禁止转载,来源:totuma.cn
2.1 顺序表
💡 让我们以一个现实世界的例子来描述计算机中的数组。
想象你在一个图书馆,这个图书馆里有很多书架,每个书架上都有一排排的书。每本书都有一个特定的位置,你可以通过书架的编号和书的位置找到它。
在计算机中,数组就像这个图书馆中的书架一样。它是一个存储相同类型数据元素的数据结构。每个数据元素都有一个唯一的索引或位置,通过这个索引,你可以访问或修改特定位置的数据元素。
在计算机内存中,数组的元素是依次存储的,就像书架上的书一样。这样,计算机可以通过简单的数学运算来计算出元素的内存地址,从而快速访问数组中的任何元素。
数组是一种有效存储和访问大量相似数据的方式,就像图书馆中的书架一样可以帮助你组织和查找大量书籍。
数组是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。
数组中的元素存储在连续的内存位置中,并由一个索引(也称为下标)引用。下标是一个用于标识数组中的元素位置的序号。
2.1.1 数组的声明
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
}
// 完整代码:totuma.cnElemType:是我们要存放的数组元素的类型,类型可以是int, float,,double, char,或者其他可以使用的数据类型;
name:是用来表示数组的,称为数组名;
size:当前数组可以存放的最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
}
// 完整代码:totuma.cn❗ 注意:
在本文后续中提到的所有
索引或下标 都是从 0 开始计数。
位序或第几个 都是从 1 开始计数。
在C 或者 C++ 中,数组索引从零开始。
第一个元素存储在array[0]中,第二个元素存储在array[1]中,以此类推。
因此,最后一个元素,即第6个元素,被存储在array[5]中。
在内存中,数组将如图所示进行存储。注意,方括号内写的0、1、2、3、4、5是下标。
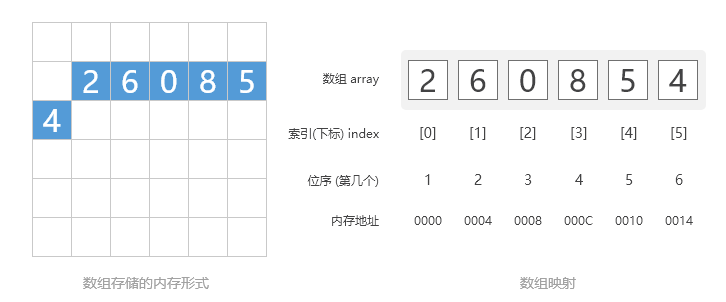
数组及内存结构
1 内存地址的计算
一个int类型的大小在内存中为4bytes。由于数组将其所有数据元素存储在连续的存储器位置中,
因此只需要知道数组首地址,即数组中第一个元素的地址就可以计算出该数组中其他元素的内存地址。
$$公式为:array[index] = base\_address + data\_type\_size \times index$$
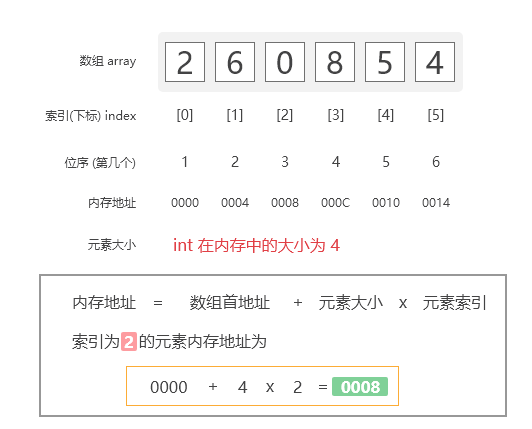
数组内存映射计算
由于数组元素是连续存储在内存的中的,所以我们可以很方便的访问任意一个元素。
就像你在图书馆的书架上查找一本特定的书时,如果你知道它的编号或位置,你可以直接走到该位置,而不必按顺序检查每本书。
在数组中访问元素是非常高效的,可以在$O(1)$时间内随机访问数组中的任意一个元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
}
// 完整代码:totuma.cn在实际编码过程中,我们无需手动计算内存地址,因为每个元素占用大小相同的内存空间,数组元素的起始位置对于计算机也是已知的。 当我们在使用数组的下标来访问元素时,计算机可以通过上述的内存地址计算方法进行计算。
2 修改数组元素
需求:我们将index = 2即第 3 个元素的值修改为3。
操作步骤:
先找到$array[2]$的内存地址,使用上述公式:
$$\begin{split} array[2] &= base\_address + index \times data\_type\_size \\ \Rightarrow array[2] &= 0000 + 2 \times 4\\ \Rightarrow array[2] &= 0008 \end{split}$$
注意上面是计算内存地址,不是赋值
将内存地址为0xFFFF0008的值修改为3。
代码实现比较简单,计算机已自动帮助我们计算内存地址,我们只需提供对应的索引(index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
}
// 完整代码:totuma.cn整个操作的时间复杂度为$O(1)$。
2.1.2 顺序表的介绍
💡 提示:
我们前面已经介绍了数组的知识点:
数组是一种数据结构,用于存储相同类型的元素的集合。
数组是一种顺序存储结构,元素在内存中按照一定的顺序依次存储。
那么数组和线性表的关系是什么呢?
