 图码
图码1.1 什么是数据结构?
在计算机世界中,数据结构代表了计算机在内存中存储和组织数据的独特方法。通过不同的排列和组合方式,可以使用户高效且适当的方式访问和使用他们所需的数据。
数据结构的存在使用户能够方便地按需访问和操作他们的数据,有助于以高效而紧凑的方式组织和检索各种类型的数据。
对于接触过计算机基础知识的读者而言,对于下面这个公式应该不会陌生:
算法 + 数据结构 = 程序
提出这一公式并以此作为其一本专著书名Algorithms + Data Structures = Programs的瑞士计算机科学家Niklaus Wirth于1984年获得了图灵奖。
程序(Program)是由数据结构(Data Structure)和算法(Algorithm)组成,这意味着的程序的好和快是直接由程序所采用的数据结构和算法决定的。
❗️ 注意
本章节仅作介绍,涉及到的具体数据结构和算法会在后续章节中详细讲解。
数据结构分类
数据也可以被细分为以下两种类型:
线性结构
非线性结构
线性结构
数据元素按顺序或者线性排列
除了第一个元素和最后一个元素之外,剩余每个元素都有前一个和下一个相邻元素。
有两种技术可以在内存中表示这种线性结构。
数组:存储在连续内存位置的相同数据类型的项目的集合。
链表:通过使用指针或链接的概念来表示的所有元素之间的线性关系。
常见的线性结构例子有:
数组:存储在连续内存位置的元素的集合。
链表:节点的集合,每个节点包含一个元素和对下一个节点的引用。
堆栈:具有后进先出 (LIFO)顺序的元素集合。
队列:具有先进先出 (FIFO)顺序的元素集合。
非线性结构
该结构主要用于表示包含各种元素之间的层次关系的数据。
常见的非线性结构例子有:
图:顶点(节点)和表示顶点之间关系的边的集合。图用于建模和分析网络,例如社交网络或交通网络。
树:树的结构呈现出一个类似根和分支的形状,其中有一个根节点,从根节点出发,分成多个子节点,每个子节点可以又分为更多的子节点,依此类推
各种数据结构的简单介绍
数组(Arrays)
数组是相似数据元素的集合。这些数据元素具有相同的数据类型。
数组的元素存储在连续的内存位置中,并由索引(也称为下标)来指向数据。
在C语言中,数组声明使用以下格式:
- 1
- 2
- 3
ElemType name[size];
//例如
char array[10] = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'
// 完整代码:https://totuma.cn上面的语句声明了一个包含10个元素的数组标记。 在C中,数组索引从零开始。这意味着数组标记将总共包含10个元素。
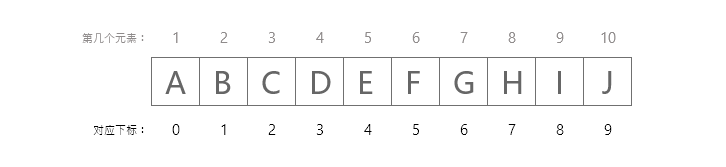
数组下标对应位序
第一个元素将存储在array[0]中,第二个元素将存储在array[1]中,等等。因此,最后一个元素,即第10个元素,将被存储在array[9]中。 在计算机中存储如下图所示。
当我们想要存储大量相同类型的数据时,通常会使用数组。当然,数组也有一些限制,比如:
数组的大小是固定的。
数据元素存储在连续的内存位置中,但是内存中剩余的大小可能不足以容纳当前数组。
元素的插入和删除会很麻烦。
链表(Linked Lists)
链表是一种非常灵活的动态数据结构,其中元素(称为节点)形成一个顺序列表。 与静态数组相比,我们不需要担心链表中将存储多少个元素。这个特性使我们能够编写需要较少维护的健壮程序。在链表中,每个节点都有data域和next指针域:
data域:存放该节点或与该节点对应的任何其他数据的值。
next指针域:指向列表中的下一个节点的指针或链接。
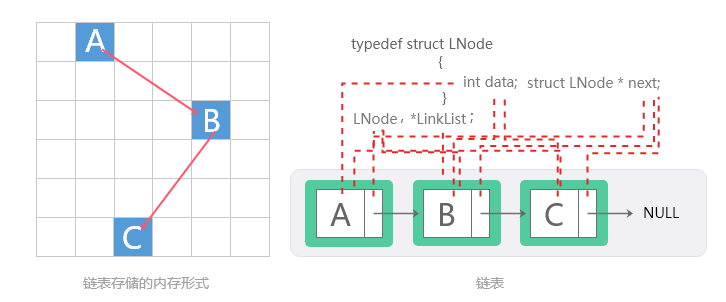
链表结构
列表中的最后一个节点包含一个NULL指针,表明它是当前列表的尾。由于节点的内存是在添加到列表中时动态分配的,因此可以添加到列表中的节点总数仅受可用内存量的限制。具体结构可见下图:
栈(Stacks)
栈是一种线性数据结构, 其中元素的插入和删除只在一端完成,这被称为栈顶。 栈被称为先入后出(LIFO)结构,因为添加到堆栈中的最后一个元素是从堆栈中删除的第一个元素。在计算机的内存中,堆栈可以使用数组或链表来实现。
下面可视化操作显示了一个栈的数组实现。每个栈都有一个与其关联的变量top,用于指向最上面的元素。这是将从中添加或删除元素的位置。
栈支持push 入栈和pop 出栈 操作,push 就是在从栈顶中压入一个元素,pop 就是在栈顶中弹出一个元素,即增和删。
💡 提示
点击下方的入栈、出栈按钮。可以明了的理解到什么是先入后出。
栈 | 可视化完整可视化
1.1 Что такое структура данных? - Учебник по структурам данных Визуализируйте свой код с помощью анимации

Линейные структуры данных: Список, Стек и Последовательная таблица
В мире программирования и алгоритмов понимание базовых структур данных — это фундамент, на котором строится всё остальное. Для русскоязычных студентов, изучающих数据结构 и алгоритмы (DSA), особенно важно освоить такие понятия, как линейный список, стек и последовательная таблица (или 顺序表 на русский манер — «последовательный список»). Эти структуры лежат в основе множества алгоритмов: от простых операций с данными до сложных систем управления памятью.
