 图码
图码2.4 循环链表
循环链表是一种数据结构,其中最后一个节点的next连接回到第一个节点,形成一个循环。此结构允许连续遍历而不会中断。
循环链表对于日程安排和音乐播放列表等任务特别有用,这允许播放完毕后回到第一首继续播放。
在这小节中,我们将介绍循环链表的基础知识、如何使用它们、它们的优点和缺点以及它们的应用。
什么是循环链表?
循环链表是一种特殊类型的链表,其中所有节点都连接起来形成一个环。
与我们前面讲到的链表不同的是,循环链表中的最后一个节点的next指向第一个节点。这意味着当遍历到尾部时可以继续向头部遍历。
循环链表是从单链表和双链表扩展出来的,因此,循环链表基本只有这两种类型。
循环单链表
在循环单链表中,每个节点只有一个指针,称为next指针。 最后一个节点的next指针指向第一个节点,这样就形成了一个环。在循环单链表中,我们只能沿一个方向遍历链表。
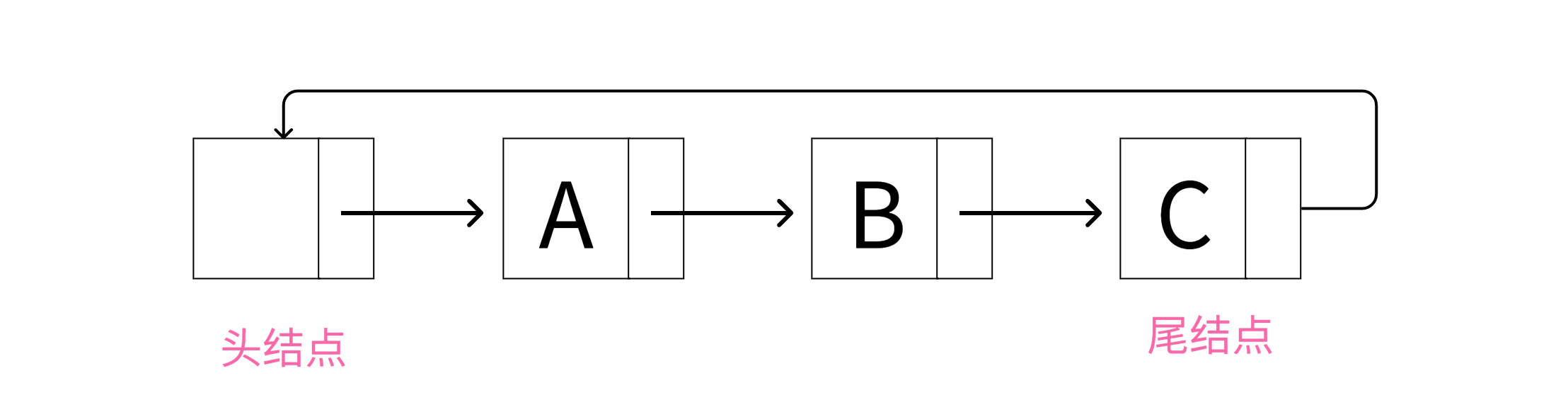
循环单链表结构
数据结构
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
typedef struct LNode {
int data;
struct LNode* next;
} LNode, *LinkList;
LNode* pTemp = (LNode*)malloc(sizeof(LNode));
pTemp->data = e;
pTemp->next = p->next; // 将新节点的next指向p的下一个节点
p->next = pTemp; // 更新p的next指向新节点,完成插入操
// 完整代码:https://totuma.cn- data:数据域,也是节点的值
- next:指针域,指向下一个结点的指针
在上面的定义中,每个节点都有data数据域和next指针域,和普通的单链表结构一模一样,唯一区别就是当我们为循环链表创建多个节点时,我们只需要将最后一个节点连接回第一个节点即可。
循环单链表的基本操作实现
创建循环单链表
插入是链表中的基本操作。和普通单链表的唯一区别是将最后一个节点的next连接到第头结点。
插入大概可以分为以下三种情况
1.在空链表中插入新结点
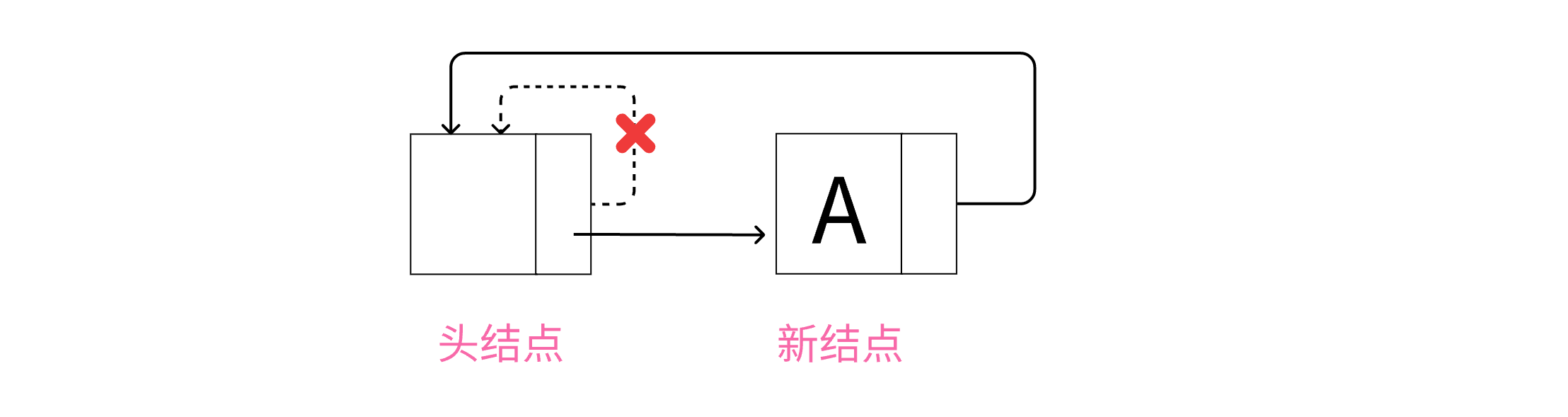
在空链表中插入新结点
这里使用的是带头结点的单链表来实现循环链表,所以链表空的条件是头结点的next指向头结点,即头结点自己指向自己。
在空的循环链表中插入一个节点,需要创建一个新结点,将其next指针指向头结点,以达到循环的目的。
2.在链表中部插入新结点
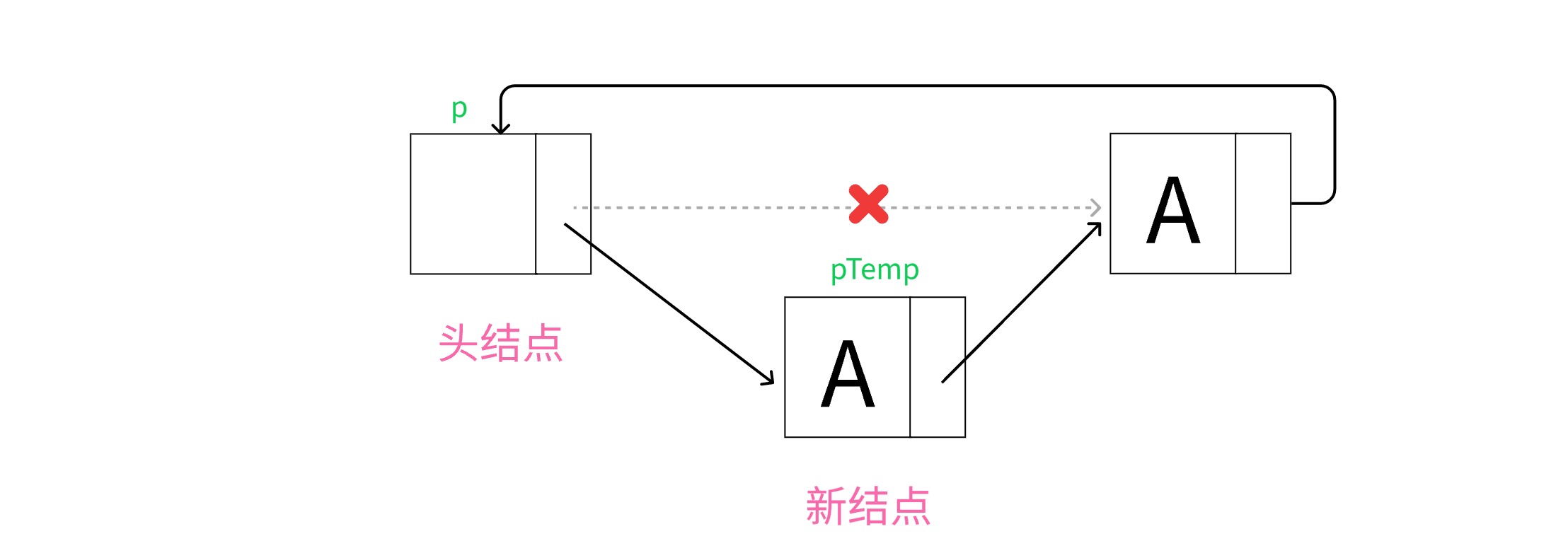
在链表中部插入新结点
和普通单链表操作一样,在中部插入结点并没有改变尾结点next的指向。
3.在链表尾部插入新结点
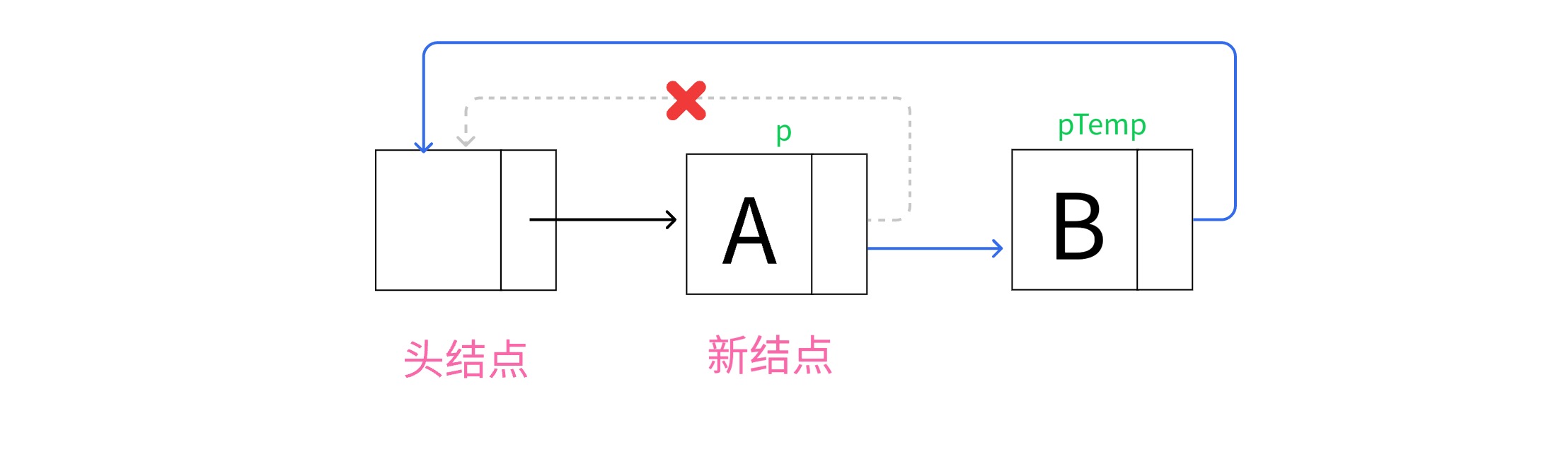
在链表尾部插入新结点
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
typedef struct LNode {
int data;
struct LNode* next;
} LNode, *LinkList;
LNode* pTemp = (LNode*)malloc(sizeof(LNode));
pTemp->data = e;
pTemp->next = p->next; // 将新节点的next指向p的下一个节点
p->next = pTemp; // 更新p的next指向新节点,完成插入操
// 完整代码:https://totuma.cn上面三种情况,都可以统一为同一操作:
1.找到待插入位置的前驱结点,即p;
2.创建新结点pTemp;
3.使pTemp的next指向p的next;
(如果是空链表,那么p的next指向头结点本身。如果是在末尾插入,p的next同样也是指向头结点)
4.使p的next指向pTemp;
按位序插入结点 | 可视化完整可视化
2.4 Подробное объяснение циклического односвязного списка - Учебник по линейным спискам Визуализируйте свой код с помощью анимации

Линейные списки и связные списки: Полное руководство для изучения структур данных
