizing List): 접근 빈도에 따라 노드의 순서를 동적으로 변경합니다. 예를 들어 자주 조회되는 노드를 앞쪽으로 이동시키면 평균 검색 시간을 줄일 수 있습니다.
이중 연결 리스트를 이용한 LRU 캐시: 가장 오래전에 사용된 항목을 제거하는 LRU(Least Recently Used) 알고리즘은 해시맵과 이중 연결 리스트의 조합으로 구현됩니다. 이는 실제 운영체제와 데이터베이스에서 널리 사용됩니다.
11. 자주 묻는 질문 (FAQ)
Q: 연결 리스트가 배열보다 항상 느린가요? 아닙니다. 삽입과 삭제가 빈번하고 데이터 크기가 클수록 연결 리스트가 더 효율적일 수 있습니다. 특히 중간에 요소를 추가해야 하는 작업이 많다면 배열은 O(n)이지만 연결 리스트는 O(1)입니다.
Q: 시각화 플랫폼에서 사용할 수 있는 언어는 무엇인가요? 현재 파이썬, 자바, C++, 자바스크립트를 지원합니다. 각 언어의 문법에 맞게 코드를 작성하면 동일한 시각화 결과를 얻을 수 있습니다.
Q: 연결 리스트를 실제 프로젝트에서 언제 사용하나요? 데이터의 크기를 예측할 수 없거나, 삽입/삭제가 빈번한 경우에 사용합니다. 예를 들어 채팅 애플리케이션의 메시지 큐, 게임의 오브젝트 풀, 파일 시스템의 디렉터리 구조 등에서 활용됩니다.
Q: 시각화 학습만으로 충분한가요? 시각화는 개념 이해에 매우 효과적이지만, 실제로 코드를 직접 작성해보는 것이 중요합니다. 플랫폼에서 제공하는 코드 에디터를 활용해 직접 구현하고 시각화로 검증하는 과정을 반복하세요.
12. 결론: 시각화로 연결 리스트를 정복하자
선형 리스트와 연결 리스트는 자료구조의 기초이면서도 실무에서 매우 중요하게 사용됩니다. 배열의 빠른 접근 속도와 연결 리스트의 유연한 삽입/삭제는 상호 보완적인 관계입니다. 시각화 플랫폼을 활용하면 추상적인 포인터 개념을 눈으로 확인하고, 직접 조작하면서 자연스럽게 체화할 수 있습니다.
지금 바로 플랫폼에 접속하여 5개의 노드로 이루어진 단일 연결 리스트를 만들고, 중간에 노드를 추가하거나 삭제해보세요. 화면에서 화살표가 움직이는 모습을 보면서 '아, 이렇게 동작하는구나'라고 느끼는 순간이 올 것입니다. 그 순간이 바로 여러분이 자료구조를 완전히 이해했다는 신호입니다.
앞으로도 스택, 큐, 트리, 그래프 등 더 복잡한 자료구조를 시각화 플랫폼으로 학습할 수 있습니다. 모든 내용은 한국어로 제공되며, 초보자부터 전공자까지 모두 쉽게 접근할 수 있도록 설계되었습니다. 지금 바로 학습을 시작해보세요!
为什么要使用头插法创建,而不是尾插法创建?