В этой статье мы подробно, простым и понятным языком, разберём принципы работы, характерные особенности и реальные сценарии применения каждой структуры. А также узнаем, как визуализация может превратить абстрактные концепции в наглядные и легко запоминающиеся образы. Если вы только начинаете свой путь в DSA или хотите систематизировать знания — этот материал для вас.
Что такое линейные структуры данных?
Линейные структуры данных — это такие структуры, в которых элементы располагаются последовательно, один за другим. Каждый элемент (кроме первого и последнего) имеет ровно одного «соседа» слева и одного справа. Это похоже на вагончики поезда: каждый вагон сцеплен с предыдущим и следующим. К линейным структурам относятся: массивы, списки, стеки, очереди, деки и другие.
Главное преимущество линейных структур — простота и предсказуемость. Мы всегда знаем, в каком порядке расположены данные, и можем легко перебирать их от начала до конца. Однако у разных линейных структур есть свои правила добавления, удаления и доступа к элементам. Именно эти правила определяют, какую структуру выбрать для конкретной задачи.
Последовательная таблица (顺序表) — основа основ
Принцип работы
Последовательная таблица (её также называют динамический массив или 顺序表 в китайской терминологии) — это структура, в которой элементы хранятся в памяти подряд, один за другим. Каждому элементу соответствует индекс (номер позиции). Благодаря этому мы можем мгновенно обратиться к любму элементу по его индексу — это называется произвольный доступ (random access).
Например, если у нас есть последовательная таблица из 5 чисел: [10, 20, 30, 40, 50], то элемент с индексом 2 (начиная с 0) — это число 30. Чтобы получить его, компьютеру не нужно просматривать все предыдущие элементы: он просто вычисляет адрес в памяти и берёт значение.
Характеристики и особенности
- Быстрый доступ по индексу: O(1) — константное время.
- Медленная вставка и удаление в середине: O(n) — нужно сдвигать все последующие элементы.
- Динамический размер: в языках программирования (например, Python list, Java ArrayList) таблица может автоматически расширяться при добавлении новых элементов.
- Кэш-дружественность: элементы расположены рядом в памяти, что ускоряет последовательный перебор.
Где применяется?
Последовательные таблицы используются везде, где нужен быстрый доступ к данным по индексу и не требуется часто вставлять/удалять элементы в середине. Примеры: хранение списка студентов в группе, таблица лидеров игры, буфер для считывания данных из файла, реализация других структур (например, кучи, стека).
Линейный список (List) — гибкость и динамика
Принцип работы
Линейный список (или просто список) — это последовательность элементов, где каждый элемент содержит ссылку на следующий (и, возможно, на предыдущий). В отличие от последовательной таблицы, элементы списка не обязаны располагаться в памяти подряд. Они могут быть разбросаны, а порядок задаётся указателями (ссылками).
Существует два основных вида: односвязный список (каждый элемент знает только о следующем) и двусвязный список (каждый элемент знает о следующем и предыдущем). В двусвязном списке можно легко перемещаться в обоих направлениях.
Характеристики и особенности
- Быстрая вставка и удаление в любом месте: O(1) при условии, что у нас уже есть ссылка на элемент (или мы вставляем в начало/конец).
- Медленный доступ по индексу: O(n) — приходится проходить по цепочке от начала до нужного элемента.
- Дополнительная память: каждый элемент хранит не тльо данные, но и указатели (1 или 2).
- Нет кэш-дружественности: элементы разбросаны по памяти, последовательный обход может быть медленнее, чем у массива.
Где применяется?
Списки идеальны, когда нужно часто вставлять или удалять элементы в середине последовательности. Например: реализация очередей и стеков (на основе списков), редакторы текста (список строк), управление памятью в операционных системах, графы (списки смежности).
Стек (Stack) — принцип LIFO
Принцип работы
Стек — это линейная структура данных, работающая по принципу «последний пришёл — первый вышел» (Last In, First Out, LIFO). Представьте стопку тарелок: вы кладёте новую тарелку сверху, и только её можете взять первой. То же самое со стеком: добавление (push) и удаление (pop) происходят только с одного конца — вершины стека.
Стек можно реализовать как на основе последовательной таблицы (массива), так и на основе списка. Главное — соблюдать правило LIFO.
Характеристики и особенности
- Операции push и pop: O(1) — очень быстрые.
- Доступ к произвольному элементу: как правило, не поддерживается (только к вершине).
- Простота и надёжность: стек легко реализовать и отлаживать.
- Ограниченный функционал: нельзя вставить элемент в середину или удалить не с вершины.
Где применяется?
Стек — незаменимая структура во многих алгоритмах и системах. Примеры: проверка правильности скобок в коде, обход дерева в глубину (DFS), обратная польская нотация (калькуляторы), отмена действий (undo) в редакторах, стек вызовов функций (call stack) в любом языке программирования.
Сравнение: когда что использовать?
Выбор между последовательной таблицей, списком и стеком зависит от задачи. Вот простая памятка:
- Нужен быстрый доступ по индексу и редко меняете содержимое? → Последовательная таблица.
