 图码
图码2.3 双链表
单链表结点中只有一个指向其后继的指针,使得单链表只能从前往后依次遍历。要访问某个结点的前驱(插入、删除操作时),只能从头开始遍历,访问前驱的时间复杂度为 O(n)。
为了克服单链表的这个缺点,引入了双链表,双链表结点中有两个指针prior和next,分别指向其直接前驱和直接后继。
双链表的主要特性
- 双向遍历由于每个节点都有前后两个指针,因此可以在列表中双向遍历,无需像单链表那样只能从头节点开始向前遍历。
- 插入与删除的便捷性:在双链表中插入或删除一个节点时,只需改变相应节点的前后节点的指针指向即可,操作相对简单高效。
数据结构
- data:数据域,也是节点的值
- prior:指针域,指向前一个结点的指针
- next:指针域,指向下一个结点的指针
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
typedef struct DNode {
int data; // 数据
struct DNode *prior, *next; // 前驱和后继指针
} DNode, *DLinkList;
pTemp = (DNode *)malloc(sizeof(DNode));
pTemp->data = x;
pTemp->next = pHead->next;
pTemp->prior = pHea
// 完整代码:https://totuma.cn
链表结构
💡双链表在单链表结点中增加了一个指向其前驱的指针prior ,因此双链表的按值查找和按位查找的操作与单链表的相同。但双链表在插入和删除操作的实现上,与单链表有着较大的不同。 这是因为“链”变化时也需要对指针 prior 做出修改,其关键是保证在修改的过程中不断链。 此外,双链表可以很方便地找到当前结点的前驱,因此,插入、除操作的时间复杂度仅为 O(1)。
双链表的基本操作实现
单链表的节点在需要时动态分配内存,这意味着不需要像数组那样在创建时预先分配一大片连续内存。因此,单链表在内存使用上更加灵活,可以有效应对内存碎片和动态增长的问题。
由于链表节点是在需要时分配的,可以避免数组因初始化大小不确定而造成的内存浪费。例如,如果数组大小初始化过大,未使用的部分将浪费内存;若初始化过小,则可能需要频繁重新分配和复制。
每个节点需要一个指针域来存储对下一个节点的引用,这意味着相比于数组,单链表在每个节点上都会有额外的内存开销。对于存储小数据的场景,这个开销相对较大,可能导致内存利用率下降。