如果我们要在链表末尾进行插入,那么需要先遍历整个链表找到尾结点,或者使用一个变量记录尾结点的。
而且每次都需要改变尾结点的next指向头结点,以达到循环。
而我们使用头插法,无论链表是否为空,代码都是统一不变,不需要做其他判断。
按位序删除结点
删除操作和普通单链表相同。主要区别在于我们需要确保删除后链表保持循环。
要从循环链表中删除特定的结点,首先需要检查删除的位序是否满足条件。
找到待删除结点的前驱结点即p结点
找到前驱结点p后,使用q记录为待删除结点
修改前驱结点p的next指向待删除结点q的next,即跳过q结点并将其删除
仅有一个结点时,循环指向头结点
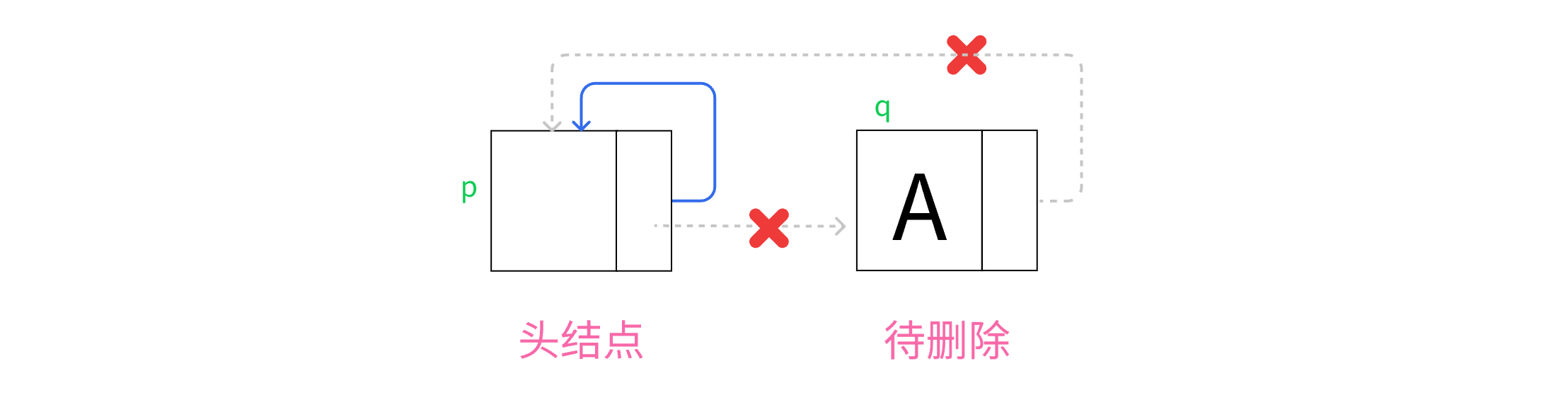
仅有一个结点时,循环指向头结点
删除尾部结点,更新链表循环
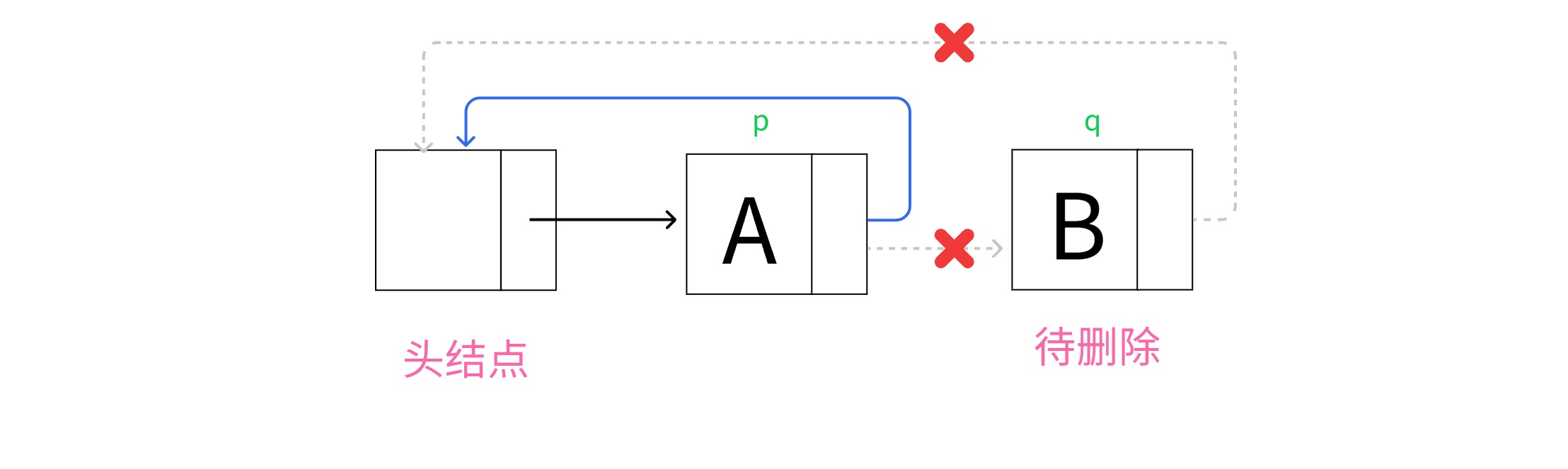
删除尾部结点,更新链表循环
删除中间结点