- Часто вставляете/удаляете в середине, но не нужен произвольный доступ? → Линейный список.
- Нужно обрабатывать данные в порядке «последний пришёл — первый ушёл»? → Стек.
- Нужен быстрый доступ к первому/последнему элементу и втавка только с краёв? → Дек (deque), но это уже отдельная история.
На практике часто комбинируют структуры: например, стек реализуют на основе динамического массива (последовательной таблицы), чтобы получить быстрый доступ к вершине и автоматическое расширение.
Визуализация — ключ к пониманию
Многие студенты сталкиваются с трудностями, когда пытаются представить, как именно работают указатели в списке или как сдвигаются элементы в массиве. Именно здесь на помощь приходят платформы визуализации алгоритмов и структур данных. Они позволяют увидеть каждую операцию в динамике: как элемент «запрыгивает» в стек, как разрываются и соединяются ссылки в списке, как массив расширяется при добавлении нового элемента.
Наш Data Structure Visualization Platform создан специально для того, чтобы сделать обучение DSA наглядным и интерактивным. Вы не просто читаете теорию — вы наблюдаете, как структура живёт и меняется под вашими командами.
Функции и преимущества платформы
- Пошаговое выполнение: вы можете выполнять операции (push, pop, insert, delete) шаг за шагом и видеть, как меняется состояние структуры.
- Цветовая кодировка: новые элементы подсвечиваются одним цветом, удаляемые — другим, сдвигаемые — третьим. Это помогает не упустить детали.
- Поддержка нескольких структур: последовательная таблица, односвязный и двусвязный список, стек, очередь, дек и многие другие.
- Интерактивные элементы управления: кнопки «Добавит», «Удалить», «Найти», «Очистить» — вы сами решаете, что делать.
- Визуализация памяти: для последовательной таблицы показывается, как элементы лежат в памяти рядом; для списка — как указатели связывают разрозненные блоки.
- Подходит для любого уровня: от новичков, которые впервые видят слово «стек», до продвинутых пользователей, отлаживающих сложные алгоритмы.
Как использовать платформу для изучения линейных структур?
1. Выберите структуру: в меню выберите «Стек», «Список» или «Последовательная таблица».
2. Изучите базовые операции: начните с простых действий: добавьте 3-4 элемента, затем удалите один. Смотрите, как меняется визуальное представление.
3. Экпериментируйте: попробуйте вставить элемент в середину списка или в начало массива. Обратите внимание, сколько элементов пришлось сдвинуть.
4. Сравнивайте: выполните одну и ту же последовательность операций на разных структурах. Например, добавьте 5 элементов в стек и в список — почувствуйте разницу.
5. Проверяйте себя: после визуализации попробуйте предсказать, как изменится структура после следующей операции. Затем нажмите кнопку и проверьте.
Такой подход позволяет не просто запомнить, а глубоко понять механику работы каждой структуры. Визуализация устраняет абстракцию и превращает код в живой, осязаемый процесс.
Заключение
Линейные структуры данных — это первая серьёзная тема в изучении алгоритмов. Последовательная таблица даёт скорость доступа, список — гибкость вставки, а стек — дисциплину LIFO. Каждая из них имеет свои сильные стороны и ограничения. Умение выбирать правильную структуру под задачу — признак опытного программиста.
Но теория без практики остаётся просто текстом. Используйте визуализатор структур данных, чтобы увидеть, как работают эти механизмы. Наблюдайте, экспериментируйте, ошибайтесь и снова наблюдайте — именно так рождается настоящее понимание. Начните с простого: откройте визуализацию стека, добавьте несколько элементов, а затем извлеките их. Вы сразу почувствуете принцип LIFO. Затем переходите к спискам и массивам. Уверены, что после наглядного опыта вы уже никогда не запутаетесь в этих базовых, но таких важных структурах.
Помните: структуры данных — это инструменты. Чем лучше вы знаете свой инструмент, тем эффективнее решаете задачи. Удачи в изучении!
队列(Queues)
队列是一种先进先出(FIFO)的数据结构,其中首先插入的元素是第一个要取出的元素。 队列中的元素在队尾添加,然后在队头删除。 与栈一样,队列也可以通过使用数组或链表来实现。 每个队列都有队头和队尾,分别指向可以进行删除和插入的位置。
队列 | 可视化完整可视化
1.1 Что такое структура данных? - Учебник по структурам данных Визуализируйте свой код с помощью анимации
Очередь на основе последовательного списка: принципы, визуализация и применение
Что такое очередь и последовательный список?
Очередь (queue) — это одна из фундаментальных структур данных в информатике, работающая по принципу «первым пришёл — первым вышел» (FIFO, First In, First Out). Представьте обычную очередь в магазине: первый покупатель, который встал в очередь, обслуживается первым. Новые элементы всегда добавляются в конец (хвост) очереди, а извлекаются из начала (головы).
Последовательный список (sequential list) — это способ хранения данных в памяти компьютера, при котором элементы располагаются друг за другом в непрерывной области памяти. В языках программирования его часто реализуют с помощью массива (array). Для очереди на основе последовательного списка мы используем массив фиксированного или динамического размера, а также два указателя: front (голова) и rear (хвост), чтобы отслеживать начало и конец очереди.
В отличие от связного списка, где каждый элемент хранит ссылку на следующий, последовательный список обеспечивает прямой доступ к элементу по индексу за O(1), но вставка и удаление в середине могут потребовать сдвига элементов. Однако для очереди операции добавления и удаления выполняются только на концах, поэтому последовательная реализация очень эффективна.
Принцип работы очереди на последовательном списке
Основные операции очереди:
- enqueue (push) — добавление элемента в хвост очереди.
- dequeue (pop) — удаление элемента из головы очереди.