线性表是一种数据结构,其中元素排列成一条线一样的顺序。
这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继。
线性表包括顺序表(数组实现)和链表等。
数组是一种实现线性表的方式之一。线性表可以通过数组来实现,也可以通过链表等其他结构来实现。
因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一。
通过数组实现的线性表称为顺序表。
1 顺序表的定义
线性表的顺序存储类型结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
}
// 完整代码:totuma.cn定义了一个结构体SqList,包含两个成员变量:data和length。
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素。
2 顺序表的初始化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
}
// 完整代码:totuma.cn这个函数的作用是将传入的顺序表 L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
2 在顺序表中插入元素
在顺序表中插入元素分为以下几种情况:
情况一:顺序表未满:插入在末尾
这种情况比较简单,我们只需要在当前最后一个元素的位置+1处直接赋值
例如:下面可视化窗口中的顺序表被声明为最大容量为10个元素,目前它存储了8个元素
步骤:
在末尾插入的位置为:9下标为:8 插入值5。
继续在末尾位置插入值:10
情况二:顺序表已满:不能再插入元素
上面可视化动画在插入了两个元素以后,顺序表总共有10个元素,那么我们将不能再向它添加元素,这种情况我们是不能进行插入的。
情况三:顺序表未满:插入在中间
如果想要在顺序表中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,给要插入的元素腾出位置,之后再把元素赋值给该索引。
步骤:
当前顺序表中已有8个元素,我们在下标为5位序为6处插入值10
注意代码中 i 为位序,不是下标
时间复杂度:
最好情况:如果插入操作发生在顺序表的末尾,并且顺序表有足够的空间,那么插入操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接在末尾添加元素不需要移动其他元素。
最坏情况:如果插入操作发生在顺序表的开头,需要将所有元素向后移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况: 平均情况下,需要移动插入位置后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
4 删除顺序表中的元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单。
我们只需要在当前存放元素的长度 -1 (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
步骤:
下面可视化面板中给出了最大容量为10的顺序表。
此时的顺序表内元素为{ 2, 6, 0, 8, 5, 4, 9, 8 },我们把下标为:3,位序为:4的元素删除掉。
❗ 注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它。
时间复杂度:
最好情况:如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素。
最差情况:如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况:平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序。
正在载入交互式动画窗口请稍等
2.1 顺序表 可视化交互式动画版
在这篇文章中,我们将讨论数据结构中的数组。 数组被定义为存储在连续内存位置的相似类型数据项的集合。 它是最简单的数据结构之一,其中每个数据元素可以通过使用其索引号来随机访问。
在C编程中,它们是可以存储原始类型数据的派生数据类型,例如int、char、double、float等。例如,如果我们要存储一个学生在6个科目上的成绩,那么我们不不需要为不同科目的分数定义不同的变量。 相反,我们可以定义一个数组,将每个主题的标记存储在连续的内存位置。
数组的属性
数组的一些属性如下所示 -
- 数组中的每个元素都具有相同的数据类型,并且具有相同的大小(4 字节)。
- 数组中的元素存储在连续的内存位置,其中第一个元素存储在最小的内存位置。
- 数组的元素可以随机访问,因为我们可以使用给定的基地址和数据元素的大小计算数组中每个元素的地址。
数组的表示
我们可以用不同的编程语言以多种方式表示数组。 作为说明,让我们看一下 C 语言中数组的声明 -
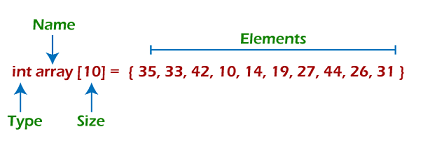
根据上图,有以下一些要点 -
- 索引从0开始。
- 数组的长度是10,这意味着我们可以存储10个元素。
- 数组中的每个元素都可以通过其索引进行访问。
为什么需要数组?