按位序插入结点
该函数用于在双向链表中按指定位置插入一个新元素。(注意区分位置和下标:位置从1开始,下标从0开始)
在位置 i 插入元素 e,其中 i=1 表示插入到表头,i=length+1 表示插入到表尾。
重点注意下链表为空和不为空时的处理逻辑
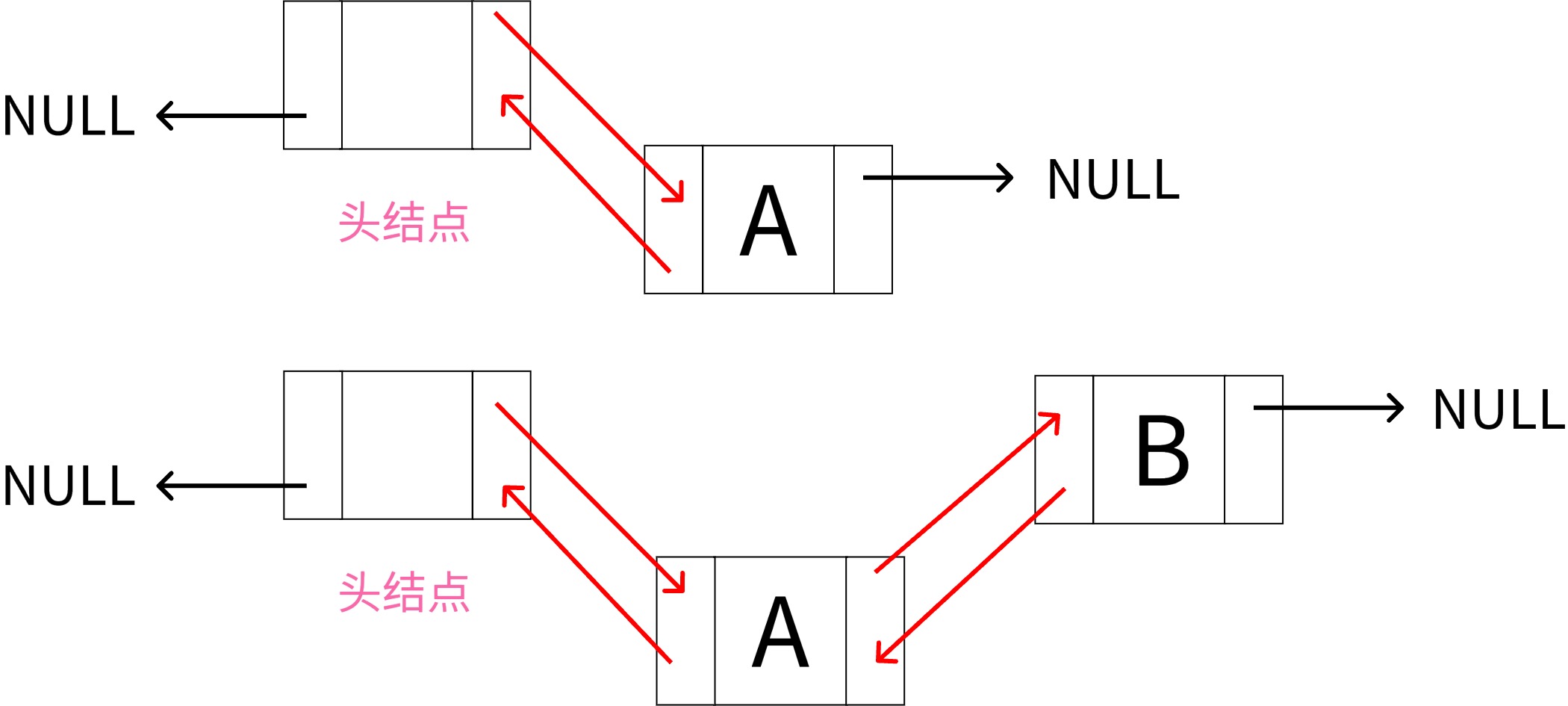
插入时链表空和不空时的区别
按位序插入结点 | 可视化完整可视化
2.3 이중 연결 리스트 상세 설명 - 선형 리스트 튜토리얼 애니메이션으로 코드를 시각화하세요

선형 리스트(Linear List)와 연결 리스트(Linked List) 개념 완전 정복
자료구조를 처음 공부할 때 가장 먼저 만나는 개념이 바로 '선형 리스트'와 '연결 리스트'입니다. 이 두 자료구조는 데이터를 순서대로 저장하는 가장 기본적인 방법이지만, 내부 동작 방식과 성능 특성이 완전히 다릅니다. 이 글에서는 초보자도 쉽게 이해할 수 있도록 두 자료구조의 원리, 차이점, 실제 활용 예시를 자세히 설명합니다. 특히 시각화 도구를 통해 머리로만 이해하기 어려운 포인터 연결과 메모리 할당 과정을 눈으로 직접 확인할 수 있도록 도와드립니다.
선형 리스트(Linear List)란? – 배열로 구현하는 순차적 저장
선형 리스트는 데이터를 논리적인 순서대로 메모리에 연속적으로 저장하는 자료구조입니다. 가장 대표적인 구현 방식이 '배열(Array)'입니다. 예를 들어 학생 5명의 점수를 저장한다고 할 때, 배열은 메모리상에 5개의 방을 연달아 만들어 놓고 첫 번째 학생부터 마지막 학생까지 차곡차곡 저장합니다.
핵심 특징: 인덱스(index)를 사용하면 어떤 위치에 있는 데이터든 한 번에 접근할 수 있습니다. 예를 들어 arr[3]이라고 쓰면 네 번째 데이터를 즉시 찾을 수 있습니다. 이렇게 빠른 접근 속도가 선형 리스트의 가장 큰 장점입니다. 하지만 데이터를 중간에 삽입하거나 삭제할 때는 문제가 발생합니다. 만약 세 번째 위치에 새 데이터를 넣고 싶다면, 기존 세 번째부터 마지막까지 모든 데이터를 한 칸씩 뒤로 밀어야 합니다. 이 작업은 데이터 개수가 많을수록 시간이 오래 걸립니다.
