禁止转载,来源:totuma.cn
2.2 单链表
💡 有了数组为什么还要链表?
在前面我们介绍过数组,数组中元素是存储在连续的内存位置 在声明数组时,我们可以指定数组的大小,但这将限制数组可以存储的元素数量 例如我们声明的是 int arr[10],那么arr数组最多可以存储10个数据元素 但是我们事先不知道元素的大小呢? 我们该如何去做?
当然首先想到的是申请一个足够大的数组,但是内存中可能会没有足够大的连续内存空间
那么我们能不能设计一种数据结构,合理的利用内存的中的非连续空间呢?
链表是一种非常灵活的动态数据结构,也是一种线性表。但是并不会按线性的顺序存储数据,而是在每一个节点里存入到下一个节点的指针。链表是由数据域和指针域两部分组成的,它的组成结构如下:链表不会将其元素存储在连续的内存位置中,所以我们可以任意添加链表元素的数量。
单链表
线性表的链式存储也被称为单链表,是一种常见的数据结构,由一系列节点组成。
每个节点包含两部分:数据和指向下一个节点的指针。单链表的特点是节点之间通过指针相连,形成一个线性结构。
- data:数据域,也是节点的值
- next:指针域,指向下一个结点的指针
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
typedef struct LNode {
int data; // 数据域
struct LNode * next; // 指针域
} LNode, *LinkList;
// 完整代码:totuma.cn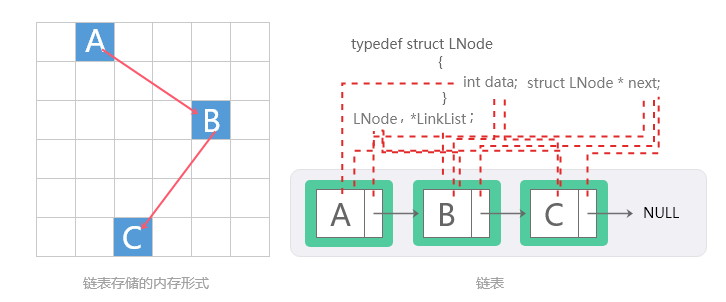
链表结构
💡之所以称为单链表,并不是指它是只有一个链表结点组成,是为了明确它是“单向的”,即每个节点只包含一个指向下一个结点的指针。 这与后面要讲的双向链表不同,所以也可以把单链表称为单向链表。
单链表和数组都是常见的数据结构,各有优缺点。
单链表的节点在需要时动态分配内存,这意味着不需要像数组那样在创建时预先分配一大片连续内存。因此,单链表在内存使用上更加灵活,可以有效应对内存碎片和动态增长的问题。
由于链表节点是在需要时分配的,可以避免数组因初始化大小不确定而造成的内存浪费。例如,如果数组大小初始化过大,未使用的部分将浪费内存;若初始化过小,则可能需要频繁重新分配和复制。
每个节点需要一个指针域来存储对下一个节点的引用,这意味着相比于数组,单链表在每个节点上都会有额外的内存开销。对于存储小数据的场景,这个开销相对较大,可能导致内存利用率下降。
链表中的一些概念
头结点
在单链表的开始结点之前设立一个节点称之为头结点(也称为哨兵节点或哑节点),头结点的数据域可以不存储任何信息,也可以存储链表的长度等附加信息,头结点的指针域存储指向第一个结点(首元结点)的指针。
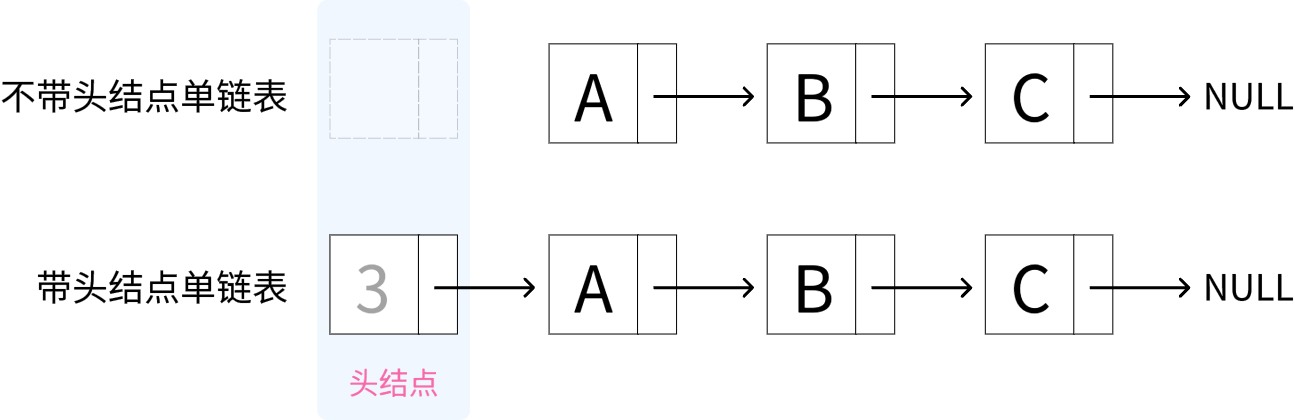
带头和不带头结点区别