数组很有用,因为 -
- 对数组中的值进行排序和搜索更加容易。
- 数组最适合快速轻松地处理多个值。
- 数组适合在单个变量中存储多个值 - 在计算机编程中,大多数情况需要存储大量相似类型的数据。 为了存储如此大量的数据,我们需要定义大量的变量。 在编写程序时记住所有变量的名称是非常困难的。 与其用不同的名称命名所有变量,不如定义一个数组并将所有元素存储到其中。
数组的内存分配
如上所述,数组的所有数据元素都存储在主存储器中的连续位置。 数组的名称代表基址或主存中第一个元素的地址。 数组的每个元素都由适当的索引表示。
我们可以通过以下方式定义数组的索引 -
- 0(从零开始索引):数组的第一个元素将为 arr[0]。
- 1(基于一的索引):数组的第一个元素为 arr[1]。
- n(基于 n 的索引):数组的第一个元素可以驻留在任意随机索引号处。
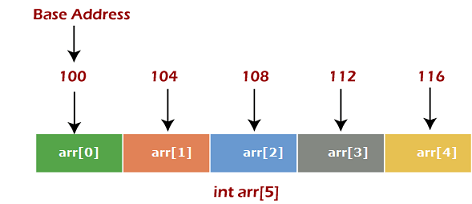
在上图中,我们显示了大小为 5 的数组 arr 的内存分配。该数组遵循从 0 开始的索引方法。 数组的基地址是100字节。 它是arr[0]的地址。 这里,使用的数据类型的大小为4字节; 因此,每个元素将在内存中占用 4 个字节。
如何访问数组中的元素?
我们需要下面给出的信息来访问数组中的任何随机元素 -
- 数组的基地址。
- 元素的大小(以字节为单位)。
- 索引类型,后面是数组。
计算访问数组元素的地址的公式 -
- 元素 A[i] 的字节地址 = 基地址 + 大小 * ( i - 第一个索引)
这里,size代表原始数据类型占用的内存。 例如, C 语言中 int 占用 2 个字节, float占用 4 个字节的内存空间。
我们可以通过一个例子来理解它——
假设一个数组 A[-10 ..... +2 ] 的基地址 (BA) = 999,元素大小 = 2 字节,找到 A[-1] 的位置。
L(A[-1]) = 999 + 2 x [(-1) - (-10)]
= 999 + 18
= 1017
基本操作
现在,让我们讨论数组中支持的基本操作 -
- 遍历 - 此操作用于打印数组的元素。
- 插入 - 用于在特定索引处添加元素。
- 删除 - 用于从特定索引中删除元素。
- 搜索 - 用于使用给定索引或值搜索元素。
- 更新 - 它更新特定索引处的元素。
遍历操作
执行此操作是为了遍历数组元素。 它依次打印所有数组元素。 我们可以通过下面的程序来理解它——
- #include <stdio.h>
- 无效 主(){
- int Arr[5] = {18, 30, 15, 70, 12};
- 整数 我;
- printf( "数组的元素是:\n" );
- for (i = 0; i<5; i++) {
- printf( "Arr[%d] = %d," , i, Arr[i]);
- }
- }
输出
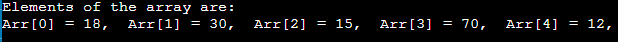
插入操作
执行此操作是为了将一个或多个元素插入到数组中。 根据要求,可以在数组的开头、结尾或任何索引处添加元素。 现在,让我们看看向数组中插入元素的实现。
- #include <stdio.h>
- int main()
- {
- int arr[20] = { 18, 30, 15, 70, 12 };
- int i, x, pos, n = 5;
- printf( "插入之前的数组元素\n" );
- 对于 (i = 0; i < n; i++)
- printf( "%d" , arr[i]);
- printf( “\n” );
- x = 50; //要插入的元素
- 位置=4;
- n++;
- 对于 (i = n-1; i >= pos; i--)
- arr[i] = arr[i - 1];
- arr[位置 - 1] = x;
- printf( "插入后的数组元素\n" );
- 对于 (i = 0; i < n; i++)
- printf( "%d" , arr[i]);
- printf( “\n” );
- 返回 0;
- }
输出

删除操作
顾名思义,此操作从数组中删除一个元素,然后重新组织所有数组元素。
- #include <stdio.h>
- 无效 主(){
- int arr[] = {18, 30, 15, 70, 12};
- 整数 k = 30,n = 5;
- 整数 i,j;