시간 복잡도: 접근(읽기)은 O(1), 탐색은 O(n), 삽입/삭제는 O(n)입니다. 즉, 읽기는 빠르지만 삽입과 삭제가 잦은 상황에서는 비효율적입니다.
실제 사용 예: 게임에서 캐릭터의 인벤토리처럼 고정된 크기의 목록을 다룰 때, 혹은 데이터 크기가 거의 변하지 않고 빠른 읽기가 필요한 경우(예: 월별 평균 기온 데이터)에 적합합니다.
연결 리스트(Linked List)란? – 노드와 포인터로 구현하는 동적 저장
연결 리스트는 데이터를 메모리에 흩어져 저장하면서, 각 데이터가 다음 데이터의 주소를 가리키는 방식으로 연결된 자료구조입니다. 각 데이터 덩어리를 '노드(Node)'라고 부르며, 노드는 실제 데이터를 저장하는 부분과 다음 노드를 가리키는 '포인터(pointer)'로 구성됩니다.
마치 보물찾기 지도처럼, 첫 번째 노드(Head)를 알면 그 노드가 가리키는 주소를 따라 두 번째 노드로 이동하고, 다시 그 노드가 가리키는 주소로 세 번째 노드로 이동하는 식입니다. 따라서 데이터가 메모리 어디에 있든 상관없이 순서대로 접근할 수 있습니다.
핵심 특징: 데이터의 삽입과 삭제가 매우 자유롭습니다. 중간에 새 노드를 추가하고 싶다면, 앞 노드의 포인터만 새 노드로 바꾸고 새 노드의 포인터를 다음 노드로 연결하면 끝입니다. 데이터를 밀거나 당길 필요가 없습니다. 하지만 인덱스로 바로 접근할 수 없습니다. 예를 들어 100번째 데이터를 찾으려면 Head부터 시작해서 100번 포인터를 따라 이동해야 합니다.
시간 복잡도: 접근(읽기)은 O(n), 탐색은 O(n), 삽입/삭제(위치를 알고 있을 때)는 O(1)입니다. 즉, 삽입/제는 빠르지만 읽기는 느립니다.
다양한 종류: 단일 연결 리스트(한 방향), 이중 연결 리스트(앞뒤 양방향), 원형 연결 리스트(마지막이 처음으로 연결) 등이 있습니다. 이중 연결 리스트는 이전 노드로도 이동할 수 있어 양방향 탐색이 필요할 때 유용합니다.
선형 리스트 vs 연결 리스트 – 언제 무엇을 써야 할까?
두 자료구조는 서로 반대되는 장단점을 가지고 있습니다. 데이터 읽기가 압도적으로 많고 크기가 고정적이라면 선형 리스트(배열)가 좋습니다. 반대로 데이터의 삽입과 삭제가 빈번하고 데이터의 총 개수를 예측하기 어렵다면 연결 리스트가 적합합니다.
예를 들어, 음악 플레이어의 재생 목록을 생각해봅시다. 사용자가 노래를 자주 추가하고 삭제하며 순서를 바꾼다면 연결 리스트가 효율적입니다. 하지만 특정 순번의 노래를 바로 틀고 싶다면 선형 리스트가 더 빠릅니다. 실제로 많은 프로그래밍 언어에서는 두 가지를 혼합한 '동적 배열(ArrayList)'을 제공하여 대부분의 상황에서 균형 잡힌 성능을 내도록 합니다.
메모리 측면: 선형 리스트는 미리 큰 공간을 할당해야 하므로 메모리 낭비가 발생할 수 있습니다. 연결 리스트는 필요할 때마다 노드를 생성하므로 메모리를 효율적으로 사용하지만, 포인터 저장을 위한 추가 공간(오버헤드)이 필요합니다.
데이터 구조 시각화 학습 플랫폼의 필요성
선형 리스트와 연결 리스트는 개념 자체는 간단하지만, 포인터가 실제로 어떻게 움직이는지, 삽입/삭제 시 메모리에서 어떤 일이 일어나는지 머릿속으로 그리기 어렵습니다. 특히 연결 리스트의 중간 삽입 과정에서 포인터가 끊어졌다가 다시 연결되는 모습은 초보자에게 큰 혼란을 줍니다.
이때 필요한 것이 바로 '데이터 구조 시각화 학습 플랫폼'입니다. 이 플랫폼은 코드가 실행되는 과정을 애니메이션으로 보여주고, 각 변수와 메모리 상태를 실시간으로 하이라이트하여 추상적인 개념을 구체적인 이미지로 바꿔줍니다.