В мире программирования и алгоритмов структуры данных играют фундаментальную роль. Одной из базовых и наиболее важных структур является линейный список. В этой статье мы подробно разберем, что такое линейные списки, особое внимание уделим связным спискам (linked lists), их принципам работы, преимуществам и недостаткам, а также реальным сценариям использования. Если вы изучаете структуры данных и алгоритмы, это руководство поможет вам понять ключевые концепции, необходимые для успешного прохождения собеседований и написания эффективного кода.
Что такое линейный список?
Линейный список — это упорядоченная коллекция элементов, где каждый элемент имеет свой порядковый номер (индекс) и последовательность строго определена. В отличие от нелинейных структур (например, деревьев или графов), в линейном списке каждый элемент, кроме первого и последнего, имеет ровно одного предшественника и одного последователя. Основные операции над линейными списками включают вставку, удаление, поиск элемента по индексу или значению, а также обход всех элементов.
Существует два основных способа реализации линейного списка: на основе массива (статический или динамический массив) и на основе связных узлов (связный список). Каждый подход имеет свои сильные и слабые стороны, которые мы рассмотрим далее.
Связный список: Определение и базовая структура
Связный список (linked list) — это динамическая структура данных, состоящая из узлов (nodes). Каждый узел содержит два основных поля: данные (data) и ссылку (указатель) на следующий узел в последовательности. В отличие от массива, элементы связного списка не хранятся в непрерывной области памяти. Это дает гибкость при вставке и удалении элементов, но требует последовательного доступа для поиска.
Основные типы связных списков включают:
- Односвязный список (singly linked list) — каждый узел содержит ссылку только на следующий узел.
- Двусвязный список (doubly linked list) — каждый узел содержит ссылки как на следующий, так и на предыдущий узел.
- Кольцевой связный сисок (circular linked list) — последний узел ссылается на первый, образуя замкнутый цикл.
Принцип работы односвязного списка