头指针
头指针是指链表中,指向第一个结点的指针。
头指针具有标识作用,所以常常会用头指针冠以链表的名字。所以你定义一个链表,那么链表的名字一般就是这个链表的头指针。
ListNode L = new ListNode(0); 左边的是指针和结点
无论链表是否为空,头指针均不为空,头指针是链表的必要元素。
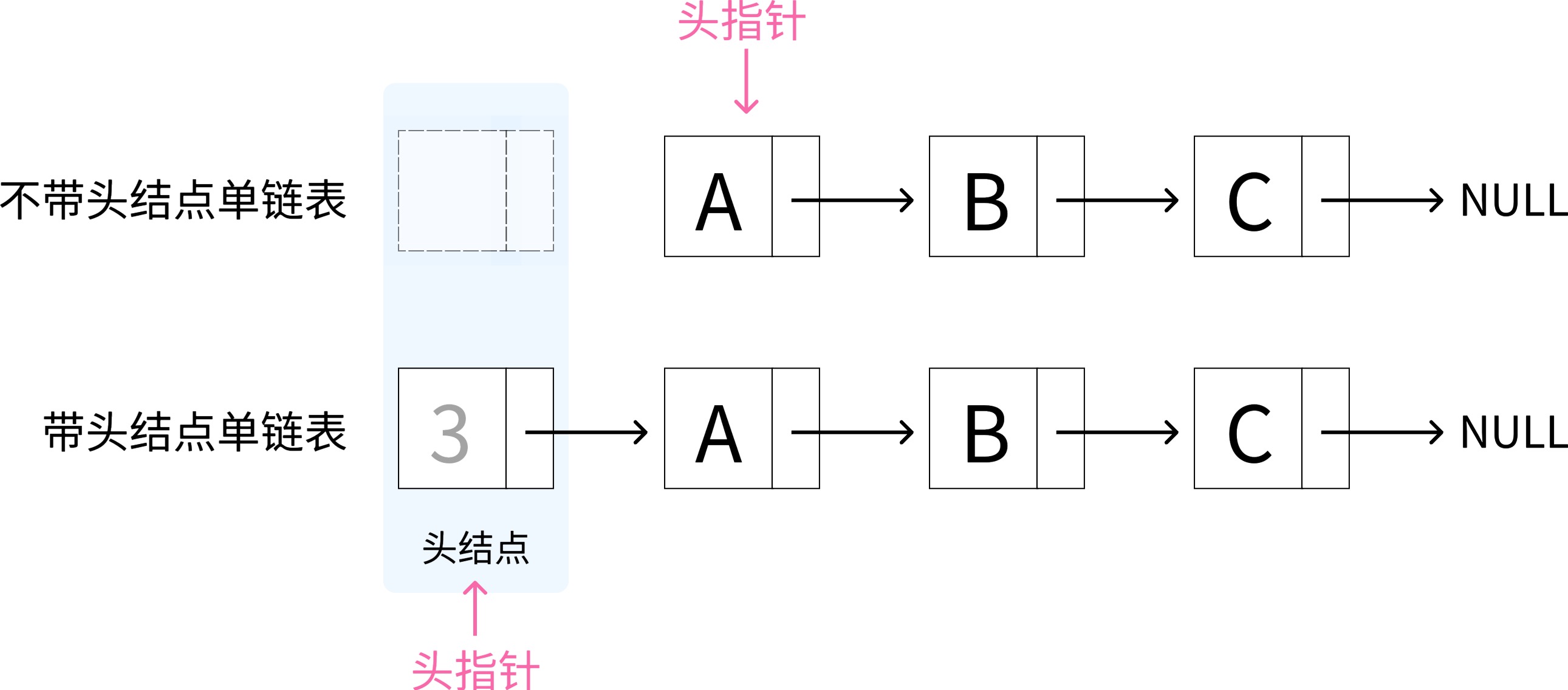
带头和不带头结点区别
首元结点
链表中第一个元素所在的结点,它是头结点后边的第一个结点。如果是带头结点的链表,则头结点后面的为首元结点。
元素是指链表中实际存储数据的结点,像头结点就不属于元素,因为它存储的不是数据,而是一些链表的属性信息(链表长度)或者为空。
带头和不带头结点区别
💡 整理成一句话就是
- 头指针:指向第一个结点
- 头结点:在首元结点前面设立一个结点
- 首元结点:链表中第一个元素所在的结点
- 元素结点:存储链表实际信息的结点
带头结点和不带头结点的区别
在带头结点的链表中,链表的第一个节点是一个特殊的节点,称为头节点,它不存储数据(或存储链表长度),仅用于简化链表的操作。
引入头结点后的优点
- 插入操作:在插入新节点时,无论插入位置是链表头部、中间还是尾部,处理逻辑一致,无需特别处理第一个节点。
- 删除操作:在删除节点时,无论删除的是第一个节点还是其他节点,处理逻辑一致,无需特别处理第一个节点。
- 判空操作: 空链表和非空链表的处理逻辑一致,因为头节点始终存在。
带头和不带头结点的链表在遍历方面处理逻辑无大差别。
带头结点的单链表代码实现
共6种函数代码
- 头插法创建链表
- 尾插法创建链表
- 按值查找结点
- 按位序插入结点
- 按位序删除结点
头插法创建链表
该代码通过头插法创建一个链表。 头插法的特点是每插入一个新节点,链表的头节点就会变成新插入的节点,从而使得输入的数据在链表中是倒序存储的。 当输入数据为 999 时,创建链表的循环结束,函数返回最终的链表头节点。
正在载入交互式动画窗口请稍等
2.2 单链表 可视化交互式动画版
在这篇文章中,我们将看到链表的介绍。
链表是一种线性数据结构,包含一系列相连的节点。 链表可以定义为随机存储在内存中的节点。 链表中的节点包含两部分,第一部分是数据部分,第二部分是地址部分。 列表的最后一个节点包含一个指向空值的指针。 链表是继数组之后第二常用的数据结构。 在链表中,每个链接都包含到另一个链接的连接。
链表的表示
链表可以表示为节点的连接,其中每个节点都指向链表的下一个节点。 链表的表示如下所示 -
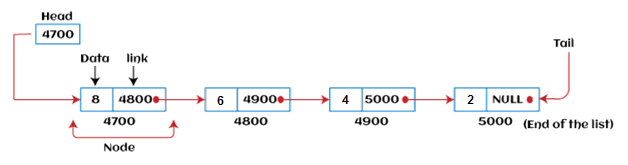
到目前为止,我们一直使用数组数据结构来组织要单独存储在内存中的元素组。 然而,数组有几个优点和缺点,必须了解这些优点和缺点才能决定在整个程序中使用的数据结构。
现在,问题来了,为什么我们应该使用链表而不是数组?
