 图码
图码2.1 顺序表
💡 让我们以一个现实世界的例子来描述计算机中的数组。
想象你在一个图书馆,这个图书馆里有很多书架,每个书架上都有一排排的书。每本书都有一个特定的位置,你可以通过书架的编号和书的位置找到它。
在计算机中,数组就像这个图书馆中的书架一样。它是一个存储相同类型数据元素的数据结构。每个数据元素都有一个唯一的索引或位置,通过这个索引,你可以访问或修改特定位置的数据元素。
在计算机内存中,数组的元素是依次存储的,就像书架上的书一样。这样,计算机可以通过简单的数学运算来计算出元素的内存地址,从而快速访问数组中的任何元素。
数组是一种有效存储和访问大量相似数据的方式,就像图书馆中的书架一样可以帮助你组织和查找大量书籍。
数组是一种线性数据结构,使用数组存放的数据不仅在逻辑上会排成一条线,在物理上也是连续存储。存储的这些数据元素具有相同的数据类型。
数组中的元素存储在连续的内存位置中,并由一个索引(也称为下标)引用。下标是一个用于标识数组中的元素位置的序号。
2.1.1 数组的声明
我们知道在使用变量之前要先进行声明,同样的我们在使用数组的时候也要提前进行声明。数组的声明是这样的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cnElemType:是我们要存放的数组元素的类型,类型可以是int, float,,double, char,或者其他可以使用的数据类型;
name:是用来表示数组的,称为数组名;
size:当前数组可以存放的最大数量。
例如,int 类型是我们最常用的数据类型。
我们可以使用以下来定义一个大小为10,数组名为array的数组。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn❗ 注意:
在本文后续中提到的所有
索引或下标 都是从 0 开始计数。
位序或第几个 都是从 1 开始计数。
在C 或者 C++ 中,数组索引从零开始。
第一个元素存储在array[0]中,第二个元素存储在array[1]中,以此类推。
因此,最后一个元素,即第6个元素,被存储在array[5]中。
在内存中,数组将如图所示进行存储。注意,方括号内写的0、1、2、3、4、5是下标。
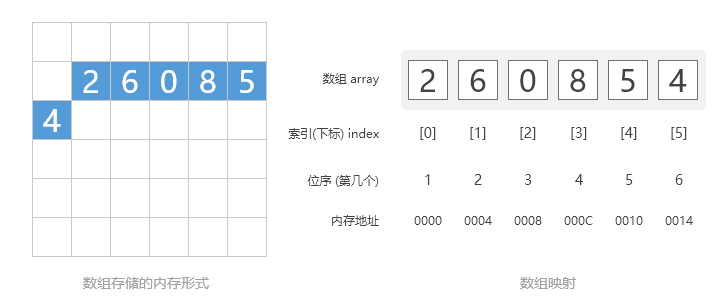
数组及内存结构
1 内存地址的计算
一个int类型的大小在内存中为4bytes。由于数组将其所有数据元素存储在连续的存储器位置中, 因此只需要知道数组首地址,即数组中第一个元素的地址就可以计算出该数组中其他元素的内存地址。
$$公式为:array[index] = base\_address + data\_type\_size \times index$$
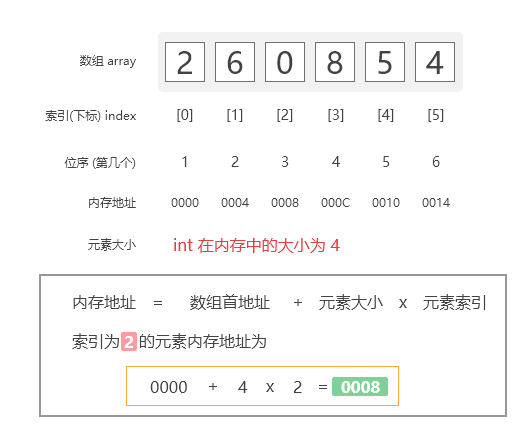
数组内存映射计算
由于数组元素是连续存储在内存的中的,所以我们可以很方便的访问任意一个元素。
就像你在图书馆的书架上查找一本特定的书时,如果你知道它的编号或位置,你可以直接走到该位置,而不必按顺序检查每本书。
在数组中访问元素是非常高效的,可以在$O(1)$时间内随机访问数组中的任意一个元素。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn在实际编码过程中,我们无需手动计算内存地址,因为每个元素占用大小相同的内存空间,数组元素的起始位置对于计算机也是已知的。 当我们在使用数组的下标来访问元素时,计算机可以通过上述的内存地址计算方法进行计算。
2 修改数组元素
需求:我们将index = 2即第 3 个元素的值修改为3。
操作步骤:
先找到$array[2]$的内存地址,使用上述公式:
$$\begin{split} array[2] &= base\_address + index \times data\_type\_size \\ \Rightarrow array[2] &= 0000 + 2 \times 4\\ \Rightarrow array[2] &= 0008 \end{split}$$
注意上面是计算内存地址,不是赋值
将内存地址为0xFFFF0008的值修改为3。
代码实现比较简单,计算机已自动帮助我们计算内存地址,我们只需提供对应的索引(index)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn整个操作的时间复杂度为$O(1)$。
2.1.2 顺序表的介绍
💡 提示:
数组是一种数据结构,用于存储相同类型的元素的集合。
数组是一种顺序存储结构,元素在内存中按照一定的顺序依次存储。
那么数组和线性表的关系是什么呢?