Рассмотрим односвязный список подробнее. Представьте себе цепочку, где каждое звено — это узел. Вы держите в руках первое звено (голову списка). Чтобы добраться до третьего звена, вам нужно пройти через второе. Это ключевая особенность: доступ к элементу по индексу в связном списке требует O(n) времени, так как нужно последовательно пройти от головы до нужной позиции.
Однако вставка и удаление элементов в середине списка выполняются очень быстро — за O(1) после того, как вы нашли нужную позицию. Это огромное преимущество перед массивами, где вставка в середину требует сдвига всех последующих элементов.
Пример реализации узла на языке C++:
struct Node {
int data;
Node* next;
};Голова списка — это указатель на первый узел. Если список пуст, голова равна nullptr.
Двусвязный список: Дополнительные возможности
Двусвязный список расширяет концепцию односвязного, добавляя указатель на предыдущий узел. Это позволяет проходить список в обоих направлениях и упрощает удаление узла, если у вас есть ссылка на него (не нужно искать предыдущий элемент). Однако каждый узел занимает больше памяти из-за хранения двух указателей.
Структура узла двусвязного списка:
struct DoublyNode {
int data;
DoublyNode* next;
DoublyNode* prev;
};Двусвязные списки часто используются в реализации таких структур, как deque (двусторонняя очередь) и в некоторых алгоритмах кэширования (например, LRU cache).
Кольцевой связный список
В кольцевом связном списке последний узел указывает не на nullptr, а на первый узел. Это создает замкнутый цикл. Такая структура полезна для задач, где требуется циклический обход элементов, например, в планировщиках задач (round-robin scheduling) или в реализации игровых циклов.
Важно отметить, что при работе с кольцевыми списками нужно быть осторожным, чтобы не создать бесконечный цикл при обходе. Обычно для остановки используют счетчик пройденных элементов или специальное условие.
Сравнение связного списка и массива
Для лучшего понимания, когда использовать связный список, а когда массив, приведем таблицу сравнения по ключевым операциям:
Доступ по индексу: Массив — O(1), связный список — O(n).