为什么使用链表而不是数组?
链表是一种克服数组局限性的数据结构。 让我们首先看看数组的一些限制 -
- 在程序中使用数组之前必须事先知道数组的大小。
- 增加数组的大小是一个耗时的过程。 在运行时扩展数组的大小几乎是不可能的。
- 数组中的所有元素都需要连续存储在内存中。 在数组中插入一个元素需要移动其所有前驱元素。
链接列表很有用,因为 -
- 它动态分配内存。 链表的所有节点在内存中都是不连续存储的,并通过指针链接在一起。
- 在链表中,大小不再是问题,因为我们不需要在声明时定义其大小。 列表根据程序的需求而增长,并受到可用内存空间的限制。
如何声明一个链表?
数组的声明很简单,因为它是单一类型,而链表的声明比数组更典型一些。 链表包含两部分,两部分的类型不同,一是简单变量,二是指针变量。 我们可以使用用户定义的数据类型结构来声明链表 。
链表的声明如下 -
- 结构节点
- {
- 整数数据;
- 结构节点*下一个;
- }
在上面的声明中,我们定义了一个名为 node的 结构体,它包含两个变量,一个是整数类型的 数据 ,另一个是 next ,它是一个指针,包含下一个节点的地址。
现在,让我们转向链表的类型。
链表的类型
链表分为以下几种类型 -
- 单链表 - 单链表可以定义为有序元素集的集合。 单链表中的节点由两部分组成:数据部分和链接部分。 节点的数据部分存储该节点要表示的实际信息,而节点的链接部分存储其直接后继的地址。
- 双向链表 - 双向链表是一种复杂类型的链表,其中节点包含指向序列中前一个节点和下一个节点的指针。 因此,在双向链表中,一个节点由三部分组成:节点数据、指向序列中下一个节点的指针(next指针)、指向前一个节点的指针(previous指针)。
- 循环单链表 - 在循环单链表中,列表的最后一个节点包含指向列表的第一个节点的指针。 我们可以有循环单链表,也可以有循环双链表。
- 循环双向链表 - 循环双向链表是一种更复杂的数据结构类型,其中节点包含指向其前一个节点以及下一个节点的指针。 循环双向链表的任何节点中都不包含 NULL。 列表的最后一个节点包含列表的第一个节点的地址。 列表的第一个节点还包含其前一个指针中最后一个节点的地址。
现在,让我们看看使用链接列表的好处和局限性。
链表的优点
使用链表的优点如下:
- 动态数据结构—— 链表的大小可能根据需求而变化。 链表没有固定的大小。
- 插入和删除 - 与数组不同,链表中的插入和删除更容易。 数组元素存储在连续位置,而链表中的元素存储在随机位置。 要在数组中插入或删除元素,我们必须移动元素以创建空间。 而在链表中,我们不需要移位,只需更新节点指针的地址即可。
- 内存高效 - 链表的大小可以根据需要增长或缩小,因此链表中的内存消耗是高效的。
- 实现 - 我们可以使用链表来实现堆栈和队列。
链表的缺点
使用链表的限制如下:
- 内存使用 - 在链表中,节点比数组占用更多内存。 链表的每个节点占用两种类型的变量,一种是简单变量,另一种是指针变量。
- 遍历 - 在链表中遍历并不容易。 如果我们必须访问链表中的一个元素,我们不能随机访问它,而如果是数组,我们可以通过索引随机访问它。 例如,如果我们要访问第3个节点,那么我们需要遍历它之前的所有节点。 因此,访问特定节点所需的时间很大。
- 反向遍历 - 在链表中回溯或反向遍历是很困难的。 在双向链表中,它更容易,但需要更多内存来存储后向指针。
链表的应用
链表的应用如下:
- 借助链表,可以表示多项式,也可以对多项式进行运算。
- 可以使用链表来表示稀疏矩阵。
- 诸如学生详细信息、员工详细信息或产品详细信息之类的各种操作都可以使用链表来实现,因为链表使用可以容纳不同数据类型的结构数据类型。
- 使用链表,我们可以实现栈、队列、树等各种数据结构。
- 图是边和顶点的集合,图可以表示为邻接矩阵和邻接表。 如果我们想将图表示为邻接矩阵,那么可以将其实现为数组。 如果我们想将图表示为邻接表,那么可以将其实现为链表。
- 链表可以用来实现动态内存分配。 动态内存分配是在运行时完成的内存分配。
对链表执行的操作
列表支持的基本操作如下:
- 插入 - 执行此操作以将元素添加到列表中。
- 删除 - 执行从列表中删除操作。
- 显示 - 执行以显示列表的元素。
- 搜索 - 使用给定的键从列表中搜索元素。
链表的复杂性