- front (peek) — просмотр головного элемента без удаления.
- isEmpty — проверка, пуста ли очередь.
- isFull — проверка, заполнена ли очередь (для статического массива).
В простейшей реализации на массиве мы используем индекс front для указания на первый элемент и индекс rear для указания на последний. При добавлении элемента мы увеличиваем rear и записываем значение в массив[rear]. При удалении — считываем массив[front] и увеличиваем front. Однако такая простая схема приводит к проблеме: после нескольких операций dequeue передняя часть массива становится пустой, но мы не можем её переиспользовать, и очередь кажется «полной», хотя в начале массива есть свободное место.
Решение — использование кольцевого буфера (circular buffer). В кольцевой очереди индексы front и rear «зацикливаются»: когда они достигают конца массива, они перескакивают в начало. Это позволяет эффективно использовать всю выделенную память. Обычно для различения пустой и полной очереди либо хранят размер (count), либо оставляют одну ячейку пустой.
Пример на псевдокоде (кольцевая очередь):
enqueue(item):
if (rear + 1) % capacity == front:
// очередь полна (если оставлена одна пустая ячейка)
return false
array[rear] = item
rear = (rear + 1) % capacity
count++
return true
dequeue():
if isEmpty():
return null
item = array[front]
front = (front + 1) % capacity
count--
return item
Такая реализация гарантирует, что все операции выполняются за O(1) — константное время, что очень важно для производительности.
Особенности и преимущества последовательной реализации очереди
Преимущества:
- Быстрый доступ: Элементы хранятся в непрерывном блоке памяти, что улучшает кэширование процессора и ускоряет операции.
- Простота реализации: Не требуется управлять указателями, как в связном списке. Код компактный и понятный.
- Эффективность: Все основные операции (enqueue, dequeue) выполняются за O(1) при использовании кольцевого буфера.
- Низкие накладные расходы: Не требуется дополнительная память для хранения ссылок (как в связном списке).
Недостатки:
- Фиксированный размер: Если используется статический массив, размер очереди ограничен. Динамический массив решает эту проблему, но требует периодического копирования элементов.
- Сложность с кольцевым буфером: Новичкам может быть непривычно думать о «зацикленных» индексах.
- Неэффективность при частом изменении размера: При динамическом расширении массива (например, удвоении) требуется копировать все элементы, что заимает O(n) времени.
Тем не менее, для большинства практических задач очередь на последовательном списке является оптимальным выбором благодаря балансу скорости и простоты.
Применение очереди в реальных задачах
Очередь — одна из самых востребованных структур данных. Вот ключевые области её применения:
- Обработка задач в порядке поступления: Планировщики процессов в операционных системах (FIFO scheduling), печать документов на принтере, обработка запросов на веб-сервере.
- Алгоритмы на графах: Поиск в ширину (BFS) использует очередь для обхода вершин. Это основа для поиска кратчайшего пути в невзвешенных графах.
- Буферизация данных: Потоковая передача видео, аудио, сетевое взаимодействие — данные временно хранятся в очереди, чтобы сгладить разницу в скорости отправителя и получателя.
- Системы реального времени: Очереди сообщений (message queues) в микросервисной архитектуре, например RabbitMQ, Kafka.
- Очереди задач: В многопоточном программировании пул потоков использует очередь для хранения ожидающих задач.
- Симуляция: Моделирование работы банка, магазина, call-центра — клиенты встают в очередь и обслуживаются.
Понимание очереди необходимо для изучения более сложных структур, таких как дек, приоритетная очередь, а также для освоения алгоритмов на графах и деревьях.
Визуализация очереди: как помогает платформа
Изучение структур данных «в голове» или по статичным картинкам часто затруднительно. Именно здесь на помощь приходит платформа визуализации алгоритмов и структур данных. Она позволяет наблюдать за работой очереди в динамике, шаг за шагом.
Основные возможности платформы для изучения очереди на последовательном списке:
- Пошаговое выполнение: Вы можете добавлять (enqueue) и удалять (dequeue) элементы, наблюдая, как меняются указатели front и rear, как заполняются ячейки массива. Каждый шаг сопровождается пояснениями.
- Визуализация кольцевого буфера: Наглядно видно, как индексы «перескакивают» в начало массива, что помогает понять концепцию цикличности.
- Подсветка операций: Текущий элемент подсвечивается, анимация показывает, как данные перемещаются или удаляются.
- Настройка размера: Можно изменить размер массива, чтобы увидеть разницу между статической и динамической очередью.
- Сравнение с другими реализациями: Платформа часто позволяет переключиться между последовательным списком и связным списком, чтобы сравнить их поведение и производительность.
- Встроенный редактор кода: Вы можете писать свой код на Python, Java, C++ и сразу видеть, как он выполняется на визуализированной структуре.
Благодаря визуализации абстрактные понятия становятся осязаемыми. Вы не просто запоминаете, что «очередь работает по FIFO», а видите, как именно элементы движутся, как меняются индексы, как возникает переполнение или опустошение.
Как использовать платформу для эффективного обучения
Чтобы получить максимум от платформы визуализации, следуйте этим рекомендациям:
- Начните с теории: Прочитайте про очередь и последовательный список, как в этой статье. Затем переходите к визуализации.
- Экспериментируйте вручную: Выполните серию операций enqueue и dequeue в произвольном порядке. Обратите внимание, как меняются front и rear. Попробуйте довести очередь до полного заполнения и опустошения.
- Изучите крайние случаи: Что происходит при попытке удалить элемент из пустой очереди? Как ведёт себя кольцевой буфер, когда rear догоняет front? Платформа покажет ошибки и подскажет правильное поведение.