시각화 플랫폼의 주요 기능과 장점
1. 단계별 실행 (Step-through Execution): 코드 한 줄 한 줄 실행할 때마다 연결 리스트의 노드가 어떻게 생성되고, 포인터가 어떻게 변경되는지 애니메이션으로 보여줍니다. 예를 들어 'head = new Node(5)'라는 코드가 실행되면 화면에 새로운 네모 상자가 나타나고 그 안에 5라는 숫자가 표시됩니다.
2. 실시간 메모리 상태 표시: 현재 메모리에 할당된 모든 노드와 그들의 주소(또는 참조)를 그래픽으로 보여줍니다. 배열의 경우 각 인덱스의 값이 어떻게 저장되어 있는지 한눈에 볼 수 있습니다.
3. 삽입/삭제 시뮬레이션: 중간에 노드를 삽입할 때 기존 노드들의 포인터가 어떻게 바뀌는지, 삭제할 때는 어떻게 연결이 끊어지고 가비지 컬렉션이 일어나는지 시각적으로 추적할 수 있습니다.
4. 다양한 알고리즘 비교: 같은 데이터로 선형 리스트와 연결 리스트에서의 탐색, 삽입, 삭제 속도를 직접 눈으로 비교할 수 있습니다. 이를 통해 각 자료구조의 시간 복잡도를 체감할 수 있습니다.
5. 코드와 시각화 동기화: 왼쪽에는 코드, 오른쪽에는 시각화가 배치되어 코드의 변화가 즉시 그림으로 반영됩니다. 이 기능은 '코드가 실제로 무엇을 하는지'를 직관적으로 이해하게 해줍니다.
시각화 플랫폼 사용 방법 – 초보자 가이드
이 플랫폼은 복잡한 설치 없이 웹 브라우저에서 바로 사용할 수 있습니다. 다음은 간단한 사용 순서입니다.
1단계: 플랫폼에 접속하여 '연결 리스트' 또는 '선형 리스트' 모듈을 선택합니다. 기본적인 예제 코드가 이미 준비되어 있습니다.
2단계: '실행' 버튼을 누르면 코드가 자동으로 실행되면서 시각화가 시작됩니다. '다음 단계' 버튼을 누르면 한 줄씩 진행되며, 각 단계에서 메모리 상태가 어떻게 변하는지 관찰할 수 있습니다.
3단계: 직접 코드를 수정해보세요. 예를 들어 'insert(2, 100)'이라는 코드를 추가하고 실행하면, 연결 리스트의 세 번째 위치에 100이 삽입되는 과정을 애니메이션으로 확인할 수 있습니다.
4단계: 속도 조절 바를 이용해 애니메이션 속도를 느리게 하거나 빠르게 할 수 있습니다. 처음에는 느리게 설정하여 포인터의 변화를 하나하나 따라가는 것이 좋습니다.
5단계: 학습이 끝난 후에는 '퀴즈' 기능을 통해 자신의 이해도를 테스트할 수 있습니다. 시각화 없이도 연결 리스트의 동작을 예측하는 문제가 출제됩니다.
실제 학습 사례 – 연결 리스트 뒤집기(Reverse) 시각화
연결 리스트에서 가장 어려워하는 연산 중 하나가 '뒤집기(Reverse)'입니다. 시각화 플랫폼에서는 이 과정을 3단계로 보여줍니다. 첫째, 현재 노드와 이전 노드를 가리키는 포인터가 생깁니다. 둘째, 현재 노드의 다음 포인터가 이전 노드를 가리키도록 변경됩니다. 셋째, 모든 포인터가 한 칸씩 이동합니다. 이 과정이 반복되면서 리스트의 방향이 완전히 바뀝니다. 이 시각화를 보면 많은 학생들이 "아, 그래서 포인터를 임시 변수에 저장해야 하는구나!"라고 깨닫게 됩니다.
이처럼 시각화는 단순한 암기를 넘어 '원리'를 이해하게 도와줍니다. 특히 연결 리스트의 순환 참조나 널 포인터 오류 같은 미묘한 버그도 시각화를 통해 쉽게 발견할 수 있습니다.