现在,让我们看看链表的搜索、插入和删除操作的时间和空间复杂度。
1. 时间复杂度
| 运营 | 平均案例时间复杂度 | 最坏情况时间复杂度 |
|---|---|---|
| 插入 | 复杂度(1) | 复杂度(1) |
| 删除 | 复杂度(1) | 复杂度(1) |
| 搜索 | 在) | 在) |
其中“n”是给定树中的节点数。
2. 空间复杂度
| 运营 | 空间复杂度 |
|---|---|
| 插入 | 在) |
| 删除 | 在) |
| 搜索 | 在) |
链表的空间复杂度是 O(n)。
那么,链表的介绍就到此为止了。 希望这篇文章能给您带来帮助和信息。
尾插法创建链表
该代码通过尾插法创建一个链表。 尾插法的特点是每插入一个新节点,链表的尾节点指针(pTail)会更新为新插入的节点,使其始终指向当前链表的尾结点。从而使得输入的数据在链表中按顺序存储。 当输入数据为 999 时,循环结束,将尾节点的 next 指针置为 NULL 表示链表结束,函数返回最终的链表头节点。
正在载入交互式动画窗口请稍等
2.2 单链表 可视化交互式动画版
在这篇文章中,我们将看到链表的介绍。
链表是一种线性数据结构,包含一系列相连的节点。 链表可以定义为随机存储在内存中的节点。 链表中的节点包含两部分,第一部分是数据部分,第二部分是地址部分。 列表的最后一个节点包含一个指向空值的指针。 链表是继数组之后第二常用的数据结构。 在链表中,每个链接都包含到另一个链接的连接。
链表的表示
链表可以表示为节点的连接,其中每个节点都指向链表的下一个节点。 链表的表示如下所示 -
到目前为止,我们一直使用数组数据结构来组织要单独存储在内存中的元素组。 然而,数组有几个优点和缺点,必须了解这些优点和缺点才能决定在整个程序中使用的数据结构。
现在,问题来了,为什么我们应该使用链表而不是数组?
为什么使用链表而不是数组?
链表是一种克服数组局限性的数据结构。 让我们首先看看数组的一些限制 -
- 在程序中使用数组之前必须事先知道数组的大小。
- 增加数组的大小是一个耗时的过程。 在运行时扩展数组的大小几乎是不可能的。
- 数组中的所有元素都需要连续存储在内存中。 在数组中插入一个元素需要移动其所有前驱元素。
链接列表很有用,因为 -
- 它动态分配内存。 链表的所有节点在内存中都是不连续存储的,并通过指针链接在一起。
- 在链表中,大小不再是问题,因为我们不需要在声明时定义其大小。 列表根据程序的需求而增长,并受到可用内存空间的限制。
如何声明一个链表?
数组的声明很简单,因为它是单一类型,而链表的声明比数组更典型一些。 链表包含两部分,两部分的类型不同,一是简单变量,二是指针变量。 我们可以使用用户定义的数据类型结构来声明链表 。
链表的声明如下 -
- 结构节点
- {
- 整数数据;
- 结构节点*下一个;
- }
在上面的声明中,我们定义了一个名为 node的 结构体,它包含两个变量,一个是整数类型的 数据 ,另一个是 next ,它是一个指针,包含下一个节点的地址。
现在,让我们转向链表的类型。
链表的类型
链表分为以下几种类型 -
- 单链表 - 单链表可以定义为有序元素集的集合。 单链表中的节点由两部分组成:数据部分和链接部分。 节点的数据部分存储该节点要表示的实际信息,而节点的链接部分存储其直接后继的地址。
- 双向链表 - 双向链表是一种复杂类型的链表,其中节点包含指向序列中前一个节点和下一个节点的指针。 因此,在双向链表中,一个节点由三部分组成:节点数据、指向序列中下一个节点的指针(next指针)、指向前一个节点的指针(previous指针)。
- 循环单链表 - 在循环单链表中,列表的最后一个节点包含指向列表的第一个节点的指针。 我们可以有循环单链表,也可以有循环双链表。
- 循环双向链表 - 循环双向链表是一种更复杂的数据结构类型,其中节点包含指向其前一个节点以及下一个节点的指针。 循环双向链表的任何节点中都不包含 NULL。 列表的最后一个节点包含列表的第一个节点的地址。 列表的第一个节点还包含其前一个指针中最后一个节点的地址。
现在,让我们看看使用链接列表的好处和局限性。
链表的优点
使用链表的优点如下:
- 动态数据结构—— 链表的大小可能根据需求而变化。 链表没有固定的大小。