- Используйте пошаговый режим: Не спешите. Проходите алгоритм шаг за шагом, предсказывая, что произойдёт дальше. Это развивает алгоритмическое мышление.
- Сравните реализации: Переключитесь на очередь на связном списке. Обратите внимание на разницу в использовании памяти и скорости операций.
- Решайте задачи: Многие платформы предлагают встроенные упражнения: «Реализуйте очередь с помощью двух стеков» или «Определите, является ли последовательность скобок правильной, используя очередь». Попробуйте решить их прямо на платформе.
- Пишите код: Используйте редактор кода, чтобы реализовать свою версию очереди. Запустите визуализацию для своего кода — это поможет отладить логику.
Такой подход превращает пассивное чтение в активное исследование. Вы не просто смотрите на анимацию, а управляете процессом, проверяете гипотезы и закрепляете знания на практике.
Преимущества платформы визуализации перед традиционным обучением
- Наглядность: Динамические анимации объясняют сложные концепции (кольцевой буфер, переполнение) лучше, чем десятки страниц текста.
- Интерактивность: Вы можете «трогать» структуру, менять её состояние, видеть мгновенную обратную связь.
- Безопасная среда: Не нужно устанавливать компилятоы или IDE. Всё работает в браузере. Ошибки не приводят к краху программы — вы просто видите предупреждение.
- Универсальность: Платформа поддерживает несколько языков программирования, что позволяет изучать структуру данных независимо от языка.
- Экономия времени: Вместо того чтобы мысленно выполнять алгоритм на бумаге, вы видите готовую анимацию. Это в разы ускоряет понимание.
- Геймификация: Некоторые платформы добавляют элементы игры: очки за правильные ответы, уровни сложности, соревнования. Это повышает мотивацию.
Платформа особенно полезна для визуалов — людей, которые лучше воспринимают информацию через зрительные образы. Но даже если вы предпочитаете текст, визуализация помогает «увидеть» абстракцию и запомнить её надолго.
Заключение: почему очередь на последовательном списке — must-know
Очередь — это не просто учебная структура. Она лежит в основе работы операционных систем, сетевых протоколов, алгоритмов искусственного интеллекта и многих других областей. Умение реализовать очередь на последовательном списке и понимание её особенностей — обязательный навык для любого программиста.
Использование платформы визуализации превращает изучение из скучной теории в увлекательное путешествие. Вы не только узнаёте, как работает очередь, но и видите её «душу» — движение данных, логику указателей, элегантность кольцевого буфера.
Начните прямо сейчас: откройте визуализатор, создайте пустую очередь, добавьте несколько элементов, а затем удалите их. Наблюдайте, как front и rear бегут по массиву, как массив «заворачивается» при достижении границы. Это понимание останется с вами на всю жизнь и поможет в решении сложных задач.
Помните: лучший способ выучить структуру данных — это увидеть её в действии. А наша платформа даёт вам именно такую возможность.
Часто задаваемые вопросы (FAQ)
Вопрос: В чём разница между очередью на массиве и на связном списке?
Ответ: Массив обеспечивает лучшее кэширование и константный доступ по индексу, но требует копирования при расширении. Связный список динамически выделяет память под каждый элемент, но тратит дополнительную память на указатели и имеет более медленный доступ из-за рассредоточенности данных в памяти.
Вопрос: Что такое «кольцевая очередь» и зачем она нужна?
Ответ: Кольцевая очередь (circular buffer) — это способ реализации очереди на массиве, при котором индексы front и rear «зацикливаются». Это позволяет использовать пустые ячейки в начале массива после операций dequeue, избегая бесполезной траты памяти.
Вопрос: Как платформа визуализации помогает понять очередь?
Ответ: Вы видите анимированное изменение указателей, заполнение ячеек массива, а также можете выполнять операции пошагово. Это делает абстрактные концепции наглядными и интуитивно понятными.
Вопрос: Можно ли использовать очередь на последовательном списке в еальных проектах?
Ответ: Да, это одна из самых распространённых реализаций. Например, в Java класс ArrayDeque использует кольцевой массив, а в Python collections.deque реализован на динамическом массиве.
树(Tree)
树是一种非线性的数据结构,它由一组按 分层顺序排列的节点组成。 其中一个节点被指定为根节点,其余的节点可以被划分为不相交的集合,这样每个集合都是根的一个子树。
树的最简单的形式是二叉树。 二叉树由一个根节点和左右子树组成,其中两个子树也是二叉树。每个节点都包含一个数据元素、一个指向左子树的左指针和一个指向右子树的右指针。根元素是由一个“根”指针指向的最顶部的节点。
二叉树 | 可视化完整可视化
1.1 Что такое структура данных? - Учебник по структурам данных Визуализируйте свой код с помощью анимации
Деревья, бинарный поиск, связанные списки: полное руководство по структурам данных с визуализацией
Изучение структур данных и алгоритмов — это основа программирования. Понимание того, как работают деревья, бинарный поиск и связанные списки, открывает путь к эффективному коду. В этой статье мы подробно разберём эти концепции, их особенности, сценарии применения и покажем, как платформа визуализации структур данных помогает освоить их на практике.
Что такое дерево в структурах данных?
Дерево — это иерархическая структура данных, состоящая из узлов (nodes), соединённых рёбрами. Каждый узел содержит значение и ссылки на дочерние узлы. В отличие от линейных структур (массивов, списков), деревья организуют данные с отношением «родитель-потомок». Корневой узел находится на вершине, а листовые узлы не имеют детей.
Основные характеристики деревьев
Глубина узла — расстояние от корня до узла. Высота дерева — максимальная глубина. Степень узла — количество его дочерних узлов. Бинарное дерево — это дерево, где каждый узел имеет не более двух детей (левый и правый). Деревья могут быть сбалансированными (AVL, красно-чёрные) и несбалансированными.