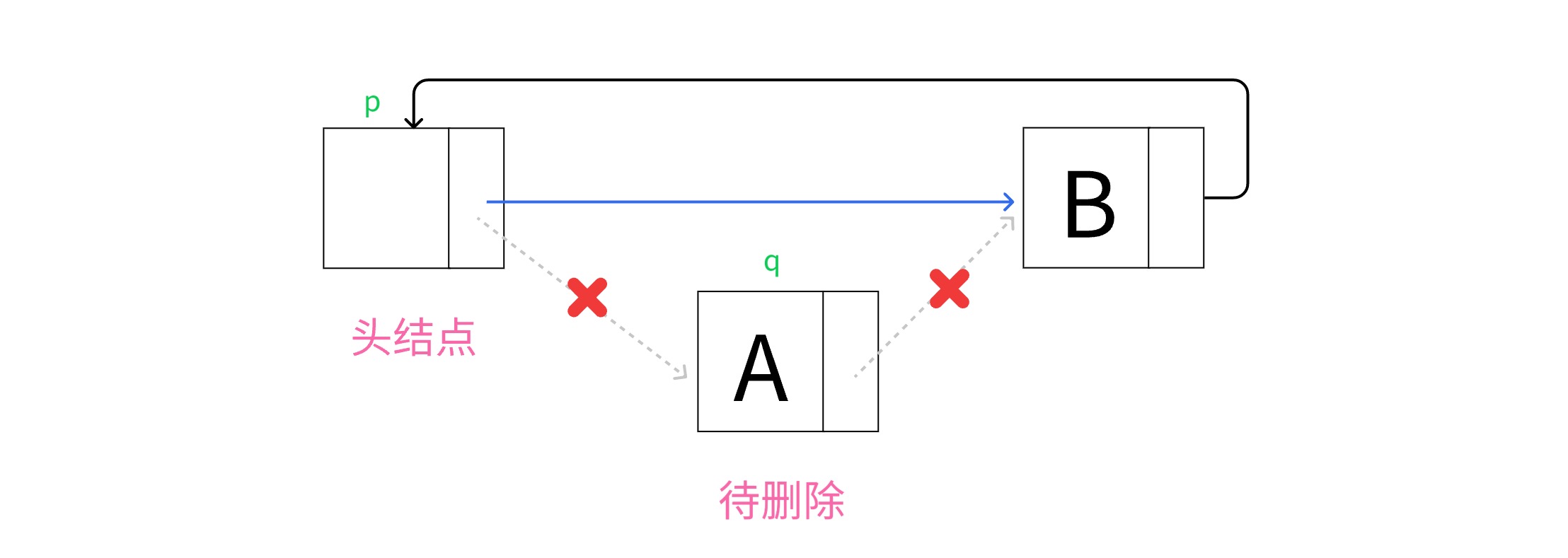
删除中间结点
💡 提示
对于带头结点的链表,上面三种情况都可以统一为同一种操作代码
按位序删除结点 | 可视化完整可视化
2.4 순환 단일 연결 리스트 상세 설명 - 선형 리스트 튜토리얼 애니메이션으로 코드를 시각화하세요
선형 리스트와 연결 리스트: 자료구조 시각화 학습 가이드
자료구조와 알고리즘을 처음 공부할 때 많은 학습자가 '선형 리스트(Linear List)'와 '연결 리스트(Linked List)'의 차이점에서 혼란을 느낍니다. 이 글에서는 두 개념의 핵심 원리와 실제 응용 사례를 쉬운 언어로 풀어내고, 시각화 학습 플랫폼을 통해 어떻게 효과적으로 익힐 수 있는지 자세히 설명합니다. 특히 한국어 사용자를 위해 번역체가 아닌 자연스러운 표현을 사용했으며, 검색 엔진이 내용을 잘 이해할 수 있도록 구조화했습니다.