선형 리스트와 연결 리스트의 심화 응용
이 두 자료구조는 더 복잡한 자료구조의 기초가 됩니다. 예를 들어 스택(Stack)과 큐(Queue)는 선형 리스트나 연결 리스트로 구현할 수 있습니다. 해시 테이블의 체이닝(Chaining) 기법은 연결 리스트를 사용하여 충돌을 해결합니다. 그래프(Graph)의 인접 리스트 표현도 연결 리스트의 확장입니다.
또한 운영체제의 프로세스 스케줄링, 웹 브라우저의 방문 기록 관리, 이미지 편집 프로그램의 실행 취소(Undo) 기능 등 실무에서도 광범위하게 사용됩니다. 따라서 이 두 자료구조를 확실히 이해하면 이후에 배울 트리, 그래프, 고급 알고리즘의 이해도가 훨씬 높아집니다.
자주 묻는 질문 (FAQ)
Q: 연결 리스트는 배열보다 항상 느린가요? 아닙니다. 삽입과 삭제가 빈번한 상황에서는 연결 리스트가 훨씬 빠릅니다. 배열은 삽입/삭제 시 데이터를 이동해야 하지만, 연결 리스트는 포인터만 변경하면 되기 때문입니다.
Q: 연결 리스트를 사용할 때 메모리 누수가 발생할 수 있나요? 네, 특히 C/C++ 같은 언어에서는 삭제된 노드의 메모리를 직접 해제하지 않으면 누수가 발생합니다. 시각화 플랫폼에서는 가비지 컬렉션이 어떻게 동작하는지도 보여주어 이런 위험을 인지하게 해줍니다.
Q: 시각화 플랫폼에서 내가 원하는 데이터로 실험할 수 나요? 물론입니다. 대부분의 플랫폼은 사용자 정의 입력을 지원합니다. 직접 숫자 리스트를 입력하거나, 파일에서 데이터를 불러와서 시각화할 수 있습니다.
Q: 이 플랫폼은 무료인가요? 기본적인 자료구조 시각화는 대부분 무료로 제공됩니다. 일부 고급 기능(예: 사용자 정의 알고리즘 저장, 협업 기능)은 유료일 수 있습니다.
결론 – 시각화로 시작하는 탄탄한 자료구조 공부
선형 리스트와 연결 리스트는 모든 자료구조의 기본입니다. 이 두 가지를 제대로 이해하지 못하면 이후의 모든 학습이 흔들릴 수 있습니다. 하지만 막연한 개념 설명만으로는 머릿속에 잘 그려지지 않는 것이 사실입니다. 데이터 구조 시각화 학습 플랫폼은 추상적인 개념을 눈에 보이는 형태로 변환하여 학습 곡선을 크게 낮춰줍니다.
지금 바로 플랫폼에 접속해서 직접 코드를 실행하고, 포인터가 움직이는 모습을 관찰해보세요. 단 30분만 투자해도 배열과 연결 리스트의 차이를 완전히 내 것으로 만들 수 있습니다. 자료구조는 '보면서 이해하는 것'이 가장 빠른 길입니다.
按位序删除结点
该函数用于按位序删除节点的功能。具体来说,当参数 i 为 1 时,删除链表的 头节点;当 i 等于链表长度时,删除链表的 尾节点。
重点注意下链表为空和不为空时的处理逻辑

删除时链表空和不空时的区别
按位序删除结点 | 可视化完整可视化
2.3 이중 연결 리스트 상세 설명 - 선형 리스트 튜토리얼 애니메이션으로 코드를 시각화하세요
선형 리스트(Linear List)와 연결 리스트(Linked List) 개념 완전 정복
자료구조를 처음 공부할 때 가장 먼저 만나는 개념이 바로 '선형 리스트'와 '연결 리스트'입니다. 이 두 자료구조는 데이터를 순서대로 저장하는 가장 기본적인 방법이지만, 내부 동작 방식과 성능 특성이 완전히 다릅니다. 이 글에서는 초보자도 쉽게 이해할 수 있도록 두 자료구조의 원리, 차이점, 실제 활용 예시를 자세히 설명합니다. 특히 시각화 도구를 통해 머리로만 이해하기 어려운 포인터 연결과 메모리 할당 과정을 눈으로 직접 확인할 수 있도록 도와드립니다.