Вставка в начало/середину: Массив — O(n) (требуется сдвиг), связный список — O(1) после нахождения позиции.
Удаление из начала/середины: Массив — O(n), связный список — O(1) после нахождения позиции.
Вставка в конец: Массив — O(1) амортизированно (если есть место), связный список — O(1) если хранить указатель на хвост.
Потребление памяти: Массив — меньше накладных расходов, связный список — дополнительная память на указатели.
Локальность данных (cache locality): Массив — высокая, связный список — низкая.
Из этого сравнения видно, что связные списки выигрывают в сценариях с частыми вставками и удалениями, особенно в середине списка. Массивы лучше подходят для задач с частым доступом по индексу.
Применение связных списков в реальных задачах
Связные списки широко используются в различных областях программирования:
1. Реализация стеков и очередей. Связные списки позволяют эффективно реализовать стек (LIFO) и очередь (FIFO) с операциями вставки и удаления за O(1).
2. Управление памятью в операционных системах. Свободные блоки памяти часто организованы в виде связного списка для эффективного выделения и освобождения.
3. Графы и списки смежности. Для представления графов часто используется массив связных списков, где каждый список содержит соседей соответствующей вершины.
4. Реализация хеш-таблиц с цепочками. Для разрешения коллизий в хеш-таблицах используется связный список элементов, попавших в одну ячейку.
5. Музыкальные плееры и редакторы. Плейлисты часто реализуются как двусвязные списки, позволяющие легко перемещаться между треками и добавлять/удалять элементы.
6. Отмена действий (undo/redo). Двусвязные списки идеально подходят для реализации стека отмены, где можно двигаться вперед и назад по истории изменений.
Алгоритмы работы со связными списками
Для успешного освоения темы необходимо знать базовые алгоритмы:
Обход списка: Начиная с головы, последовательно переходим по указателям next до тех пор, пока не достигнем nullptr.
Вставка узла: Создаем новый уел, устанавливаем его указатель next на следующий узел, а указатель предыдущего узла перенаправляем на новый узел.
Удаление узла: Перенаправляем указатель предыдущего узла на следующий после удаляемого, затем освобождаем память удаляемого узла.
Поиск элемента: Последовательно проходим по списку, сравнивая данные каждого узла с искомым значением.
Разворот списка: Изменяем направление указателей next так, чтобы последний элемент стал первым. Это классическая задача на собеседованиях.
Обнаружение цикла: Используем алгоритм "черепахи и зайца" (Floyd's cycle detection) для проверки, есть ли в списке цикл.
Нахождение середины списка: Используем два указателя — медленный (двигается на один шаг) и быстрый (двигается на два шага). Когда быстрый достигает конца, медленный указывает на середину.
Преимущества и недостатки связных списков
Преимущества:
- Динамический размер — память выделяется по мере необходимости.
- Быстрая вставка и удаление в любой позиции (при наличии указателя на место вставки).
- Отсутствие необходимости в предварительном выделении большого блока памяти.
Недостатки:
- Медленный доступ по индексу (только последовательный).
- Дополнительные затраты памяти на хранение указателей.
- Плохая локальность данных, что может привести к частым промахам кэша процессора.
- Сложность реализации по сравнению с массивами (необходимость ручного управления памятью).
Как визуализация помогает в изучении связных списков
Изучение структур даннх, особенно связных списков, может быть сложным из-за абстрактности указателей и динамического выделения памяти. Визуализация — мощный инструмент, который превращает абстрактные концепции в наглядные образы.
На платформе визуализации структур данных и алгоритмов вы можете:
1. Наблюдать пошаговое выполнение операций. Вы видите, как создаются узлы, как меняются указатели при вставке и удалении. Это помогает понять, почему операции имеют ту или иную временную сложность.
2. Экспериментировать в реальном времени. Вы можете добавлять и удалять элементы, наблюдать, как меняется структура списка. Это интерактивное обучение гораздо эффективнее пассивного чтения.
3. Визуализировать алгоритмы. Алгоритмы вроде разворота списка или обнаружения цикла становятся понятными, когда вы видите, как указатели перемещаются шаг за шагом.
4. Сравнивать разные реализации. Вы можете одновременно видеть, как работает односвязный и двусвязный список, и понимать разницу в операциях.
5. Отлаживать свой код. Если вы пишете реализацию связного списка, визуализация поможет быстро найти ошибки в логике указателей.
Функционал платформы визуализации для изучения линейных списков
Наша платформа предлагает специально разработанные инструменты для изучения линейных списков и связных списков:
Интерактивный редактор списков. Вы можете создавать списки любой длины, добавлять элементы в начало, онец или произвольную позицию. Каждое действие мгновенно отображается на схеме.
Пошаговый режим выполнения. Запустите алгоритм (например, поиск элемента или разворот списка) и наблюдайте за каждым шагом с подробными пояснениями. Это идеально для подготовки к экзаменам и собеседованиям.
Встроенный компилятор и визуализатор кода. Напишите свою реализацию на C++, Java или Python, и платформа покажет, как ваш код работает с памятью. Вы увидите, где происходит утечка памяти или неправильное связывание узлов.
Библиотека готовых примеров. Изучайте классические задачи: разворот списка, объединение двух отсортированных списков, удаление дубликатов, обнаружение цикла и многие другие.
Режим тетирования. Проверьте свои знания с помощью автоматических тестов. Платформа сгенерирует случайные списки и проверит, правильно ли работает ваш алгоритм.