1. 선형 리스트(Linear List)란 무엇인가?
선형 리스트는 데이터를 일렬로 나열한 가장 기본적인 자료구조입니다. 배열(Array)이 대표적인 예이며, 모든 요소가 메모리상에 연속적으로 저장됩니다. 예를 들어 int arr[5] = {10, 20, 30, 40, 50}과 같이 선언하면 10, 20, 30, 40, 50이 메모리 주소 1000, 1004, 1008, 1012, 1016에 차례대로 위치합니다.
장점: 인덱스를 사용하여 특정 위치의 데이터를 즉시 조회할 수 있습니다(시간복잡도 O(1)). 예를 들어 arr[3]을 호출하면 40을 바로 얻을 수 있습니다. 또한 캐시 지역성이 높아 순차 접근 속도가 빠릅니다.
단점: 크기가 고정되어 있어 실행 중에 크기를 변경하기 어렵습니다. 중간에 데이터를 삽입하거나 삭제할 때는 뒤에 있는 모든 요소를 이동시켜야 하므로 O(n)의 시간이 소요됩니다. 예를 들어 10, 20, 30, 40, 50에서 20과 30 사이에 25를 넣으려면 30, 40, 50을 한 칸씩 뒤로 밀어야 합니다.
2. 연결 리스트(Linked List)의 개념과 동작 원리
연결 리스트는 노드(Node)라고 불리는 단위가 포인터(Pointer)로 서로 연결된 구조입니다. 각 노드는 데이터를 저장하는 필드와 다음 노드를 가리키는 링크(Link) 필드로 구성됩니다. 첫 번째 노드는 헤드(Head)라고 부르며, 마지막 노드의 링크는 NULL을 가리킵니다.
단일 연결 리스트(Singly Linked List): 한 방향으로만 이동할 수 있습니다. head → [10|next] → [20|next] → [30|NULL] 형태입니다. 특정 위치에 데이터를 삽입하려면 앞 노드의 링크를 새 노드로 바꾸고 새 노드의 링크를 다음 노드로 설정하면 됩니다. 배열과 달리 요소 이동이 필요 없으므로 O(1)에 삽입이 가능합니다(단, 삽입 위치를 찾는 탐색은 O(n)).
이중 연결 리스트(Doubly Linked List): 각 노드가 이전 노드와 다음 노드를 모두 가리키는 링크를 가집니다. head ↔ [prev|10|next] ↔ [prev|20|next] ↔ [prev|30|NULL] 형태입니다. 양방향 탐색이 가능하여 특정 노드의 앞뒤를 쉽게 알 수 있습니다.
원형 연결 리스트(Circular Linked List): 마지막 노드의 링크가 첫 번째 노드를 가리킵니다. head → [10|next] → [20|next] → [30|next] → head. 이 구조는 순환 큐나 음악 플레이리스트처럼 반복 순회가 필요한 상황에 유용합니다.
3. 선형 리스트와 연결 리스트의 비교 분석
두 자료구조는 각기 다른 트레이드오프를 가집니다. 아래는 핵심 차이점입니다.
메모리 사용: 배열은 데이터만 저장하지만 연결 리스트는 링크 필드를 위해 추가 메모리를 사용합니다. 예를 들어 정수형 데이터 1,000개를 저장할 때 배열은 4KB(4바이트*1000)면 충분하지만, 연결 리스트는 링크 포인터(8바이트)까지 포함해 약 12KB가 필요합니다.
접근 속도: 배열은 인덱스로 O(1)에 접근할 수 있습니다. 반면 연결 리스트는 k번째 노드에 접근하려면 head부터 k번 이동해야 하므로 O(n)이 걸립니다. 따라서 빈번한 검색이 필요한 작업에는 배열이 유리합니다.
삽입/삭제: 배열은 중간 삽입 시 O(n)의 이동 비용이 들지만, 연결 리스트는 링크 조작만으로 O(1)에 처리할 수 있습니다(노드 위치를 알고 있을 경우). 예를 들어 실시간 게임에서 플레이어 목록을 자주 추가/제거해야 한다면 연결 리스트가 적합합니다.