선형 리스트(Linear List)란? – 배열로 구현하는 순차적 저장
선형 리스트는 데이터를 논리적인 순서대로 메모리에 연속적으로 저장하는 자료구조입니다. 가장 대표적인 구현 방식이 '배열(Array)'입니다. 예를 들어 학생 5명의 점수를 저장한다고 할 때, 배열은 메모리상에 5개의 방을 연달아 만들어 놓고 첫 번째 학생부터 마지막 학생까지 차곡차곡 저장합니다.
핵심 특징: 인덱스(index)를 사용하면 어떤 위치에 있는 데이터든 한 번에 접근할 수 있습니다. 예를 들어 arr[3]이라고 쓰면 네 번째 데이터를 즉시 찾을 수 있습니다. 이렇게 빠른 접근 속도가 선형 리스트의 가장 큰 장점입니다. 하지만 데이터를 중간에 삽입하거나 삭제할 때는 문제가 발생합니다. 만약 세 번째 위치에 새 데이터를 넣고 싶다면, 기존 세 번째부터 마지막까지 모든 데이터를 한 칸씩 뒤로 밀어야 합니다. 이 작업은 데이터 개수가 많을수록 시간이 오래 걸립니다.
시간 복잡도: 접근(읽기)은 O(1), 탐색은 O(n), 삽입/삭제는 O(n)입니다. 즉, 읽기는 빠르지만 삽입과 삭제가 잦은 상황에서는 비효율적입니다.
실제 사용 예: 게임에서 캐릭터의 인벤토리처럼 고정된 크기의 목록을 다룰 때, 혹은 데이터 크기가 거의 변하지 않고 빠른 읽기가 필요한 경우(예: 월별 평균 기온 데이터)에 적합합니다.
연결 리스트(Linked List)란? – 노드와 포인터로 구현하는 동적 저장
연결 리스트는 데이터를 메모리에 흩어져 저장하면서, 각 데이터가 다음 데이터의 주소를 가리키는 방식으로 연결된 자료구조입니다. 각 데이터 덩어리를 '노드(Node)'라고 부르며, 노드는 실제 데이터를 저장하는 부분과 다음 노드를 가리키는 '포인터(pointer)'로 구성됩니다.
마치 보물찾기 지도처럼, 첫 번째 노드(Head)를 알면 그 노드가 가리키는 주소를 따라 두 번째 노드로 이동하고, 다시 그 노드가 가리키는 주소로 세 번째 노드로 이동하는 식입니다. 따라서 데이터가 메모리 어디에 있든 상관없이 순서대로 접근할 수 있습니다.
핵심 특징: 데이터의 삽입과 삭제가 매우 자유롭습니다. 중간에 새 노드를 추가하고 싶다면, 앞 노드의 포인터만 새 노드로 바꾸고 새 노드의 포인터를 다음 노드로 연결하면 끝입니다. 데이터를 밀거나 당길 필요가 없습니다. 하지만 인덱스로 바로 접근할 수 없습니다. 예를 들어 100번째 데이터를 찾으려면 Head부터 시작해서 100번 포인터를 따라 이동해야 합니다.
시간 복잡도: 접근(읽기)은 O(n), 탐색은 O(n), 삽입/삭제(위치를 알고 있을 때)는 O(1)입니다. 즉, 삽입/제는 빠르지만 읽기는 느립니다.
다양한 종류: 단일 연결 리스트(한 방향), 이중 연결 리스트(앞뒤 양방향), 원형 연결 리스트(마지막이 처음으로 연결) 등이 있습니다. 이중 연결 리스트는 이전 노드로도 이동할 수 있어 양방향 탐색이 필요할 때 유용합니다.
선형 리스트 vs 연결 리스트 – 언제 무엇을 써야 할까?
두 자료구조는 서로 반대되는 장단점을 가지고 있습니다. 데이터 읽기가 압도적으로 많고 크기가 고정적이라면 선형 리스트(배열)가 좋습니다. 반대로 데이터의 삽입과 삭제가 빈번하고 데이터의 총 개수를 예측하기 어렵다면 연결 리스트가 적합합니다.