线性表是一种数据结构,其中元素排列成一条线一样的顺序。
这种结构没有跳跃或分叉,每个元素都有且仅有一个前驱和一个后继。
线性表包括顺序表(数组实现)和链表等。
数组是一种实现线性表的方式之一。线性表可以通过数组来实现,也可以通过链表等其他结构来实现。
因此,数组是线性表的一种实现方式,而线性表是一个更为抽象的概念,包括了多种实现方式,数组是其中之一。
通过数组实现的线性表称为顺序表。
1 顺序表的定义
线性表的顺序存储类型结构如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn定义了一个结构体SqList,包含两个成员变量:data和length。
data 是一个静态数组,用于存储顺序表的元素,数组最多可以存储MAX_SIZE个元素;
length 用于记录顺序表的当前长度,即存储了多少个元素。
2 顺序表的初始化
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ElemType name[size];
ElemType name[size];
// 例如
int array[6] = {2, 6, 0, 8, 5, 4};
void access () {
int array[6] = {2, 6, 0, 8, 5, 4};
printf("%d", array[0]); // 访问第一个元素【2】
printf("%d", array[4]); // 访问第 5 个元素【5】
printf("%d", array[5]); // 访问最后一个【4】
}
void change () {
int array[6] = {2, 6, 0, 8, 5, 4};
array[2] = 3;
}
// 数据类型
typedef struct {
ElemType data[MAX_SIZE]; // 用静态的
int length; // 顺序表的当前长度
} SqList; // 顺序表的类型定义
// 初始化顺序表
void InitList (SqList &L) {
L.length = 0; // 顺序表初始长度为 0
// 完整代码:https://totuma.cn这个函数的作用是将传入的顺序表 L初始化为一个空表,长度为0。
在实际使用中,初始化是为了确保顺序表处于一个可控的状态,以便进行后续的插入、删除等操作。
2 在顺序表中插入元素
在顺序表中插入元素分为以下几种情况:
情况一:顺序表未满:插入在末尾
这种情况比较简单,我们只需要在当前最后一个元素的位置+1处直接赋值
例如:下面可视化窗口中的顺序表被声明为最大容量为10个元素,目前它存储了8个元素
步骤:
在末尾插入的位置为:9下标为:8 插入值5。
继续在末尾位置插入值:10
顺序表未满:插入末尾 | 可视化完整可视化
情况二:顺序表已满:不能再插入元素
上面可视化动画在插入了两个元素以后,顺序表总共有10个元素,那么我们将不能再向它添加元素,这种情况我们是不能进行插入的。
情况三:顺序表未满:插入在中间
如果想要在顺序表中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,给要插入的元素腾出位置,之后再把元素赋值给该索引。
步骤:
当前顺序表中已有8个元素,我们在下标为5位序为6处插入值10
注意代码中 i 为位序,不是下标
数组未满:插入在中间 | 可视化完整可视化
时间复杂度:
最好情况:如果插入操作发生在顺序表的末尾,并且顺序表有足够的空间,那么插入操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接在末尾添加元素不需要移动其他元素。
最坏情况:如果插入操作发生在顺序表的开头,需要将所有元素向后移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况: 平均情况下,需要移动插入位置后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
4 删除顺序表中的元素
在一个顺序表中,如果我们要删除的元素位置在末尾,那么就非常简单。 我们只需要在当前存放元素的长度 -1 (L.length)。
但是如果在其他位置进行删除我们要如何操作呢?