캐시 지역성: 배열은 연속 메모리이므로 CPU 캐시 효율이 높습니다. 연결 리스트는 노드가 메모리 곳곳에 흩어져 있어 캐시 미스가 자주 발생할 수 있습니다. 대규모 데이터를 순차적으로 읽을 때 배열이 2~5배 더 빠를 수 있습니다.
4. 연결 리스트의 주요 응용 분야
연결 리스트는 다양한 실전 시스템에서 핵심 역할을 합니다. 몇 가지 대표적인 사례를 살펴보겠습니다.
운영체제의 프로세스 스케줄링: 라운드 로빈(Round Robin) 방식에서 준비 큐(Ready Queue)는 원형 연결 리스트로 구현됩니다. 각 프로세스가 일정 시간 동안 CPU를 사용하고 다음 프로세스로 넘어갈 때, 리스트의 head를 이동시키기만 하면 됩니다.
이미지 편집기의 실행 취소(Undo) 기능: 사용자의 작업 내역을 이중 연결 리스트로 저장합니다. Ctrl+Z를 누르면 현재 노드의 이전 노드로 이동하고, Ctrl+Y를 누르면 다음 노드로 이동합니다. 이때 리스트의 양방향 특성이 매우 유용합니다.
음악 재생 플레이리스트: 사용자가 다음 곡이나 이전 곡을 선택할 때 원형 연결 리스트를 사용하면 마지막 곡에서 첫 곡으로 자연스럽게 넘어갈 수 있습니다. 또한 특정 곡을 추가하거나 제거할 때도 연결 리스트의 삽입/삭제가 효율적입니다.
브라우저 방문 기록: 사용자가 뒤로 가기/앞으로 가기 버튼을 누를 때마다 이중 연결 리스트의 노드 이동이 발생합니다. 각 노드는 방문한 URL과 타임스탬프를 저장합니다.
해시 테이블의 체이닝(Chaining): 해시 충돌을 해결하기 위해 각 버킷(Bucket)에 연결 리스트를 사용합니다. 동일한 해시 값을 가진 데이터를 리스트로 결하여 저장합니다.
5. 연결 리스트의 변형과 고급 개념
기본 연결 리스트 외에도 다양한 변형이 존재합니다. 학습자는 이를 이해하면 더 복잡한 알고리즘을 다룰 수 있습니다.
헤드 포인터가 없는 연결 리스트: 첫 번째 노드가 항상 특별한 값을 가지는 더미 노드(Dummy Node)를 사용하는 경우도 있습니다. 이렇게 하면 빈 리스트나 첫 번째 노드 삭제를 일반화된 코드로 처리할 수 있습니다.
블록 연결 리스트(Unrolled Linked List): 각 노드가 여러 개의 데이터를 저장하는 배열을 가집니다. 예를 들어 한 노드에 16개의 정수를 저장하고, 노드 간에는 포인터로 연결합니다. 이 구조는 캐시 지역성과 삽입/삭제 성능 사이의 균형을 제공합니다.
스킵 리스트(Skip List): 연결 리스트에 다중 레벨 인덱스를 추가한 자료구조입니다. 검색 시간이 O(log n)으로 향상되며, 레디스(Redis)와 같은 고성능 데이터베이스에서 사용됩니다.
6. 시각화 학습 플랫폼의 필요성
연결 리스트는 추상적인 포인터 개념이 많아 초보자가 머릿속으로 그리기 어렵습니다. 예를 들어 '노드의 next를 temp에 저장하고, prev의 next를 새 노드로 바꾼다'는 설명만으로는 정확한 동작을 이해하기 힘듭니다. 이때 시각화 플랫폼이 큰 도움이 됩니다.
시각화 도구는 각 노드를 박스로 표현하고, 포인터를 화살표로 나타내어 데이터의 이동을 실시간으로 보여줍니다. 사용자가 삽입, 삭제, 탐색 버튼을 클릭할 때마다 메모리 상태가 어떻게 변하는지 애니메이션으로 확인할 수 있습니다. 이는 '보면서 배우는 학습(Visual Learning)' 효과를 극대화합니다.