Практические советы по изучению связных списков
Вот несколько рекомендаций, которые помогут вам быстрее освоить эту тему:
1. Начните с односвязного списка. Освойте базовые операции: создание, обход, вставка, удаление. Только после этого переходите к двусвязным и кольцевым спискам.
2. Рисуйте схемы на бумаге. Перед тем как писать код, нарисуйте список и покажите стрелками, как должны меняться указатели. Это поможет избежать логических ошибок.
3. Используйте визуализацию. Наша платформа позволяет видеть, что происходит в памяти вашего компьютера. Используйте эту возможность, чтобы проверять свои гипотезы.
4. Решайте задачи на LeetCode и Codeforces. Начните с простых задач (например, "Reverse Linked List"), затем переходите к более сложным ("Merge k Sorted Lists", "Copy List with Random Pointer").
5. Изучайте рекурсивные подходы. Многие операции со списками (например, разворот) можно элегантно реализовать рекурсивно. Понимание рекурсии на списках поможет в изучении деревьев и графов.
6. Не забывайте про управление памятью. Если вы работаете на C или C++, всегда освобождайте память после удаления узлов. Утечки памяти в списках — одна из самых частых ошибок.
Заключение
Связные списки — это фундаментальная структура данных, которую необходимо знать каждому программисту. Они являются основой для многих других структур (стеки, очереди, графы) и часто встречаются на собеседованях в крупные технологические компании.
Понимание принципов работы связных списков, их преимуществ и недостатков, а также умение реализовывать базовые алгоритмы — это важный шаг в освоении структур данных и алгоритмов. Используйте визуализацию, чтобы сделать процесс обучения более наглядным и эффективным.