- printf( "给定的数组元素是:\n" );
- for (i = 0; i<n; i++) {
- printf( "arr[%d] = %d," , i, arr[i]);
- }
- j = k;
- 而 (j<n){
- arr[j-1] = arr[j];
- j = j + 1;
- }
- n = n -1;
- printf( "\n删除后数组元素:\n" );
- for (i = 0; i<n; i++) {
- printf( "arr[%d] = %d," , i, arr[i]);
- }
- }
输出
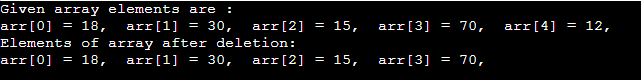
搜索操作
执行此操作是为了根据值或索引搜索数组中的元素。
- #include <stdio.h>
- 无效 主(){
- int arr[5] = {18, 30, 15, 70, 12};
- int item = 70, i, j=0 ;
- printf( "给定的数组元素是:\n" );
- for (i = 0; i<5; i++) {
- printf( "arr[%d] = %d," , i, arr[i]);
- }
- printf( "\n要搜索的元素 = %d" , item);
- 而 ( j < 5){
- if ( arr[j] == 项目 ) {
- 打破 ;
- }
- j = j + 1;
- }
- printf( "\n元素 %d 在 %d 位置找到" , item, j+1);
- }
输出
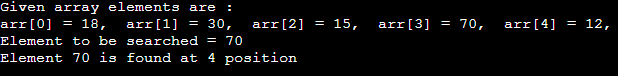
更新操作
执行此操作是为了更新位于给定索引处的现有数组元素。
- #include <stdio.h>
- 无效 主(){
- int arr[5] = {18, 30, 15, 70, 12};
- int item = 50,i,pos = 3;
- printf( "给定的数组元素是:\n" );
- for (i = 0; i<5; i++) {
- printf( "arr[%d] = %d," , i, arr[i]);
- }
- arr[pos-1] = 项目;
- printf( "\n更新后的数组元素:\n" );
- for (i = 0; i<5; i++) {
- printf( "arr[%d] = %d," , i, arr[i]);
- }
- }
输出
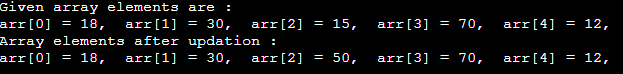
数组操作的复杂性
下表描述了各种数组操作的时间和空间复杂度。
时间复杂度
| 手术 | 平均情况 | 最坏的情况下 |
|---|---|---|
| 使用权 | 复杂度(1) | 复杂度(1) |
| 搜索 | 在) | 在) |
| 插入 | 在) | 在) |
| 删除 | 在) | 在) |
空间复杂度
在数组中,最坏情况的空间复杂度为 O(n) 。
数组的优点
- 数组为同一类型的变量组提供单一名称。 因此,很容易记住数组所有元素的名称。
- 遍历数组是一个非常简单的过程; 我们只需要增加数组的基地址就可以一一访问每个元素。
- 数组中的任何元素都可以通过索引直接访问。
数组的缺点
- 数组是同质的。 这意味着可以在其中存储具有相似数据类型的元素。
- 在数组中,存在静态内存分配,即数组的大小无法更改。
- 如果我们存储的元素数量少于声明的大小,就会浪费内存。
结论
在本文中,我们讨论了特殊的数据结构,即数组,以及对其执行的基本操作。 数组提供了一种独特的方式来构造存储的数据,以便可以轻松访问并使用索引进行查询以获取值。
二维数组可以定义为数组的数组。 二维数组被组织为矩阵,可以表示为行和列的集合。
然而,创建二维数组是为了实现类似于关系数据库的数据结构。 它可以轻松地一次保存大量数据,这些数据可以在需要时传递到任意数量的函数。
如何声明二维数组
声明二维数组的语法与一维数组的语法非常相似,如下所示。
- int arr[最大行数][最大列数];
但是,它生成的数据结构如下所示。
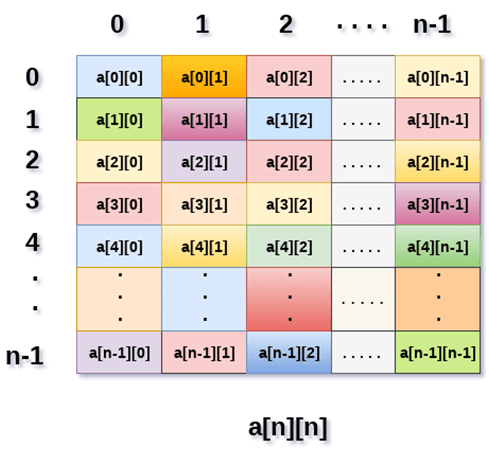
上图显示了二维数组,元素以行和列的形式组织。 第一行的第一个元素由 a[0][0] 表示,其中第一个索引中显示的数字是该行的编号,而第二个索引中显示的数字是列的编号。