如果想要从顺序表中间位置删除一个元素,则需要将该元素之后的所有元素都向前移动一位,覆盖掉待删除的位置,同时保证顺序表的顺序结构。
步骤:
下面可视化面板中给出了最大容量为10的顺序表。
此时的顺序表内元素为{ 2, 6, 0, 8, 5, 4, 9, 8 },我们把下标为:3,位序为:4的元素删除掉。
❗ 注意:
删除元素完成后,原先末尾的元素变得无意义了,所以我们无须特意去修改它。
删除顺序表元素 | 可视化完整可视化
时间复杂度:
最好情况:如果要删除的元素在顺序表的末尾,那么删除操作的时间复杂度为$O(1)$,即常数时间复杂度。这是因为直接删除末尾元素只需要将顺序表的长度减一即可,不需要移动其他元素。
最差情况:如果要删除的元素在顺序表的开头,或者在中间,需要将被删除元素后面的所有元素向前移动一个位置。在最坏情况下,这个移动过程需要线性地遍历和移动$n$个元素,其中$n$是顺序表中的元素个数。因此,最坏情况下的时间复杂度为$O(n)$。
平均情况:平均情况下,需要移动被删除元素后面一半的元素,因此平均时间复杂度为$O(\frac n 2)$,即$O(n)$。在大$O$表示法中,通常会忽略常数因子,因此平均时间复杂度仍然是$O(n)$。
5 查找顺序表的值-遍历
在顺序表中查找指定元素需要遍历顺序表,每轮判断顺序表值是否匹配,若匹配则通过e变量进行返回其位序。
查找顺序表中的值 | 可视化完整可视化
2.1 Подробное объяснение последовательного списка - Учебник по линейным спискам Визуализируйте свой код с помощью анимации

Линейные структуры данных: подробное руководство по последовательным спискам (Sequential List)
В мире программирования и алгоритмов структуры данных являются фундаментом, на котором строятся эффективные программы. Одной из самых базовых и важных структур является линейный список, а его простейшая реализация — последовательный список (или динамический массив). Данная статья предназначена для учащихся, изучающих структуры данных и алгоритмы, и поможет разобраться в принципах работы, особенностях и областях применения последовательных списков.
Что такое линейный список?
Линейный список — это упорядоченная коллекция элементов, где каждый элемент имеет свой порядковый номер (индекс). Представьте себе очередь в магазине: у каждого человека есть своя позиция, и вы можете обратиться к человеку, стоящему на определённом месте. В линейном списке элементы располагаются последовательно друг за другом, и каждый элемент (кроме первого и последнего) имеет ровно одного предыдущего и одного следующего элемента.
Последовательный список (Sequential List): определение и базовая структура
Последовательный список — это способ реализации линейного списка, при котором элементы хранятся в памяти компьютера последовательно, друг за другом. В большинстве языков программирования эта структура известна как "массив" (array) или "динамический массив" (например, ArrayList в Java, list в Python, vector в C++).
Ключевая особенность последоваельного списка: элементы располагаются в непрерывной области памяти. Если вы знаете адрес первого элемента и размер каждого элемента, вы можете мгновенно вычислить адрес любого элемента по его индексу. Это обеспечивает очень быстрый доступ к данным.
Основные характеристики последовательного списка
Для полного понимания этой структуры данных необходимо разобрать её ключевые характеристики и принципы работы:
1. Физическая и логическая последовательность совпадают. В последовательном списке порядок элементов в памяти совпадает с их логическим порядком. Это означает, что если у вас есть список [A, B, C], то в памяти элемент A находится непосредствено перед элементом B, а B — перед C.
2. Доступ по индексу (прямой доступ). Это главное преимущество последовательного списка. Операция получения элемента по индексу выполняется за константное время O(1). Вам не нужно просматривать весь список, чтобы найти элемент с индексом 5 — вы просто вычисляете его адрес.
3. Фиксированный или динамический размер. Существует две разновидности последовательных списков: статические массивы (фиксированный размер) и динамические массивы (автоматически расширяются при необходимости). Динамические массивы более гибкие, но требуют дополнительных операций при перераспределении памяти.
4. Последовательное хранение. Все элементы хранятся в одной непрерывной области памяти. Это обеспечивает хорошую кэш-производительность, так как процессор может загружать в кэш целые блоки данных.