Применение деревьев
Деревья используются в файловых системах, базах данных (B-деревья), синтаксических анализаторах (AST), маршрутизации сетей, сжатии данных (деревья Хаффмана) и в алгоритмах машинного обучения (деревья решений). Иерархическая структура позволяет быстро выполнять операции поиска, вставки и удаления при правильной балансировке.
Бинарный поиск: принцип и особенности
Бинарный поиск — это алгоритм, который находит позицию целевого элемента в отсортированном массиве за логарифмическое время O(log n). Он работает путём деления массива пополам на каждом шаге, сравнивая искомое значение со средним элементом.
Как работает бинарный поиск
Алгоритм поддерживает левую и правую границы. Вычисляется средний индекс. Если значение в середине равно искомому — поиск завершён. Если меньше — поиск продолжается в левой половине, инче — в правой. Процесс повторяется до сужения диапазона до одного элемента.
Условия применения
Массив должен быть отсортирован по возрастанию или убыванию. Бинарный поиск эффективен для статических данных, где операции вставки/удаления редки. Для динамических наборов лучше использовать бинарные деревья поиска.
Примеры использования
Поиск в телефонной книге, проверка наличия слова в словаре, поиск индекса элемента в базе данных, а также в игровых движках для поиска объектов по координатам.
Связанный список: гибкая линейная структура
Связанный список — это последовательность узлов, где каждый узел содержит данные и ссылку на следующий узел (в односвязном списке) или на предыдущий и следующий (в двусвязном). В отличие от массива, элементы не хранятся в смежных ячейках памяти, что позволяет эффективно вставлять и удалять элементы.
Типы связанных списков
Односвязные списки (только ссылка на следующий), двусвязные (ссылки в обе стороны), кольцевые (последний элемент ссылается на первый). Каждый тип имеет свои компромиссы по памяти и скорости операций.
Преимущества и недостатки
Плюсы: динамический размер, быстрая вставка/удаление в начале или середине (если есть указатель на узел). Минусы: медленный доступ по индексу (O(n)), дополнительная память на указатели, неэффективность для кэша процессора.
Где применяются списки
Реализация стеков и очередей, управление памятью (free lists), представление больших чисел, история изменений в редакторах (undo/redo), цепочки в хеш-таблицах для разрешения коллизий.
Как деревья, бинарный поиск и списки связаны между собой?
Бинарное дерево поиска (BST) объединяет концепцию дерева и бинарного поиска. В BST для каждого узла левое поддерево содержит меньшие значения, правое — большие. Это позволяет выполнять поиск, вставку и удаление за O(log n) в среднем. Связанные списки часто используются для реализации очередей обхода дерева (BFS, DFS) и для представления дочерних узлов в некоторых структурах (например, в дереве с произвольным числом детей).
Понимание этих взаимосвязей критически важно для решения задач на собеседованиях и в реальных проектах. Визуализация помогает увидеть, как меняются указатели при поворотах дерева или как бинарный поиск делит массив.
Визуализация структур данных: как это помогает в обучении?
Платформа визуализации структур данных и алгоритмов предлагает интерактивные анимации, которые показывают каждый шаг работы алгоритма. Вы можете увидеть, как создаются узлы дерева, как происходит балансировка, как бинарный поиск сужает диапазон, как вставляется элемент в связанный список.
Основные функции платформы:
- Пошаговые анимации — можно запускать алгоритм шаг за шагом, наблюдая за изменениями.
- Интерактивное редактирование — добавляйте, удаляйте, изменяйте узлы в реальном времени.
- Визуализация памяти — показывается, как данные размещаются в стеке/куче (для списков и деревьев).
- Сравнение алгоритмов — одновременно запускайте бинарный поиск и линейный поиск, чтобы увидеть разницу.
- Встроенные примеры — готовые сценарии для деревьев, списков, сортировок и поиска.
- Поддержка кода — отображается псевдокод или код на Python/Java/C++ с подсветкой строк.
Преимущества использования визуализации:
Абстрактные концепции становятся наглядными. Вы видите, как указатели в списке меняются при вставке, как рекурсия обходит дерево, как бинарный поиск работает без лишних шагов. Это ускоряет понимание и запоминание, особенно для визуалов. Платформа подходит как новичкам, так и опытным разработчикам, готовящимся к собеседованиям.
Как использовать платформу для изучения деревьев, бинарного поиска и списков
1. Начните с базовых структур: откройте модуль «Связанные списки». Создайте односвязный список, добавьте несколько узлов, удалите узел в середине — наблюдайте за изменением ссылок.
2. Перейдите к бинарному поиску: выберите алгоритм «Бинарный поиск» на отсортированном массиве. Введите целевое значение и смотрите, как границы сдвигаются. Обратите внимание на количество шагов.
3. Изучите бинарное дерево поиска: вставьте последовательно числа, наблюдая, как формируется структура. Попробуйте удалить узел с двумя детьми — увидите, как находится преемник.
4. Экспериментируйте с балансировкой: используйте AVL-дерево, чтобы увидеть повороты. Платформа покажет, как меняется высота и как восстанавливается баланс.
5. Комбинируйте: реализуйте обход дерева с помощью стека на основе связанного списка. Визуализация поможет проследить логику.
Советы для максимальной пользы от визуализации
Не просто смотрите анимацию — взаимодействуйте. Изменяйте входные данные, замедляйте скорость, включайте отображение кода. Пытайтесь предсказать следующий шаг алгоритма. Если ошиблись — платформа покажет правильное поведение, и вы поймёте свою ошибку. Используйте режим «сравнение» для оценки производительности разных структур.