7. 자료구조 시각화 플랫폼의 주요 기능
효과적인 시각화 플랫폼은 다음과 같은 기능을 제공해야 합니다.
단계별 실행(Step-by-Step Execution): 사용자가 한 줄의 코드나 한 번의 연산을 실행할 때마다 자료구조의 상태가 업데이트됩니다. 예를 들어 '노드 3을 위치 2에 삽입'을 선택하면, 먼저 새 노드가 생성되고, 링크가 변경되는 과정을 한 프레임씩 볼 수 있습니다.
메모리 뷰(Memory View): 각 노드가 실제 메모리 주소(가상)에 어떻게 배치되는지 보여줍니다. 배열과 달리 연결 리스트의 노드가 불연속적으로 위치한다는 점을 직관적으로 이해할 수 있습니다.
코드 연동(Code Sync): 사용자가 파이썬, 자바, C++ 등 특정 언어로 작성한 코드가 실행될 때, 해당 코드 라인이 하이라이트되고 자료구조가 동시에 변합니다. 예를 들어 'node.next = prev.next'라는 코드가 실행되면 화살표가 실제로 이동하는 것을 볼 수 있습니다.
사용자 정의 데이터: 학습자가 직접 데이터 값을 입력하거나 노드 개수를 조절할 수 있어야 합니다. 5개의 노드로 테스트하다가 100개의 노드로 확장했을 때 성능 차이를 체감할 수 있습니다.
오류 시뮬레이션: 의도적으로 NULL 포인터 역참조나 무한 루프 상황을 만들어보고, 디버깅하는 과정을 시각화할 수 있습니다. 이는 실제 프로그래밍에서 발생할 수 있는 버그를 예방하는 데 도움이 됩니다.
8. 플랫폼을 활용한 학습 방법
다음은 시각화 플랫폼을 최대한 활용하는 구체적인 학습 로드맵입니다.
1단계: 기본 구조 익히기 - 단일 연결 리스트의 노드 생성, head 설정, NULL 처리 등 기본 개념을 시각화 도구로 10번 정도 반복해서 살펴봅니다. 각 노드의 next 포인터가 어떻게 연결되는지 손으로 따라 그려보는 것도 좋습니다.
2단계: 핵심 연습 문제 풀기 - "리스트의 끝에 노드 추가", "특정 값을 가진 노드 삭제", "리스트 뒤집기" 같은 기본 연산을 시각화하면서 직접 구현해봅니다. 플랫폼의 '단계별 실행' 기능을 켜고 한 줄 한 줄 확인합니다.
3단계: 고급 알고리즘 시각화 - 두 리스트의 병합, 중간 노드 찾기(토끼와 거북이 알고리즘), 사이클 탐지(Floyd's Cycle Detection) 등을 시각화합니다. 특히 사이클이 있는 리스트에서 포인터가 어떻게 움직이는지 애니메이션으로 보면 이해도가 훨씬 높아집니다.
4단계: 실제 코드와 비교 - 플랫폼에서 제공하는 코드 템플릿을 자신이 사용하는 언어로 변환해보고, 동일한 시각화 결과가 나오는지 확인합니다. 예를 들어 파이썬으로 구현한 연결 리스트와 자바로 구현한 연결 리스트의 시각화를 비교해볼 수 있습니다.
5단계: 성능 측정 - 플랫폼의 '데이터 크기 조절' 기능을 이용해 노드가 10개, 100개, 1000개일 때 삽입/삭제 시간을 측정합니다. 배열과 연결 리스트의 차이를 직접 눈으로 확인하면 빅오 표기법이 더 와닿습니다.
9. 시각화 플랫폼의 기술적 장점
이 플랫폼은 단순한 그림이 아니라 실제 실행 엔진을 기반으로 합니다. 내부적으로는 자바스크립트로 구현된 가상 메모리 모델이 동작하며, 사용자의 모든 조작이 즉시 반영됩니다. 예를 들어 사용자가 '노드 삭제' 버튼을 누르면, 가비지 컬렉션(Garbage Collection) 시뮬레이션까지 보여주어 메모리 관리 개념까지 함께 학습할 수 있습니다.