Основные операции с последовательным списком
Рассмотрим основные операции, которые можно выполнять с последовательным списком, и их временную сложность:
1. Доступ к элементу по индексу (get/set). Время выполнения: O(1). Вы можете мгновенно получить или изменить элемент, зная его индекс. Например, получить третий элемент списка.
2. Вставка элемента. Время выполнения: O(n) в худшем случае. Если вы вставляете элемент в начало или середину списка, все последующие элементы необходимо сдвинуть на одну позицию вправо. Вставка в конец списка (для динамического массива) обычно выполняется за O(1), но может потребовать O(n) при расширении массива.
3. Удаление элемента. Время выполнения: O(n) в худшем случае. При удалении элемента из начала или середины списка все последующие элементы сдвигаются влево. Удаление последнего элемента выполняется за O(1).
4. Поиск элемента. Время выполнения: O(n) — линейный поиск. Если список не отсортирован, вам придётся просмотреть все элементы, чтобы найти нужный. Для отсортированного списка можно использовать бинарный поиск (O(log n)), но это требует дополнительных условий.
5. Обход списка (проход по всем элементам). Время выполнения: O(n). Вы можете последовательно перебрать все элементы от первого до последнего.
Преимущества последовательного списка
Последовательные списки имеют ряд неоспоримых преимуществ, которые делают их незаменимыми во многих ситуациях:
1. Быстрый доступ к данным. Благодаря прямому доступу по индексу, последовательные списки идеально подходят для ситуаций, где требуется часто обращаться к элементам по их позиции.
2. Эффективное использование памяти. В отличие от связных списков, последовательные списки не хранят дополнительные указатели на следующий элемент, что экономит память.
3. Кэш-локальность. Благодаря последовательному расположению в памяти, последовательные списки эффективно используют кэш процессора. При обходе списка процессор загружает в кэш блоки данных, что ускоряет доступ к последующим элементам.
4. Простота реализации. Реализовать последовательный список гораздо проще, чем связный список или другие сложные структуры данных.
Недостатки последовательного списка
Как и любая структура данных, последовательный список имеет свои слабые стороны:
1. Медленные вставка и удаление в середине списка. Если вам нужно часто вставлять или удалять элементы в произвольных позициях, последовательный список может быть не лучшим выбором из-за необходимости сдвигать элементы.
2. Проблема расширения динамического массива. Когда динамический массив заполнен, необходимо выделить новый блок памяти большего размера и скопировать все элементы. Это дорогостоящая операция (O(n)), хотя она происходит редко.
3. Фиксированный размер статического массива. Если вы используете статический массив, его размер задаётся при создании и не может быть изменён. Это может привести к нехватке памяти или её неэффективному использованию.
Сценарии применения последовательного списка
Последовательные списки широко используются в реальных приложениях и алгоритмах. Вот наиболее типичные сценарии:
1. Хранение и обработка данных с известным размером. Например, хранение оценок студентов, координат точек на плоскости, пикселей изображения.
2. Реализация стеков и очередей. Последовательные списки отлично подходят для реализации стека (LIFO), где все операции выполняются на одном конце. Для очереди (FIFO) последовательный список менее эффективен, но может использоваться с кольцевым буфером.
3. Таблицы поиска. Если у вас есть данные, к которым нужно часто обращаться по индексу (например, таблица соответствия кодов символов), последовательный список — идеальный выбор.
4. Буферы данных. В системах обработки данных часто используются буферы фиксированного размера, которые реализуются как последовательные списки.
5. Матрицы и многомерные массивы. Математические матрицы, изображения, таблицы Excel — всё это реализуется с помощью последовательных списков (часто вложенных).
6. Сортировка данных. Многие алгоритмы сортировки (быстрая сортировка, сортировка слиянием) работают именно с последовательными списками, так как им требуется быстрый доступ к элементам по индексу.
Реализация последовательного списка на примере
Рассмотрим, как можно реализовать простой динамический последовательный список. В реальном коде это может выглядеть следующим образом (псевдокод):
Создание списка: выделяем начальную память для хранения элементов (например, на 10 элементов). Запоминаем текущий размер (количество реально хранящихся элементов) и ёмкость (максимальное количество элементов, которое можно хранить без расширения).