Типичные вопросы и задачи для самопроверки
После изучения материалов на платформе попробуйте ответить на вопроы:
- Какова временная сложность поиска в бинарном дереве в худшем случае? (O(n) для несбалансированного, O(log n) для сбалансированного).
- Почему вставка в середину связанного списка быстрее, чем в массив? (Не нужно сдвигать элементы).
- Что произойдёт, если применить бинарный поиск к несортированному массиву? (Алгоритм может не найти элемент или работать некорректно).
- Как найти середину связанного списка за один проход? (Использовать два указателя: быстрый и медленный).
Заключение
Деревья, бинарный поиск и связанные списки — фундаментальные темы в computer science. Без их глубокого понимания невозможно эффективно работать с данными. Платформа визуализации структур данных делает обучение интерактивным и наглядным, помогая увидеть алгоритмы в действии. Начните с простых примеров, постепенно переходите к сложным сценариям, и вы заметите, как улучшится ваше алгоритмическое мышление. Используйте визуализацию как мост между теорией и практикой.
Ключевые слова: дерево, бинарный поиск, связанный список, структуры данных, алгоритмы, визуализация, обучение, бинарное дерево поиска, AVL, односвязный список, двусвязный список, сложность алгоритмов, интерактивная платформа.
图(Graphs)
图是一种非线性的数据结构,它是连接这些顶点的顶点(也称为节点)和边的集合。图通常被视为树结构的泛化,其中树节点之间不是纯粹的父子关系,节点之间的任何复杂关系。在树状结构中,节点可以有任意数量的子节点,但只有一个父节点,但是在图中却没有这些限制。
图的数据结构 | 可视化完整可视化
1.1 Что такое структура данных? - Учебник по структурам данных Визуализируйте свой код с помощью анимации
Что такое граф и зачем нужна структура хранения графа
Граф — это одна из фундаментальных структур данных в информатике, которая представляет собой набор вершин (узлов) и соединяющих их ребер. Графы используются для моделирования множества реальных объектов: социальных сетей, транспортных маршрутов, компьютерных сетей, логистических систем и даже молекул в химии. Для эффективной работы с графами необходимо правильно выбрать способ их хранения в памяти компьютера. В этой статье мы подробно разберем основные методы представления графов: матрицу смежности, список смежности и другие подходы. Также мы расскажем, как визуализация этих структур с помощью специализированного учебного инструмента помогает быстрее понять принципы их работы.
Основные понятия: вершины, ребра, направленные и неориентированные графы
Прежде чем переходить к способам хранения, важно вспомнить базовую терминологию. Вершина (узел) — это элемент графа. Ребро — это связь между двумя вершинами. Если ребро имеет направление, граф называется направленным (ориентированным). Если направление не указано, граф неориентированный. Также ребра могут иметь вес — числовое значение, обозначающее стоимость, расстояние или пропускную способность соединения. Взвешенные графы часто встречаются в задачах поиска кратчайших путей. Понимание этих особенностей напрямую влияет на выбор подходящей структуры хранения.
Матрица смежности: принцип, преимущества и недостатки
Матрица смежности — это двумерный массив размером V×V, где V — количество вершин. Если в графе существует ребро между вершиной i и вершиной j, то элемент матрицы [i][j] равен 1 (или весу ребра для взвешенного графа). В противном случае элемент равен 0. Для неориентированного графа матрица симметрична относительно главной диагонали. Основное преимущество матрицы смежности — это время доступа O(1) для проверки существования ребра. Однако недостаток очевиден: матрица требует O(V²) памяти, что делает ее неэффективной для разреженных графов (где ребер значительно меньше, чем V²). Матрица смежности отлично подходит для плотных графов и для алгоритмов, где чато требуется проверка наличия связи между произвольными вершинами.
Список смежности: экономия памяти и гибкость
Список смежности — это наиболее распространенный способ хранения графов. Для каждой вершины хранится список (или динамический массив) всех соседних вершин. В случае взвешенного графа в списке хранятся пары (сосед, вес). Объем памяти, занимаемый списком смежности, составляет O(V + E), где E — количество ребер. Это делает его идеальным для разреженных графов. Недостаток — проверка существования ребра может занимать O(degree) времени, где degree — степень вершины. Список смежности широко используется в алгоритмах обхода графа: поиск в глубину (DFS) и поиск в ширину (BFS). Он также удобен для реализации алгоритмов на графах, где важна итерация по соседям, например, в алгоритме Дейкстры.
Матрица инцидентности: альтернативный способ для специальных задач
Матрица инцидентности — это таблица размером V×E, где строки соответствуют вершинам, а столбцы — ребрам. Если ребро e соединяет вершину v, то элемент [v][e] равен 1 (для неориентированного графа) или -1/1 (для ориентированного). Этот способ хранения менее популярен, чем матрица и список смежности, но он полезен в некоторых теоретических задачах и в алгоритмах, связанных с потоками в сетях. Недостаток — большой расход памяти для графов с большим количеством ребер (V×E). Матрица инцидентности редко используется на практике из-за неудобства работы с ней.
Сравнение способов хранения: когда что использовать
Выбор структуры хранения графа напрямую зависит от характеристик графа и решаемой задачи. Если граф плотный (количество ребер близко к V²) — выбирайте матрицу смежности. Если граф разреженный (E << V²) — список смежности будет оптимальным по памяти. Если вам нужно часто проверять наличие ребра — матрица смежности дает константное время. Если вы часто итерируете по соседям вершины — список смежности быстрее. Для алгоритмов, работающих с весами ребер, оба подхода могут быть адаптированы. Матрица инцидентности обычно используется только в учебных целях или в специфических математических задачах. Понимание этих компромиссов — ключевой навык для любого разработчика алгоритмов.