또한 모든 시각화는 HTML5 Canvas 위에 렌더링되므로 별도의 플러그인 설치 없이 웹 브라우저에서 바로 실행됩니다. 모바일 환경에서도 터치 제스처를 지원하여 태블릿으로도 학습이 가능합니다.
10. 학습자에게 추천하는 추가 자료
연결 리스트를 더 깊이 공부하고 싶다면 다음 주제를 시각화 플랫폼에서 함께 살펴보세요.
다중 연결 리스트(Multi-level Linked List): 각 노드가 여러 개의 링크를 가지는 구조입니다. 예를 들어 2차원 연결 리스트는 행과 열을 모두 연결하여 희소 행렬(Sparse Matrix)을 표현할 수 있습니다.
자기 조정 리스트(Self-organizing List): 접근 빈도에 따라 노드의 순서를 동적으로 변경합니다. 예를 들어 자주 조회되는 노드를 앞쪽으로 이동시키면 평균 검색 시간을 줄일 수 있습니다.
이중 연결 리스트를 이용한 LRU 캐시: 가장 오래전에 사용된 항목을 제거하는 LRU(Least Recently Used) 알고리즘은 해시맵과 이중 연결 리스트의 조합으로 구현됩니다. 이는 실제 운영체제와 데이터베이스에서 널리 사용됩니다.
11. 자주 묻는 질문 (FAQ)
Q: 연결 리스트가 배열보다 항상 느린가요? 아닙니다. 삽입과 삭제가 빈번하고 데이터 크기가 클수록 연결 리스트가 더 효율적일 수 있습니다. 특히 중간에 요소를 추가해야 하는 작업이 많다면 배열은 O(n)이지만 연결 리스트는 O(1)입니다.
Q: 시각화 플랫폼에서 사용할 수 있는 언어는 무엇인가요? 현재 파이썬, 자바, C++, 자바스크립트를 지원합니다. 각 언어의 문법에 맞게 코드를 작성하면 동일한 시각화 결과를 얻을 수 있습니다.
Q: 연결 리스트를 실제 프로젝트에서 언제 사용하나요? 데이터의 크기를 예측할 수 없거나, 삽입/삭제가 빈번한 경우에 사용합니다. 예를 들어 채팅 애플리케이션의 메시지 큐, 게임의 오브젝트 풀, 파일 시스템의 디렉터리 구조 등에서 활용됩니다.
Q: 시각화 학습만으로 충분한가요? 시각화는 개념 이해에 매우 효과적이지만, 실제로 코드를 직접 작성해보는 것이 중요합니다. 플랫폼에서 제공하는 코드 에디터를 활용해 직접 구현하고 시각화로 검증하는 과정을 반복하세요.
12. 결론: 시각화로 연결 리스트를 정복하자
선형 리스트와 연결 리스트는 자료구조의 기초이면서도 실무에서 매우 중요하게 사용됩니다. 배열의 빠른 접근 속도와 연결 리스트의 유연한 삽입/삭제는 상호 보완적인 관계입니다. 시각화 플랫폼을 활용하면 추상적인 포인터 개념을 눈으로 확인하고, 직접 조작하면서 자연스럽게 체화할 수 있습니다.
지금 바로 플랫폼에 접속하여 5개의 노드로 이루어진 단일 연결 리스트를 만들고, 중간에 노드를 추가하거나 삭제해보세요. 화면에서 화살표가 움직이는 모습을 보면서 '아, 이렇게 동작하는구나'라고 느끼는 순간이 올 것입니다. 그 순간이 바로 여러분이 자료구조를 완전히 이해했다는 신호입니다.
앞으로도 스택, 큐, 트리, 그래프 등 더 복잡한 자료구조를 시각화 플랫폼으로 학습할 수 있습니다. 모든 내용은 한국어로 제공되며, 초보자부터 전공자까지 모두 쉽게 접근할 수 있도록 설계되었습니다. 지금 바로 학습을 시작해보세요!