Добавление элемента в конец: если текущий размер меньше ёмкости, просто помещаем элемент в следующую свободную ячейку и увеличиваем размер. Если размер равен ёмкости, создаём новый массив большего размера (обычно в 1.5-2 раза), копируем все элементы из старого массива, добавляем новый элемент и освобождаем старую память.
Вставка элемента по индексу: проверяем, что индекс корректен. Сдвигаем все элементы от указанного индекса до конца на одну позицию вправо. Помещаем новый элемент на освободившееся место. Увеличиваем размер.
Удаление элемента по индексу: проверяем, что индекс корректен. Сдвигаем все элементы после удаляемого на одну позицию влево. Уменьшаем размер.
Сравнение с другими структурами данных
Чтобы лучше понять место последовательного списка в мире структур данных, сравним его с основными альтернативами:
Последовательный список vs Связный список: Связный список (linked list) хранит элементы в произвольных местах памяти, связывая их указателями. Он позволяет быстро вставлять и удалять элементы в середине (O(1) после нахождения позиции), но медленнее при доступе по индексу (O(n)). Последовательный список, наоборот, быстр при доступе и медлен при вставке/удалении.
Последовательный список vs Хеш-таблица: Хеш-таблица обеспечивает быстрый поиск по ключу (в среднем O(1)), но не поддерживает упорядоченность элементов. Последовательный список сохраняет порядок элементов и позволяет быстро обращаться к ним по индексу.
Последовательный список vs Дерево: Деревья (например, бинарное дерево поиска) обеспечивают быстрый поиск, вставку и удаление (O(log n)), но сложнее в реализации и требуют больше памяти. Последовательный список проще и эффективнее для последовательного доступа.
Визуализация последовательного списка: как это помогает в обучении
Изучение структур данных часто бывает сложным из-за абстрактности концепций. Именно здесь на помощь приходят инструменты визуализации. Платформа визуализации структур данных и алгоритмов позволяет увидеть, как работает последовательный список "вживую".
Как работает визуализация последовательного списка: На экране отображается последовательность ячеек памяти, каждая из которых содержит значение элемента. При выполнении операций (вставка, удаление, поиск) вы можете наблюдать, как элементы сдвигаются, как выделяется новая память при расширении массива, и как изменяется состояние списка на каждом шаге.
Преимущества использования платформы визуализации:
1. Наглядность. Вместо абстрактных описаний вы видите реальное поведение структуры данных. Это особенно полезно для понимания операций сдвига элементов при вставке и удалении.
2. Пошаговое выполнение. Вы можете выполнять операции пошагово, наблюдая за каждым изменением. Это помогает понять, как именно работает алгоритм и почему он имеет ту или иную временную сложность.
3. Интерактивность. Вы можете самостоятельно вставлять и удалять элементы, задавать различные сценарии и наблюдать за результатом. Это активное обучение гораздо эффективнее пассивного чтения.
4. Сравнение структур. Многие платформы позволяют одновременно визуализировать несколько структур данных, чтобы сравнить их поведение при одинаковых операциях.
5. Отладка алгоритмов. Если вы изучаете алгоритмы сортировки или поиска, визуализация поможет увидеть, как алгоритм взаимодействует со структурой данных.
Как использовать платформу визуализации для изучения последовательного списка
Для максимальной эффективности обучения рекомендуется следующий подход:
Шаг 1: Изучите теорию. Прочитайте данную статью или другую теоретическую информацию о последовательных списках. Поймите основные концепции и операции.
Шаг 2: Запустите визуализацию. Откройте платформу визуализации и выберите раздел "Линейные списки" или "Последовательный список".
Шаг 3: Выполните базовые операции. Начните с простых действий: добавьте несколько элементов в конец списка. Обратите внимание, как элементы заполняют ячейки памяти.
Шаг 4: Попробуйте вставку и удаление. Вставьте элемент в середину списка. Наблюдайте, как элементы сдвигаются вправо. Затем удалите элемент — увидите сдвиг влево.
Шаг 5: Экспериментируйте с граничными случаями. Попробуйте вставить элемент в начало списка, в конец, за пределами списка. Посмотрите, что происходит, когда динамический массив заполняется и требуется его расширение.
Шаг 6: Сравните с другими структурами. Откройте рядом визуализацию связного списка и выполните те же операции. Сравните, как по-разному ведут себя эти структуры.
Шаг 7: Решайте задачи. Многие платформы предлагают задачи и упражнения. Попробуйте реализовать алгоритм, используя последовательный список, и проверьте его работу на визуализации.