我们如何访问二维数组中的数据
由于二维数组的元素可以随机访问。 与一维数组类似,我们可以使用单元格的索引来访问二维数组中的各个单元格。 特定单元格有两个索引,一个是其行号,另一个是其列号。
但是,我们可以使用以下语法将存储在 2D 数组的任何特定单元格中的值存储到某个变量 x 中。
- int x = a[i][j];
其中 i 和 j 分别是单元格的行号和列号。
我们可以使用以下代码将 2D 数组的每个单元格分配为 0:
- for ( int i= 0 ; i<n ;i++)
- {
- for ( int j= 0 ; j<n; j++)
- {
- a[i][j] = 0 ;
- }
- }
初始化二维数组
我们知道,在C编程中同时声明和初始化一维数组时,不需要指定数组的大小。 然而,这不适用于二维数组。 我们必须至少定义数组的第二个维度。
声明和初始化二维数组的语法如下。
- int arr[ 2 ][ 2 ] = { 0 , 1 , 2 , 3 };
二维数组中可以存在的元素数量始终等于( 行数 * 列数 )。
示例: 将用户数据存储到二维数组中并打印。
C 示例:
- #include <stdio.h>
- 无效 主()
- {
- int arr[ 3 ][ 3 ],i,j;
- 对于 (i= 0 ;i< 3 ;i++)
- {
- 对于 (j= 0 ;j< 3 ;j++)
- {
- printf( "输入a[%d][%d]:" ,i,j);
- scanf( "%d" ,&arr[i][j]);
- }
- }
- printf( "\n 打印元素 ....\n" );
- 对于 (i= 0 ;i< 3 ;i++)
- {
- printf( “\n” );
- 对于 (j= 0 ;j< 3 ;j++)
- {
- printf( "%d\t" ,arr[i][j]);
- }
- }
- }
Java示例
- 导入 java.util.Scanner;
- 公共类 TwoDArray {
- publicstaticvoid main(String[] args) {
- int [][] arr = newint[ 3 ][ 3 ];
- 扫描仪 sc = 新 扫描仪(System.in);
- 对于 (inti = 0 ;i< 3 ;i++)
- {
- 对于 (intj= 0 ;j< 3 ;j++)
- {
- System.out.print( "输入元素" );
- arr[i][j]=sc.nextInt();
- System.out.println();
- }
- }
- System.out.println( "打印元素..." );
- 对于 (inti= 0 ;i< 3 ;i++)
- {
- System.out.println();
- 对于 (intj= 0 ;j< 3 ;j++)
- {
- System.out.print(arr[i][j]+ "\t" );
- }
- }
- }
- }
C# 示例
- 使用系统;
- 公开 课 节目
- {
- 公共 静态 无效 Main()
- {
- int [,] arr = 新 int [ 3 , 3 ];
- for ( int i= 0 ;i< 3 ;i++)
- {
- for ( int j= 0 ;j< 3 ;j++)
- {
- Console.WriteLine( "输入元素" );
- arr[i,j]= Convert.ToInt32(Console.ReadLine());
- }
- }
- Console.WriteLine( "正在打印元素..." );
- for ( int i= 0 ;i< 3 ;i++)
- {
- Console.WriteLine();
- for ( int j= 0 ;j< 3 ;j++)
- {
- Console.Write(arr[i,j]+ " " );
- }
- }
- }
- }
将 2D 数组映射到 1D 数组
当谈到映射二维数组时,我们大多数人可能会想到为什么需要这种映射。 然而,从用户的角度来看,二维数组是存在的。 创建二维数组是为了实现类似关系数据库表的数据结构,在计算机内存中,二维数组的存储技术类似于一维数组。
二维数组的大小等于数组中的行数和列数的乘积。 我们确实需要将二维数组映射到一维数组,以便将它们存储在内存中。
下图显示了 3 X 3 二维数组。 然而,这个数组需要映射到一维数组才能将其存储到内存中。