- 插入和删除 - 与数组不同,链表中的插入和删除更容易。 数组元素存储在连续位置,而链表中的元素存储在随机位置。 要在数组中插入或删除元素,我们必须移动元素以创建空间。 而在链表中,我们不需要移位,只需更新节点指针的地址即可。
- 内存高效 - 链表的大小可以根据需要增长或缩小,因此链表中的内存消耗是高效的。
- 实现 - 我们可以使用链表来实现堆栈和队列。
链表的缺点
使用链表的限制如下:
- 内存使用 - 在链表中,节点比数组占用更多内存。 链表的每个节点占用两种类型的变量,一种是简单变量,另一种是指针变量。
- 遍历 - 在链表中遍历并不容易。 如果我们必须访问链表中的一个元素,我们不能随机访问它,而如果是数组,我们可以通过索引随机访问它。 例如,如果我们要访问第3个节点,那么我们需要遍历它之前的所有节点。 因此,访问特定节点所需的时间很大。
- 反向遍历 - 在链表中回溯或反向遍历是很困难的。 在双向链表中,它更容易,但需要更多内存来存储后向指针。
链表的应用
链表的应用如下:
- 借助链表,可以表示多项式,也可以对多项式进行运算。
- 可以使用链表来表示稀疏矩阵。
- 诸如学生详细信息、员工详细信息或产品详细信息之类的各种操作都可以使用链表来实现,因为链表使用可以容纳不同数据类型的结构数据类型。
- 使用链表,我们可以实现栈、队列、树等各种数据结构。
- 图是边和顶点的集合,图可以表示为邻接矩阵和邻接表。 如果我们想将图表示为邻接矩阵,那么可以将其实现为数组。 如果我们想将图表示为邻接表,那么可以将其实现为链表。
- 链表可以用来实现动态内存分配。 动态内存分配是在运行时完成的内存分配。
对链表执行的操作
列表支持的基本操作如下:
- 插入 - 执行此操作以将元素添加到列表中。
- 删除 - 执行从列表中删除操作。
- 显示 - 执行以显示列表的元素。
- 搜索 - 使用给定的键从列表中搜索元素。
链表的复杂性
现在,让我们看看链表的搜索、插入和删除操作的时间和空间复杂度。
1. 时间复杂度
| 运营 | 平均案例时间复杂度 | 最坏情况时间复杂度 |
|---|---|---|
| 插入 | 复杂度(1) | 复杂度(1) |
| 删除 | 复杂度(1) | 复杂度(1) |
| 搜索 | 在) | 在) |
其中“n”是给定树中的节点数。
2. 空间复杂度
| 运营 | 空间复杂度 |
|---|---|
| 插入 | 在) |
| 删除 | 在) |
| 搜索 | 在) |
链表的空间复杂度是 O(n)。
那么,链表的介绍就到此为止了。 希望这篇文章能给您带来帮助和信息。
按值查找结点
该代码实现了通过值查找链表节点的功能。 它从链表的第一个数据节点开始遍历,查找具有指定值的节点,并返回该节点及其位序。如果未找到该值,则返回NULL。
💡 注意
注意位序和索引(下标)的区别,还不了解的话可以查看上一章节的数组实现。
带头结点的链表值从头结点后面开始,所以 i 初始化为 1 ,则表示从链表的第一个数据节点开始。
正在载入交互式动画窗口请稍等
2.2 单链表 可视化交互式动画版
在这篇文章中,我们将看到链表的介绍。
链表是一种线性数据结构,包含一系列相连的节点。 链表可以定义为随机存储在内存中的节点。 链表中的节点包含两部分,第一部分是数据部分,第二部分是地址部分。 列表的最后一个节点包含一个指向空值的指针。 链表是继数组之后第二常用的数据结构。 在链表中,每个链接都包含到另一个链接的连接。
链表的表示
链表可以表示为节点的连接,其中每个节点都指向链表的下一个节点。 链表的表示如下所示 -
到目前为止,我们一直使用数组数据结构来组织要单独存储在内存中的元素组。 然而,数组有几个优点和缺点,必须了解这些优点和缺点才能决定在整个程序中使用的数据结构。
现在,问题来了,为什么我们应该使用链表而不是数组?
为什么使用链表而不是数组?
链表是一种克服数组局限性的数据结构。 让我们首先看看数组的一些限制 -
- 在程序中使用数组之前必须事先知道数组的大小。
- 增加数组的大小是一个耗时的过程。 在运行时扩展数组的大小几乎是不可能的。
- 数组中的所有元素都需要连续存储在内存中。 在数组中插入一个元素需要移动其所有前驱元素。
链接列表很有用,因为 -
- 它动态分配内存。 链表的所有节点在内存中都是不连续存储的,并通过指针链接在一起。
- 在链表中,大小不再是问题,因为我们不需要在声明时定义其大小。 列表根据程序的需求而增长,并受到可用内存空间的限制。
如何声明一个链表?