예를 들어, 음악 플레이어의 재생 목록을 생각해봅시다. 사용자가 노래를 자주 추가하고 삭제하며 순서를 바꾼다면 연결 리스트가 효율적입니다. 하지만 특정 순번의 노래를 바로 틀고 싶다면 선형 리스트가 더 빠릅니다. 실제로 많은 프로그래밍 언어에서는 두 가지를 혼합한 '동적 배열(ArrayList)'을 제공하여 대부분의 상황에서 균형 잡힌 성능을 내도록 합니다.
메모리 측면: 선형 리스트는 미리 큰 공간을 할당해야 하므로 메모리 낭비가 발생할 수 있습니다. 연결 리스트는 필요할 때마다 노드를 생성하므로 메모리를 효율적으로 사용하지만, 포인터 저장을 위한 추가 공간(오버헤드)이 필요합니다.
데이터 구조 시각화 학습 플랫폼의 필요성
선형 리스트와 연결 리스트는 개념 자체는 간단하지만, 포인터가 실제로 어떻게 움직이는지, 삽입/삭제 시 메모리에서 어떤 일이 일어나는지 머릿속으로 그리기 어렵습니다. 특히 연결 리스트의 중간 삽입 과정에서 포인터가 끊어졌다가 다시 연결되는 모습은 초보자에게 큰 혼란을 줍니다.
이때 필요한 것이 바로 '데이터 구조 시각화 학습 플랫폼'입니다. 이 플랫폼은 코드가 실행되는 과정을 애니메이션으로 보여주고, 각 변수와 메모리 상태를 실시간으로 하이라이트하여 추상적인 개념을 구체적인 이미지로 바꿔줍니다.
시각화 플랫폼의 주요 기능과 장점
1. 단계별 실행 (Step-through Execution): 코드 한 줄 한 줄 실행할 때마다 연결 리스트의 노드가 어떻게 생성되고, 포인터가 어떻게 변경되는지 애니메이션으로 보여줍니다. 예를 들어 'head = new Node(5)'라는 코드가 실행되면 화면에 새로운 네모 상자가 나타나고 그 안에 5라는 숫자가 표시됩니다.
2. 실시간 메모리 상태 표시: 현재 메모리에 할당된 모든 노드와 그들의 주소(또는 참조)를 그래픽으로 보여줍니다. 배열의 경우 각 인덱스의 값이 어떻게 저장되어 있는지 한눈에 볼 수 있습니다.
3. 삽입/삭제 시뮬레이션: 중간에 노드를 삽입할 때 기존 노드들의 포인터가 어떻게 바뀌는지, 삭제할 때는 어떻게 연결이 끊어지고 가비지 컬렉션이 일어나는지 시각적으로 추적할 수 있습니다.
4. 다양한 알고리즘 비교: 같은 데이터로 선형 리스트와 연결 리스트에서의 탐색, 삽입, 삭제 속도를 직접 눈으로 비교할 수 있습니다. 이를 통해 각 자료구조의 시간 복잡도를 체감할 수 있습니다.
5. 코드와 시각화 동기화: 왼쪽에는 코드, 오른쪽에는 시각화가 배치되어 코드의 변화가 즉시 그림으로 반영됩니다. 이 기능은 '코드가 실제로 무엇을 하는지'를 직관적으로 이해하게 해줍니다.
시각화 플랫폼 사용 방법 – 초보자 가이드
이 플랫폼은 복잡한 설치 없이 웹 브라우저에서 바로 사용할 수 있습니다. 다음은 간단한 사용 순서입니다.
1단계: 플랫폼에 접속하여 '연결 리스트' 또는 '선형 리스트' 모듈을 선택합니다. 기본적인 예제 코드가 이미 준비되어 있습니다.
2단계: '실행' 버튼을 누르면 코드가 자동으로 실행되면서 시각화가 시작됩니다. '다음 단계' 버튼을 누르면 한 줄씩 진행되며, 각 단계에서 메모리 상태가 어떻게 변하는지 관찰할 수 있습니다.
3단계: 직접 코드를 수정해보세요. 예를 들어 'insert(2, 100)'이라는 코드를 추가하고 실행하면, 연결 리스트의 세 번째 위치에 100이 삽입되는 과정을 애니메이션으로 확인할 수 있습니다.
4단계: 속도 조절 바를 이용해 애니메이션 속도를 느리게 하거나 빠르게 할 수 있습니다. 처음에는 느리게 설정하여 포인터의 변화를 하나하나 따라가는 것이 좋습니다.