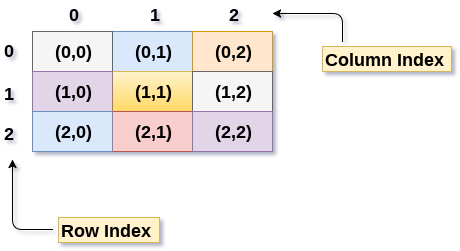
将二维数组元素存储到内存中的主要技术有两种
1.行主排序
在行主排序中,二维数组的所有行都连续存储到内存中。 考虑到上图中显示的数组,其根据行主顺序的内存分配如下所示。
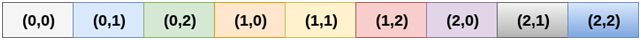
首先,将 数组的第一行完全存储到内存中,然后将数组的第二 行 完全存储到内存中,依此类推,直到最后一行 。
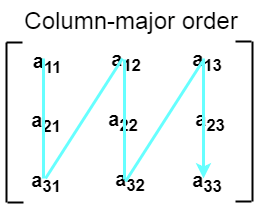
2. 栏目主要排序
根据列主排序,二维数组的所有列都连续存储到内存中。 上图中所示数组的内存分配如下。
首先,将数组的第一 列 完全存储到内存中,然后将 数组的第二行完全存储到内存中,依此类推,直到数组的最后一列 。
计算二维数组的随机元素的地址
由于存在两种不同的将二维数组存储到内存中的技术,因此有两种不同的公式来计算二维数组的随机元素的地址。
按行主要顺序
如果数组由 a[m][n] 声明,其中 m 是行数,n 是列数,则按行主序存储的数组元素 a[i][j] 的地址计算如下,
- 地址(a[i][j]) = B.A. + (i * n + j) * 大小
其中, BA 是基地址或数组 a[0][0] 的第一个元素的地址。
例子 :
- a[ 10 ... 30 , 55 ... 75 ],数组基地址 (BA) = 0 ,元素大小 = 4 个 字节。
- 找到a[ 15 ][ 68 ]的位置 。
- 地址(a[ 15 ][ 68 ]) = 0 +
- (( 15-10 ) × ( 68-55 + 1 ) + ( 68-55 ) ) × 4
- = ( 5 x 14 + 13 ) x 4
- = 83 x 4
- = 332 个 答案
按栏目主要顺序
如果数组由 a[m][n] 声明,其中 m 是行数,n 是列数,则按行主序存储的数组元素 a[i][j] 的地址计算如下,
- 地址(a[i][j]) = ((j*m)+i)*大小 + BA
其中 BA 是数组的基地址。
例子:
- A [- 5 ... + 20 ][ 20 ... 70 ],BA = 1020 ,元素大小 = 8 字节。 找到a[ 0 ][ 30 ] 的位置 。
- 地址 [A[ 0 ][ 30 ]) = (( 30 - 20 ) x 24 + 5 ) x 8 + 1020 = 245 x 8 + 1020 = 2980 字节
时间复杂度:
最好情况:要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为$O(1)$,即常数时间复杂度。
最坏情况:要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中。在这种情况下,时间复杂度为$O(n)$,其中$n$是顺序表中元素的个数。
平均情况:平均情况的时间复杂度通常是$O(\frac n 2)$,因为平均而言,我们可以认为要查找的元素在顺序表的中间位置。但是在大$O$表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是$O(n)$。
2.1.3 顺序表数组实现的优点与缺点
1 优点
随机访问速度快:由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 $O(1)$。这使得数组在需要频繁随机访问元素的情况下非常高效。
节约空间:相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间。
缓存友好:由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势。
2 缺点
固定大小:数组的大小是固定的,一旦创建后就不能动态改变。如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销。
插入和删除操作效率低:在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 $O(n)$。这使得数组在频繁插入和删除操作的场景下效率较低。
不适合存储变长数据:由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求。