Начните изучение прямо сейчас на нашей платформе: создайте свой первый связный список, поэкспериментируйте с вставкой и удалением элементов, визуализируйте алгоритм разворота. Интерактивное обучение поможет вам быстрее понять сложные концепции и закрепить знания на практике.
Помните: в программировании нет ничего сложного, если подойти к изучению системно и использовать правильные инструменты. Связные списки — это только начало вашего пути в мир структур данных. Удачи в обучении!
为什么要使用头插法创建,而不是尾插法创建?
如果我们要在链表末尾进行插入,那么需要先遍历整个链表找到尾结点,或者使用一个变量记录尾结点的。
而且每次都需要改变尾结点的next指向头结点,以达到循环。
而我们使用头插法,无论链表是否为空,代码都是统一不变,不需要做其他判断。
按位序删除结点
删除操作和普通单链表相同。主要区别在于我们需要确保删除后链表保持循环。
要从循环链表中删除特定的结点,首先需要检查删除的位序是否满足条件。
找到待删除结点的前驱结点即p结点
找到前驱结点p后,使用q记录为待删除结点
修改前驱结点p的next指向待删除结点q的next,即跳过q结点并将其删除
仅有一个结点时,循环指向头结点
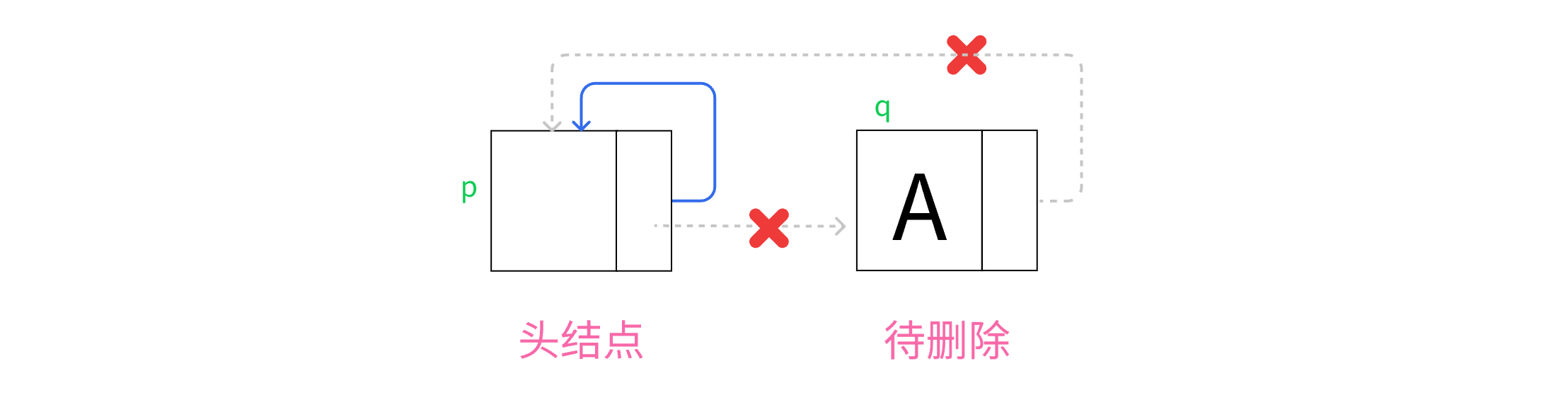
仅有一个结点时,循环指向头结点
删除尾部结点,更新链表循环
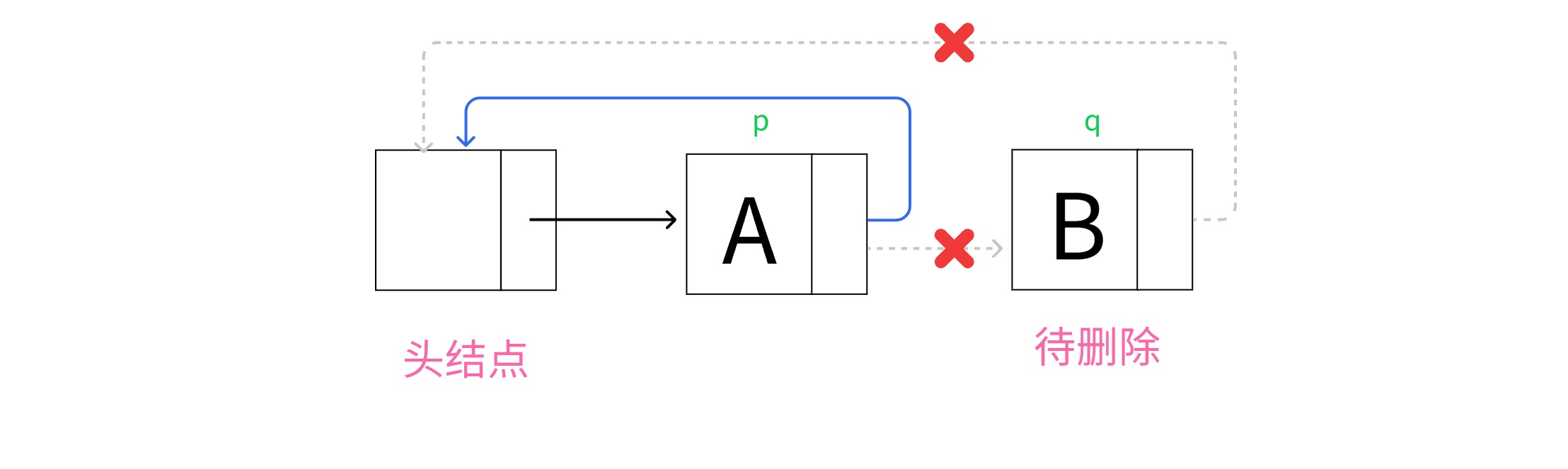
删除尾部结点,更新链表循环
删除中间结点
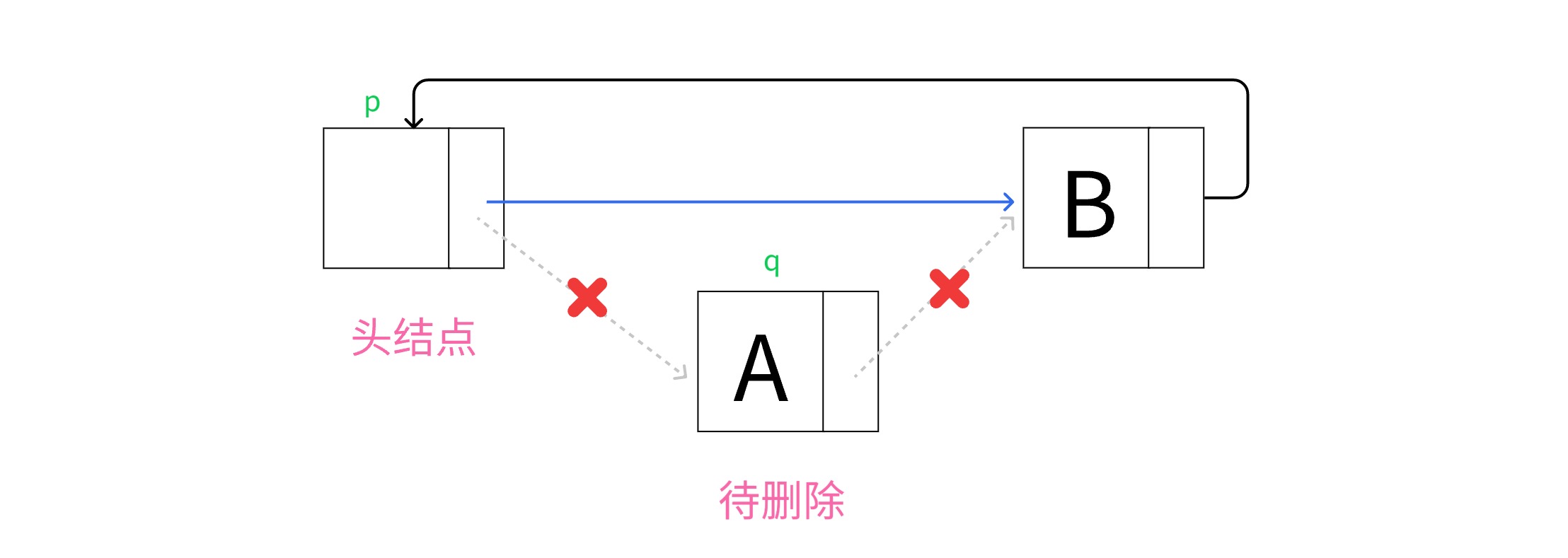
删除中间结点
💡 提示
对于带头结点的链表,上面三种情况都可以统一为同一种操作代码
按位序删除结点 | 可视化完整可视化
2.4 Подробное объяснение циклического односвязного списка - Учебник по линейным спискам Визуализируйте свой код с помощью анимации
Линейные списки и связные списки: Полное руководство для изучения структур данных
В мире программирования и алгоритмов структуры данных играют фундаментальную роль. Одной из базовых и наиболее важных структур является линейный список. В этой статье мы подробно разберем, что такое линейные списки, особое внимание уделим связным спискам (linked lists), их принципам работы, преимуществам и недостаткам, а также реальным сценариям использования. Если вы изучаете структуры данных и алгоритмы, это руководство поможет вам понять ключевые концепции, необходимые для успешного прохождения собеседований и написания эффективного кода.