5단계: 학습이 끝난 후에는 '퀴즈' 기능을 통해 자신의 이해도를 테스트할 수 있습니다. 시각화 없이도 연결 리스트의 동작을 예측하는 문제가 출제됩니다.
실제 학습 사례 – 연결 리스트 뒤집기(Reverse) 시각화
연결 리스트에서 가장 어려워하는 연산 중 하나가 '뒤집기(Reverse)'입니다. 시각화 플랫폼에서는 이 과정을 3단계로 보여줍니다. 첫째, 현재 노드와 이전 노드를 가리키는 포인터가 생깁니다. 둘째, 현재 노드의 다음 포인터가 이전 노드를 가리키도록 변경됩니다. 셋째, 모든 포인터가 한 칸씩 이동합니다. 이 과정이 반복되면서 리스트의 방향이 완전히 바뀝니다. 이 시각화를 보면 많은 학생들이 "아, 그래서 포인터를 임시 변수에 저장해야 하는구나!"라고 깨닫게 됩니다.
이처럼 시각화는 단순한 암기를 넘어 '원리'를 이해하게 도와줍니다. 특히 연결 리스트의 순환 참조나 널 포인터 오류 같은 미묘한 버그도 시각화를 통해 쉽게 발견할 수 있습니다.
선형 리스트와 연결 리스트의 심화 응용
이 두 자료구조는 더 복잡한 자료구조의 기초가 됩니다. 예를 들어 스택(Stack)과 큐(Queue)는 선형 리스트나 연결 리스트로 구현할 수 있습니다. 해시 테이블의 체이닝(Chaining) 기법은 연결 리스트를 사용하여 충돌을 해결합니다. 그래프(Graph)의 인접 리스트 표현도 연결 리스트의 확장입니다.
또한 운영체제의 프로세스 스케줄링, 웹 브라우저의 방문 기록 관리, 이미지 편집 프로그램의 실행 취소(Undo) 기능 등 실무에서도 광범위하게 사용됩니다. 따라서 이 두 자료구조를 확실히 이해하면 이후에 배울 트리, 그래프, 고급 알고리즘의 이해도가 훨씬 높아집니다.
자주 묻는 질문 (FAQ)
Q: 연결 리스트는 배열보다 항상 느린가요? 아닙니다. 삽입과 삭제가 빈번한 상황에서는 연결 리스트가 훨씬 빠릅니다. 배열은 삽입/삭제 시 데이터를 이동해야 하지만, 연결 리스트는 포인터만 변경하면 되기 때문입니다.
Q: 연결 리스트를 사용할 때 메모리 누수가 발생할 수 있나요? 네, 특히 C/C++ 같은 언어에서는 삭제된 노드의 메모리를 직접 해제하지 않으면 누수가 발생합니다. 시각화 플랫폼에서는 가비지 컬렉션이 어떻게 동작하는지도 보여주어 이런 위험을 인지하게 해줍니다.
Q: 시각화 플랫폼에서 내가 원하는 데이터로 실험할 수 나요? 물론입니다. 대부분의 플랫폼은 사용자 정의 입력을 지원합니다. 직접 숫자 리스트를 입력하거나, 파일에서 데이터를 불러와서 시각화할 수 있습니다.
Q: 이 플랫폼은 무료인가요? 기본적인 자료구조 시각화는 대부분 무료로 제공됩니다. 일부 고급 기능(예: 사용자 정의 알고리즘 저장, 협업 기능)은 유료일 수 있습니다.
결론 – 시각화로 시작하는 탄탄한 자료구조 공부
선형 리스트와 연결 리스트는 모든 자료구조의 기본입니다. 이 두 가지를 제대로 이해하지 못하면 이후의 모든 학습이 흔들릴 수 있습니다. 하지만 막연한 개념 설명만으로는 머릿속에 잘 그려지지 않는 것이 사실입니다. 데이터 구조 시각화 학습 플랫폼은 추상적인 개념을 눈에 보이는 형태로 변환하여 학습 곡선을 크게 낮춰줍니다.
지금 바로 플랫폼에 접속해서 직접 코드를 실행하고, 포인터가 움직이는 모습을 관찰해보세요. 단 30분만 투자해도 배열과 연결 리스트의 차이를 완전히 내 것으로 만들 수 있습니다. 자료구조는 '보면서 이해하는 것'이 가장 빠른 길입니다.