数组的声明很简单,因为它是单一类型,而链表的声明比数组更典型一些。 链表包含两部分,两部分的类型不同,一是简单变量,二是指针变量。 我们可以使用用户定义的数据类型结构来声明链表 。
链表的声明如下 -
- 结构节点
- {
- 整数数据;
- 结构节点*下一个;
- }
在上面的声明中,我们定义了一个名为 node的 结构体,它包含两个变量,一个是整数类型的 数据 ,另一个是 next ,它是一个指针,包含下一个节点的地址。
现在,让我们转向链表的类型。
链表的类型
链表分为以下几种类型 -
- 单链表 - 单链表可以定义为有序元素集的集合。 单链表中的节点由两部分组成:数据部分和链接部分。 节点的数据部分存储该节点要表示的实际信息,而节点的链接部分存储其直接后继的地址。
- 双向链表 - 双向链表是一种复杂类型的链表,其中节点包含指向序列中前一个节点和下一个节点的指针。 因此,在双向链表中,一个节点由三部分组成:节点数据、指向序列中下一个节点的指针(next指针)、指向前一个节点的指针(previous指针)。
- 循环单链表 - 在循环单链表中,列表的最后一个节点包含指向列表的第一个节点的指针。 我们可以有循环单链表,也可以有循环双链表。
- 循环双向链表 - 循环双向链表是一种更复杂的数据结构类型,其中节点包含指向其前一个节点以及下一个节点的指针。 循环双向链表的任何节点中都不包含 NULL。 列表的最后一个节点包含列表的第一个节点的地址。 列表的第一个节点还包含其前一个指针中最后一个节点的地址。
现在,让我们看看使用链接列表的好处和局限性。
链表的优点
使用链表的优点如下:
- 动态数据结构—— 链表的大小可能根据需求而变化。 链表没有固定的大小。
- 插入和删除 - 与数组不同,链表中的插入和删除更容易。 数组元素存储在连续位置,而链表中的元素存储在随机位置。 要在数组中插入或删除元素,我们必须移动元素以创建空间。 而在链表中,我们不需要移位,只需更新节点指针的地址即可。
- 内存高效 - 链表的大小可以根据需要增长或缩小,因此链表中的内存消耗是高效的。
- 实现 - 我们可以使用链表来实现堆栈和队列。
链表的缺点
使用链表的限制如下:
- 内存使用 - 在链表中,节点比数组占用更多内存。 链表的每个节点占用两种类型的变量,一种是简单变量,另一种是指针变量。
- 遍历 - 在链表中遍历并不容易。 如果我们必须访问链表中的一个元素,我们不能随机访问它,而如果是数组,我们可以通过索引随机访问它。 例如,如果我们要访问第3个节点,那么我们需要遍历它之前的所有节点。 因此,访问特定节点所需的时间很大。
- 反向遍历 - 在链表中回溯或反向遍历是很困难的。 在双向链表中,它更容易,但需要更多内存来存储后向指针。
链表的应用
链表的应用如下:
- 借助链表,可以表示多项式,也可以对多项式进行运算。
- 可以使用链表来表示稀疏矩阵。
- 诸如学生详细信息、员工详细信息或产品详细信息之类的各种操作都可以使用链表来实现,因为链表使用可以容纳不同数据类型的结构数据类型。
- 使用链表,我们可以实现栈、队列、树等各种数据结构。
- 图是边和顶点的集合,图可以表示为邻接矩阵和邻接表。 如果我们想将图表示为邻接矩阵,那么可以将其实现为数组。 如果我们想将图表示为邻接表,那么可以将其实现为链表。
- 链表可以用来实现动态内存分配。 动态内存分配是在运行时完成的内存分配。
对链表执行的操作
列表支持的基本操作如下:
- 插入 - 执行此操作以将元素添加到列表中。
- 删除 - 执行从列表中删除操作。
- 显示 - 执行以显示列表的元素。
- 搜索 - 使用给定的键从列表中搜索元素。
链表的复杂性
现在,让我们看看链表的搜索、插入和删除操作的时间和空间复杂度。
1. 时间复杂度
| 运营 | 平均案例时间复杂度 | 最坏情况时间复杂度 |
|---|---|---|
| 插入 | 复杂度(1) | 复杂度(1) |
| 删除 | 复杂度(1) | 复杂度(1) |
| 搜索 | 在) | 在) |
其中“n”是给定树中的节点数。
2. 空间复杂度
| 运营 | 空间复杂度 |
|---|---|
| 插入 | 在) |
| 删除 | 在) |
| 搜索 | 在) |
链表的空间复杂度是 O(n)。
那么,链表的介绍就到此为止了。 希望这篇文章能给您带来帮助和信息。
按位序插入结点
List_Insert 函数用于在单链表的指定位置插入一个新节点。
检查插入位置 i 是否有效。有效位置是从 1 到链表长度加 1(即允许从头结点后面到链表尾部的位置插入)。
使用一个指针 p 从头结点开始遍历链表,直到找到第 i-1 个节点(即插入位置的前驱节点)。
将新节点的 next 指针指向原链表中 p 节点的下一个节点。
将 p 节点的 next 指针指向新节点,完成插入操作。
正在载入交互式动画窗口请稍等
2.2 单链表 可视化交互式动画版
在这篇文章中,我们将看到链表的介绍。
链表是一种线性数据结构,包含一系列相连的节点。 链表可以定义为随机存储在内存中的节点。 链表中的节点包含两部分,第一部分是数据部分,第二部分是地址部分。 列表的最后一个节点包含一个指向空值的指针。 链表是继数组之后第二常用的数据结构。 在链表中,每个链接都包含到另一个链接的连接。
链表的表示
链表可以表示为节点的连接,其中每个节点都指向链表的下一个节点。 链表的表示如下所示 -
到目前为止,我们一直使用数组数据结构来组织要单独存储在内存中的元素组。 然而,数组有几个优点和缺点,必须了解这些优点和缺点才能决定在整个程序中使用的数据结构。
现在,问题来了,为什么我们应该使用链表而不是数组?
为什么使用链表而不是数组?
链表是一种克服数组局限性的数据结构。 让我们首先看看数组的一些限制 -
- 在程序中使用数组之前必须事先知道数组的大小。
- 增加数组的大小是一个耗时的过程。 在运行时扩展数组的大小几乎是不可能的。
- 数组中的所有元素都需要连续存储在内存中。 在数组中插入一个元素需要移动其所有前驱元素。
链接列表很有用,因为 -
- 它动态分配内存。 链表的所有节点在内存中都是不连续存储的,并通过指针链接在一起。
- 在链表中,大小不再是问题,因为我们不需要在声明时定义其大小。 列表根据程序的需求而增长,并受到可用内存空间的限制。
如何声明一个链表?