Что такое линейный список?
Линейный список — это упорядоченная коллекция элементов, где каждый элемент имеет свой порядковый номер (индекс) и последовательность строго определена. В отличие от нелинейных структур (например, деревьев или графов), в линейном списке каждый элемент, кроме первого и последнего, имеет ровно одного предшественника и одного последователя. Основные операции над линейными списками включают вставку, удаление, поиск элемента по индексу или значению, а также обход всех элементов.
Существует два основных способа реализации линейного списка: на основе массива (статический или динамический массив) и на основе связных узлов (связный список). Каждый подход имеет свои сильные и слабые стороны, которые мы рассмотрим далее.
Связный список: Определение и базовая структура
Связный список (linked list) — это динамическая структура данных, состоящая из узлов (nodes). Каждый узел содержит два основных поля: данные (data) и ссылку (указатель) на следующий узел в последовательности. В отличие от массива, элементы связного списка не хранятся в непрерывной области памяти. Это дает гибкость при вставке и удалении элементов, но требует последовательного доступа для поиска.
Основные типы связных списков включают:
- Односвязный список (singly linked list) — каждый узел содержит ссылку только на следующий узел.
- Двусвязный список (doubly linked list) — каждый узел содержит ссылки как на следующий, так и на предыдущий узел.
- Кольцевой связный сисок (circular linked list) — последний узел ссылается на первый, образуя замкнутый цикл.
Принцип работы односвязного списка
Рассмотрим односвязный список подробнее. Представьте себе цепочку, где каждое звено — это узел. Вы держите в руках первое звено (голову списка). Чтобы добраться до третьего звена, вам нужно пройти через второе. Это ключевая особенность: доступ к элементу по индексу в связном списке требует O(n) времени, так как нужно последовательно пройти от головы до нужной позиции.
Однако вставка и удаление элементов в середине списка выполняются очень быстро — за O(1) после того, как вы нашли нужную позицию. Это огромное преимущество перед массивами, где вставка в середину требует сдвига всех последующих элементов.
Пример реализации узла на языке C++:
struct Node {
int data;
Node* next;
};Голова списка — это указатель на первый узел. Если список пуст, голова равна nullptr.
Двусвязный список: Дополнительные возможности
Двусвязный список расширяет концепцию односвязного, добавляя указатель на предыдущий узел. Это позволяет проходить список в обоих направлениях и упрощает удаление узла, если у вас есть ссылка на него (не нужно искать предыдущий элемент). Однако каждый узел занимает больше памяти из-за хранения двух указателей.
Структура узла двусвязного списка:
struct DoublyNode {
int data;
DoublyNode* next;
DoublyNode* prev;
};Двусвязные списки часто используются в реализации таких структур, как deque (двусторонняя очередь) и в некоторых алгоритмах кэширования (например, LRU cache).
Кольцевой связный список
В кольцевом связном списке последний узел указывает не на nullptr, а на первый узел. Это создает замкнутый цикл. Такая структура полезна для задач, где требуется циклический обход элементов, например, в планировщиках задач (round-robin scheduling) или в реализации игровых циклов.
Важно отметить, что при работе с кольцевыми списками нужно быть осторожным, чтобы не создать бесконечный цикл при обходе. Обычно для остановки используют счетчик пройденных элементов или специальное условие.
Сравнение связного списка и массива
Для лучшего понимания, когда использовать связный список, а когда массив, приведем таблицу сравнения по ключевым операциям:
Доступ по индексу: Массив — O(1), связный список — O(n).
Вставка в начало/середину: Массив — O(n) (требуется сдвиг), связный список — O(1) после нахождения позиции.
Удаление из начала/середины: Массив — O(n), связный список — O(1) после нахождения позиции.
Вставка в конец: Массив — O(1) амортизированно (если есть место), связный список — O(1) если хранить указатель на хвост.
Потребление памяти: Массив — меньше накладных расходов, связный список — дополнительная память на указатели.
Локальность данных (cache locality): Массив — высокая, связный список — низкая.
Из этого сравнения видно, что связные списки выигрывают в сценариях с частыми вставками и удалениями, особенно в середине списка. Массивы лучше подходят для задач с частым доступом по индексу.
Применение связных списков в реальных задачах
Связные списки широко используются в различных областях программирования:
1. Реализация стеков и очередей. Связные списки позволяют эффективно реализовать стек (LIFO) и очередь (FIFO) с операциями вставки и удаления за O(1).
2. Управление памятью в операционных системах. Свободные блоки памяти часто организованы в виде связного списка для эффективного выделения и освобождения.
3. Графы и списки смежности. Для представления графов часто используется массив связных списков, где каждый список содержит соседей соответствующей вершины.
4. Реализация хеш-таблиц с цепочками. Для разрешения коллизий в хеш-таблицах используется связный список элементов, попавших в одну ячейку.
5. Музыкальные плееры и редакторы. Плейлисты часто реализуются как двусвязные списки, позволяющие легко перемещаться между треками и добавлять/удалять элементы.
6. Отмена действий (undo/redo). Двусвязные списки идеально подходят для реализации стека отмены, где можно двигаться вперед и назад по истории изменений.
Алгоритмы работы со связными списками
Для успешного освоения темы необходимо знать базовые алгоритмы:
Обход списка: Начиная с головы, последовательно переходим по указателям next до тех пор, пока не достигнем nullptr.
Вставка узла: Создаем новый уел, устанавливаем его указатель next на следующий узел, а указатель предыдущего узла перенаправляем на новый узел.