Применение графов в реальных задачах
Графы и и структуры хранения лежат в основе множества современных технологий. В социальных сетях (Facebook, VK) графы используются для представления друзей и рекомендаций. В навигационных системах (Яндекс.Карты, Google Maps) графы дорог позволяют строить кратчайшие маршруты. В компьютерных сетях графы моделируют топологию соединений. В базах данных графовые СУБД (Neo4j, ArangoDB) используют списки смежности для эффективного выполнения запросов. В задачах машинного обучения графовые нейронные сети работают с матрицами смежности. Даже в биоинформатике графы применяются для анализа взаимодействия белков. Во всех этих случаях правильный выбор структуры хранения напрямую влияет на производительность системы.
Визуализация структур графа: как учебный инструмент помогает освоить тему
Изучение структур данных "на пальцах" часто бывает сложным, особенно когда речь идет о графах. Традиционные учебники показывают статические картинки, но они не передают динамику процессов. Специализированные платформы для визуализации алгоритмов и структур данных решают эту проблему. Они позволяют в реальном времени увидеть, как меняется матрица смежности при добавлении или удалении ребра, как выглядит список смежности для каждой вершины, как алгоритм обходит граф. Визуальный подход снижает порог входа и ускоряет понимание материала. Особенно это полезно для студентов, которые только начинают изучать алгоритмы на графах.
Функции и преимущества платформы визуализации структур данных
Современная платформа для визуализации структур данных предоставляет пользователю следующие возможности: интерактивное создание и редактирование графа (добавление/удаление вершин и ребер, задание весов), автоматическое построение матрицы смежности и списка смежности на основе введенных данных, пошаговый запуск алгоритмов (DFS, BFS, Дейкстра, Прима, Крускала) с отображением текущего состояния структур хранения, подсветка изменений в реальном времени, возможность сохранения и загрузки примеров графов. Такие платформы часто поддерживают несколько языков, включая русский, что делает их доступными для широкой аудитории. Основное преимущество — наглядность: пользователь видит не только абстрактные числа, но и их графическое представлене.
Как использовать платформу для изучения графов: пошаговое руководство
Для эффективного изучения структур хранения графа с помощью платформы визуализации рекомендуется следующий подход. Шаг 1: создайте небольшой граф (3-5 вершин) в визуальном редакторе — просто нажимайте на поле для добавления вершин и проводите линии для создания ребер. Шаг 2: переключитесь на режим отображения матрицы смежности — вы увидите, как каждое ребро отражается в таблице. Шаг 3: измените граф (добавьте или удалите ребро) и наблюдайте, как мгновенно обновляется матрица. Шаг 4: переключитесь на список смежности и сравните его с матрицей — обратите внимание на разницу в объеме данных. Шаг 5: запустите алгоритм обхода, например BFS, и смотрите, как алгоритм последовательно посещает вершины, используя структуру хранения. Шаг 6: попробуйте создать взвешенный граф и запустить алгоритм Дейкстры — платформа покажет, как веса учитываются при поиске кратчайшего пути. Такой практический подход закрепляет теоретические знания гораздо быстрее, чем простое чтение учебника.
Почему визуализация особенно важна для понимания графов
Графы — это абстрактная структура, которую сложно представить в уме, особенно когда количество вершин превышает десяток. Матрица смежности размером 10×10 уже содержит 100 элементов, и человеку трудно мысленно отследить все связи. Визуализация превращает эти числа в понятные графические образы. Когда студент видит, как ребро между вершинами A и B превращается в единицу в матрице, или как алгоритм поиска в ширину шаг за шагом заполняет список смежности, возникает глубокое понимание материала. Платформа также позволяет экспериментировать: что будет, если сделать граф направленным? Как изменится матрица? Что произойдет, если добавить петлю (ребро из вершины в саму себя)? Мгновенная обратная связь — это мощный педагогический инструмент.
SEO-оптимизированные ключевые слова для изучающих графы
Данная статья содержит ключевые термины, которые помогут студентам и разработчикам найти информацию о структурах хранения графов: граф структура данных, матрица смежности, список смежности, матрица инцидентности, хранение графа в памяти, визуализация алгоритмов, обучение алгоритмам, структуры данных для начинающих, алгоритмы на графах, BFS, DFS, алгоритм Дейкстры, разреженный граф, плотный граф, вес ребра, ориентированный граф, неориентированный граф, учебная платформа по алгоритмам. Использование этих слов в тексте помогает поисковым системам правильно индексировать материал и показывать его целевой аудитории — студентам технических специальностей и программистам, изучающим алгоритмы.
Заключение: выбирайте правильную структуру и используйте визуализацию
Понимание способов хранения графов — это базовый навык, без которого невозможно эффективно решать задачи, связанные с сетевыми структурами. Матрица смежности проста и быстра для плотных графов. Список смежности экономит память и удобен для обходов. Матрица инцидентности полезна в специфических случаях. Выбор зависит от конкретной задачи. Но самое главное — не пытайтесь освоить эти концепции только по тексту. Используйте интерактивные платформы визуализации, которые позволяют увидеть структуру данных в действии. Это сократит время обучения в несколько раз и даст прочное понимание материала. Начните с простого графа из трех вершин, поэкспериментируйте с разными структурами хранения, и вы быстро почувствуете разницу между ними. Удачи в изучении алгоритмов!
❗️ 注意:
请注意,与树不同,图没有任何根节点。相反,图中的每个节点都可以与图中的每一个节点进行连接。当两个节点通过一条边连接时,这两个节点被称为相邻节点。例如,在上图中,节点A有两个邻居:B和D。