数组的声明很简单,因为它是单一类型,而链表的声明比数组更典型一些。 链表包含两部分,两部分的类型不同,一是简单变量,二是指针变量。 我们可以使用用户定义的数据类型结构来声明链表 。
链表的声明如下 -
- 结构节点
- {
- 整数数据;
- 结构节点*下一个;
- }
在上面的声明中,我们定义了一个名为 node的 结构体,它包含两个变量,一个是整数类型的 数据 ,另一个是 next ,它是一个指针,包含下一个节点的地址。
现在,让我们转向链表的类型。
链表的类型
链表分为以下几种类型 -
- 单链表 - 单链表可以定义为有序元素集的集合。 单链表中的节点由两部分组成:数据部分和链接部分。 节点的数据部分存储该节点要表示的实际信息,而节点的链接部分存储其直接后继的地址。
- 双向链表 - 双向链表是一种复杂类型的链表,其中节点包含指向序列中前一个节点和下一个节点的指针。 因此,在双向链表中,一个节点由三部分组成:节点数据、指向序列中下一个节点的指针(next指针)、指向前一个节点的指针(previous指针)。
- 循环单链表 - 在循环单链表中,列表的最后一个节点包含指向列表的第一个节点的指针。 我们可以有循环单链表,也可以有循环双链表。
- 循环双向链表 - 循环双向链表是一种更复杂的数据结构类型,其中节点包含指向其前一个节点以及下一个节点的指针。 循环双向链表的任何节点中都不包含 NULL。 列表的最后一个节点包含列表的第一个节点的地址。 列表的第一个节点还包含其前一个指针中最后一个节点的地址。
现在,让我们看看使用链接列表的好处和局限性。
链表的优点
使用链表的优点如下:
- 动态数据结构—— 链表的大小可能根据需求而变化。 链表没有固定的大小。
- 插入和删除 - 与数组不同,链表中的插入和删除更容易。 数组元素存储在连续位置,而链表中的元素存储在随机位置。 要在数组中插入或删除元素,我们必须移动元素以创建空间。 而在链表中,我们不需要移位,只需更新节点指针的地址即可。
- 内存高效 - 链表的大小可以根据需要增长或缩小,因此链表中的内存消耗是高效的。
- 实现 - 我们可以使用链表来实现堆栈和队列。
链表的缺点
使用链表的限制如下:
- 内存使用 - 在链表中,节点比数组占用更多内存。 链表的每个节点占用两种类型的变量,一种是简单变量,另一种是指针变量。
- 遍历 - 在链表中遍历并不容易。 如果我们必须访问链表中的一个元素,我们不能随机访问它,而如果是数组,我们可以通过索引随机访问它。 例如,如果我们要访问第3个节点,那么我们需要遍历它之前的所有节点。 因此,访问特定节点所需的时间很大。
- 反向遍历 - 在链表中回溯或反向遍历是很困难的。 在双向链表中,它更容易,但需要更多内存来存储后向指针。
链表的应用
链表的应用如下:
- 借助链表,可以表示多项式,也可以对多项式进行运算。
- 可以使用链表来表示稀疏矩阵。
- 诸如学生详细信息、员工详细信息或产品详细信息之类的各种操作都可以使用链表来实现,因为链表使用可以容纳不同数据类型的结构数据类型。
- 使用链表,我们可以实现栈、队列、树等各种数据结构。
- 图是边和顶点的集合,图可以表示为邻接矩阵和邻接表。 如果我们想将图表示为邻接矩阵,那么可以将其实现为数组。 如果我们想将图表示为邻接表,那么可以将其实现为链表。
- 链表可以用来实现动态内存分配。 动态内存分配是在运行时完成的内存分配。
对链表执行的操作
列表支持的基本操作如下:
- 插入 - 执行此操作以将元素添加到列表中。
- 删除 - 执行从列表中删除操作。
- 显示 - 执行以显示列表的元素。
- 搜索 - 使用给定的键从列表中搜索元素。
链表的复杂性
现在,让我们看看链表的搜索、插入和删除操作的时间和空间复杂度。
1. 时间复杂度
| 运营 | 平均案例时间复杂度 | 最坏情况时间复杂度 |
|---|---|---|
| 插入 | 复杂度(1) | 复杂度(1) |
| 删除 | 复杂度(1) | 复杂度(1) |
| 搜索 | 在) | 在) |
其中“n”是给定树中的节点数。
2. 空间复杂度
| 运营 | 空间复杂度 |
|---|---|
| 插入 | 在) |
| 删除 | 在) |
| 搜索 | 在) |
链表的空间复杂度是 O(n)。
那么,链表的介绍就到此为止了。 希望这篇文章能给您带来帮助和信息。
按位序删除结点
List_Del 函数用于在单链表中删除指定位置的节点。
检查删除位置 i 是否有效。有效位置是从 1 到链表长度。
使用一个指针 p 从头结点开始遍历链表,直到找到第 i-1 个节点(即删除位置的前驱节点)。
使用指针 q 指向待删除节点。
将前驱节点 p 的 next 指针指向待删除节点 q 的下一个节点,跳过待删除节点。
删除操作成功后释放删除结点 q 的内存。
正在载入交互式动画窗口请稍等
2.2 单链表 可视化交互式动画版
在这篇文章中,我们将看到链表的介绍。
链表是一种线性数据结构,包含一系列相连的节点。 链表可以定义为随机存储在内存中的节点。 链表中的节点包含两部分,第一部分是数据部分,第二部分是地址部分。 列表的最后一个节点包含一个指向空值的指针。 链表是继数组之后第二常用的数据结构。 在链表中,每个链接都包含到另一个链接的连接。
链表的表示
链表可以表示为节点的连接,其中每个节点都指向链表的下一个节点。 链表的表示如下所示 -
到目前为止,我们一直使用数组数据结构来组织要单独存储在内存中的元素组。 然而,数组有几个优点和缺点,必须了解这些优点和缺点才能决定在整个程序中使用的数据结构。
现在,问题来了,为什么我们应该使用链表而不是数组?