Удаление узла: Перенаправляем указатель предыдущего узла на следующий после удаляемого, затем освобождаем память удаляемого узла.
Поиск элемента: Последовательно проходим по списку, сравнивая данные каждого узла с искомым значением.
Разворот списка: Изменяем направление указателей next так, чтобы последний элемент стал первым. Это классическая задача на собеседованиях.
Обнаружение цикла: Используем алгоритм "черепахи и зайца" (Floyd's cycle detection) для проверки, есть ли в списке цикл.
Нахождение середины списка: Используем два указателя — медленный (двигается на один шаг) и быстрый (двигается на два шага). Когда быстрый достигает конца, медленный указывает на середину.
Преимущества и недостатки связных списков
Преимущества:
- Динамический размер — память выделяется по мере необходимости.
- Быстрая вставка и удаление в любой позиции (при наличии указателя на место вставки).
- Отсутствие необходимости в предварительном выделении большого блока памяти.
Недостатки:
- Медленный доступ по индексу (только последовательный).
- Дополнительные затраты памяти на хранение указателей.
- Плохая локальность данных, что может привести к частым промахам кэша процессора.
- Сложность реализации по сравнению с массивами (необходимость ручного управления памятью).
Как визуализация помогает в изучении связных списков
Изучение структур даннх, особенно связных списков, может быть сложным из-за абстрактности указателей и динамического выделения памяти. Визуализация — мощный инструмент, который превращает абстрактные концепции в наглядные образы.
На платформе визуализации структур данных и алгоритмов вы можете:
1. Наблюдать пошаговое выполнение операций. Вы видите, как создаются узлы, как меняются указатели при вставке и удалении. Это помогает понять, почему операции имеют ту или иную временную сложность.
2. Экспериментировать в реальном времени. Вы можете добавлять и удалять элементы, наблюдать, как меняется структура списка. Это интерактивное обучение гораздо эффективнее пассивного чтения.
3. Визуализировать алгоритмы. Алгоритмы вроде разворота списка или обнаружения цикла становятся понятными, когда вы видите, как указатели перемещаются шаг за шагом.
4. Сравнивать разные реализации. Вы можете одновременно видеть, как работает односвязный и двусвязный список, и понимать разницу в операциях.
5. Отлаживать свой код. Если вы пишете реализацию связного списка, визуализация поможет быстро найти ошибки в логике указателей.
Функционал платформы визуализации для изучения линейных списков
Наша платформа предлагает специально разработанные инструменты для изучения линейных списков и связных списков:
Интерактивный редактор списков. Вы можете создавать списки любой длины, добавлять элементы в начало, онец или произвольную позицию. Каждое действие мгновенно отображается на схеме.
Пошаговый режим выполнения. Запустите алгоритм (например, поиск элемента или разворот списка) и наблюдайте за каждым шагом с подробными пояснениями. Это идеально для подготовки к экзаменам и собеседованиям.
Встроенный компилятор и визуализатор кода. Напишите свою реализацию на C++, Java или Python, и платформа покажет, как ваш код работает с памятью. Вы увидите, где происходит утечка памяти или неправильное связывание узлов.
Библиотека готовых примеров. Изучайте классические задачи: разворот списка, объединение двух отсортированных списков, удаление дубликатов, обнаружение цикла и многие другие.
Режим тетирования. Проверьте свои знания с помощью автоматических тестов. Платформа сгенерирует случайные списки и проверит, правильно ли работает ваш алгоритм.
Практические советы по изучению связных списков
Вот несколько рекомендаций, которые помогут вам быстрее освоить эту тему:
1. Начните с односвязного списка. Освойте базовые операции: создание, обход, вставка, удаление. Только после этого переходите к двусвязным и кольцевым спискам.
2. Рисуйте схемы на бумаге. Перед тем как писать код, нарисуйте список и покажите стрелками, как должны меняться указатели. Это поможет избежать логических ошибок.
3. Используйте визуализацию. Наша платформа позволяет видеть, что происходит в памяти вашего компьютера. Используйте эту возможность, чтобы проверять свои гипотезы.
4. Решайте задачи на LeetCode и Codeforces. Начните с простых задач (например, "Reverse Linked List"), затем переходите к более сложным ("Merge k Sorted Lists", "Copy List with Random Pointer").
5. Изучайте рекурсивные подходы. Многие операции со списками (например, разворот) можно элегантно реализовать рекурсивно. Понимание рекурсии на списках поможет в изучении деревьев и графов.
6. Не забывайте про управление памятью. Если вы работаете на C или C++, всегда освобождайте память после удаления узлов. Утечки памяти в списках — одна из самых частых ошибок.
Заключение
Связные списки — это фундаментальная структура данных, которую необходимо знать каждому программисту. Они являются основой для многих других структур (стеки, очереди, графы) и часто встречаются на собеседованях в крупные технологические компании.
Понимание принципов работы связных списков, их преимуществ и недостатков, а также умение реализовывать базовые алгоритмы — это важный шаг в освоении структур данных и алгоритмов. Используйте визуализацию, чтобы сделать процесс обучения более наглядным и эффективным.
Начните изучение прямо сейчас на нашей платформе: создайте свой первый связный список, поэкспериментируйте с вставкой и удалением элементов, визуализируйте алгоритм разворота. Интерактивное обучение поможет вам быстрее понять сложные концепции и закрепить знания на практике.
Помните: в программировании нет ничего сложного, если подойти к изучению системно и использовать правильные инструменты. Связные списки — это только начало вашего пути в мир структур данных. Удачи в обучении!