Почему важно изучать последовательные списки
Последовательный список — это не просто учебная структура данных. Это основа для понимания более сложных концепций:
1. Фундамент для других структур. Многие структуры данных (стеки, очереди, кучи) реализуются на основе последовательных списков. Понимание последовательного списка — первый шаг к изучению этих структур.
2. Основа для алгоритмов. Большинство алгоритмов сортировки, поиска и обработки данных работают с последовательными списками. Знание их свойств поможет вам выбирать правильные алгоритмы для решения задач.
3. Понимание компромиссов. Изучение последовательного списка учит вас мыслить в ерминах "время vs память", "скорость доступа vs скорость вставки". Это критичски важный навык для любого программиста.
4. Практическое применение. От баз данных до игровых движков, от веб-приложений до научных вычислений — последовательные списки используются повсеместно.
Типичные ошибки при работе с последовательными списками
Начинающие разработчики часто допускают следующие ошибки:
1. Игнорирование сложности вставки. Вставка в начало списка выполняется за O(n), но некоторые разработчики по привычке используют её, когда можно было бы использовать добавление в конец или другую структуру данных.
2. Неправильное управление памятью. В языках с ручным управлением памятью (C, C++) легко забыть освободить память после использования динамического массива.
3. Выход за границы массива. Попытка обратиться к элементу с индексом, выходящим за пределы списка, приводит к ошибкам или неопределённому поведению.
4. Неэффективное расширение. При реализации динамического массива важно выбирать правильный коэффициент роста (обычно 1.5-2). Слишком маленький коэффициент приведёт к частым расширениям, слишком большой — к неэффективному использованию памяти.
Заключение
Последовательный список — это фундаментальная структура данных, которую должен знать каждый программист. Она обеспечивает быстрый доступ к элементам по индексу, эффективно использует память и кэш процессора, но требует осторожности при вставке и удалении элементов в середине списка.
Изучение последовательного списка с помощью платформы визуализации значительно ускоряет понимание его работы. Вы можете наблюдать за каждым шагом операций, экспериментировать с различными сценариями и видеть, как внутреннее устройство структуры влияет на её поведение.
Помните, что выбор структуры данных — это всегда поиск компромисса. Последовательный список идеален для задач, где важна скорость доступа к данным и последовательный обход, но может быть не лучшим выбором, если требуется часто вставлять или удалять элементы в произвольных позициях.
Практикуйтесь, экспериментируйте с визуализацией и постепенно переходите к более сложным структурам данных. Успешного изучения алгоритмов и структур данных!
时间复杂度:
最好情况:要查找的元素恰好在顺序表的第一个位置,此时时间复杂度为$O(1)$,即常数时间复杂度。
最坏情况:要查找的元素可能在顺序表的最后一个位置,或者不在顺序表中。在这种情况下,时间复杂度为$O(n)$,其中$n$是顺序表中元素的个数。
平均情况:平均情况的时间复杂度通常是$O(\frac n 2)$,因为平均而言,我们可以认为要查找的元素在顺序表的中间位置。但是在大$O$表示法中,我们通常忽略常数因子,因此平均情况的时间复杂度仍然是$O(n)$。
2.1.3 顺序表数组实现的优点与缺点
1 优点
随机访问速度快:由于数组是一段连续的内存空间,通过索引可以直接访问数组中的任何元素,因此随机访问的时间复杂度为 $O(1)$。这使得数组在需要频繁随机访问元素的情况下非常高效。
节约空间:相对于后续学习的链表等动态数据结构,数组不需要额外的指针存储空间,因此在存储上相对紧凑,更节省空间。
缓存友好:由于数组的元素在内存中是连续存储的,这有利于CPU缓存的预取,因此对于大规模数据的遍历和访问,数组通常比链表更具性能优势。
2 缺点
固定大小:数组的大小是固定的,一旦创建后就不能动态改变。如果需要存储的元素个数超过数组的初始大小,就需要重新分配内存并复制数据,这可能导致性能开销。
插入和删除操作效率低:在数组中插入或删除元素时,需要移动其他元素,尤其是在插入或删除中间位置的情况下,时间复杂度为 $O(n)$。这使得数组在频繁插入和删除操作的场景下效率较低。
不适合存储变长数据:由于数组的大小是固定的,如果存储的元素大小变化较大,可能会导致浪费内存或无法满足需求。