为什么使用链表而不是数组?
链表是一种克服数组局限性的数据结构。 让我们首先看看数组的一些限制 -
- 在程序中使用数组之前必须事先知道数组的大小。
- 增加数组的大小是一个耗时的过程。 在运行时扩展数组的大小几乎是不可能的。
- 数组中的所有元素都需要连续存储在内存中。 在数组中插入一个元素需要移动其所有前驱元素。
链接列表很有用,因为 -
- 它动态分配内存。 链表的所有节点在内存中都是不连续存储的,并通过指针链接在一起。
- 在链表中,大小不再是问题,因为我们不需要在声明时定义其大小。 列表根据程序的需求而增长,并受到可用内存空间的限制。
如何声明一个链表?
数组的声明很简单,因为它是单一类型,而链表的声明比数组更典型一些。 链表包含两部分,两部分的类型不同,一是简单变量,二是指针变量。 我们可以使用用户定义的数据类型结构来声明链表 。
链表的声明如下 -
- 结构节点
- {
- 整数数据;
- 结构节点*下一个;
- }
在上面的声明中,我们定义了一个名为 node的 结构体,它包含两个变量,一个是整数类型的 数据 ,另一个是 next ,它是一个指针,包含下一个节点的地址。
现在,让我们转向链表的类型。
链表的类型
链表分为以下几种类型 -
- 单链表 - 单链表可以定义为有序元素集的集合。 单链表中的节点由两部分组成:数据部分和链接部分。 节点的数据部分存储该节点要表示的实际信息,而节点的链接部分存储其直接后继的地址。
- 双向链表 - 双向链表是一种复杂类型的链表,其中节点包含指向序列中前一个节点和下一个节点的指针。 因此,在双向链表中,一个节点由三部分组成:节点数据、指向序列中下一个节点的指针(next指针)、指向前一个节点的指针(previous指针)。
- 循环单链表 - 在循环单链表中,列表的最后一个节点包含指向列表的第一个节点的指针。 我们可以有循环单链表,也可以有循环双链表。
- 循环双向链表 - 循环双向链表是一种更复杂的数据结构类型,其中节点包含指向其前一个节点以及下一个节点的指针。 循环双向链表的任何节点中都不包含 NULL。 列表的最后一个节点包含列表的第一个节点的地址。 列表的第一个节点还包含其前一个指针中最后一个节点的地址。
现在,让我们看看使用链接列表的好处和局限性。
链表的优点
使用链表的优点如下:
- 动态数据结构—— 链表的大小可能根据需求而变化。 链表没有固定的大小。
- 插入和删除 - 与数组不同,链表中的插入和删除更容易。 数组元素存储在连续位置,而链表中的元素存储在随机位置。 要在数组中插入或删除元素,我们必须移动元素以创建空间。 而在链表中,我们不需要移位,只需更新节点指针的地址即可。
- 内存高效 - 链表的大小可以根据需要增长或缩小,因此链表中的内存消耗是高效的。
- 实现 - 我们可以使用链表来实现堆栈和队列。
链表的缺点
使用链表的限制如下:
- 内存使用 - 在链表中,节点比数组占用更多内存。 链表的每个节点占用两种类型的变量,一种是简单变量,另一种是指针变量。
- 遍历 - 在链表中遍历并不容易。 如果我们必须访问链表中的一个元素,我们不能随机访问它,而如果是数组,我们可以通过索引随机访问它。 例如,如果我们要访问第3个节点,那么我们需要遍历它之前的所有节点。 因此,访问特定节点所需的时间很大。
- 反向遍历 - 在链表中回溯或反向遍历是很困难的。 在双向链表中,它更容易,但需要更多内存来存储后向指针。
链表的应用
链表的应用如下:
- 借助链表,可以表示多项式,也可以对多项式进行运算。
- 可以使用链表来表示稀疏矩阵。
- 诸如学生详细信息、员工详细信息或产品详细信息之类的各种操作都可以使用链表来实现,因为链表使用可以容纳不同数据类型的结构数据类型。
- 使用链表,我们可以实现栈、队列、树等各种数据结构。
- 图是边和顶点的集合,图可以表示为邻接矩阵和邻接表。 如果我们想将图表示为邻接矩阵,那么可以将其实现为数组。 如果我们想将图表示为邻接表,那么可以将其实现为链表。
- 链表可以用来实现动态内存分配。 动态内存分配是在运行时完成的内存分配。
对链表执行的操作
列表支持的基本操作如下:
- 插入 - 执行此操作以将元素添加到列表中。
- 删除 - 执行从列表中删除操作。
- 显示 - 执行以显示列表的元素。
- 搜索 - 使用给定的键从列表中搜索元素。
链表的复杂性
现在,让我们看看链表的搜索、插入和删除操作的时间和空间复杂度。
1. 时间复杂度
| 运营 | 平均案例时间复杂度 | 最坏情况时间复杂度 |
|---|---|---|
| 插入 | 复杂度(1) | 复杂度(1) |
| 删除 | 复杂度(1) | 复杂度(1) |
| 搜索 | 在) | 在) |
其中“n”是给定树中的节点数。
2. 空间复杂度
| 运营 | 空间复杂度 |
|---|---|
| 插入 | 在) |
| 删除 | 在) |
| 搜索 | 在) |
链表的空间复杂度是 O(n)。
那么,链表的介绍就到此为止了。 希望这篇文章能给您带来帮助和信息。