 图码
图码2.3 双链表
单链表结点中只有一个指向其后继的指针,使得单链表只能从前往后依次遍历。要访问某个结点的前驱(插入、删除操作时),只能从头开始遍历,访问前驱的时间复杂度为 O(n)。
为了克服单链表的这个缺点,引入了双链表,双链表结点中有两个指针prior和next,分别指向其直接前驱和直接后继。
双链表的主要特性
- 双向遍历由于每个节点都有前后两个指针,因此可以在列表中双向遍历,无需像单链表那样只能从头节点开始向前遍历。
- 插入与删除的便捷性:在双链表中插入或删除一个节点时,只需改变相应节点的前后节点的指针指向即可,操作相对简单高效。
数据结构
- data:数据域,也是节点的值
- prior:指针域,指向前一个结点的指针
- next:指针域,指向下一个结点的指针
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
typedef struct DNode {
int data; // 数据
struct DNode *prior, *next; // 前驱和后继指针
} DNode, *DLinkList;
pTemp = (DNode *)malloc(sizeof(DNode));
pTemp->data = x;
pTemp->next = pHead->next;
pTemp->prior = pHea
// 完整代码:https://totuma.cn
链表结构
💡双链表在单链表结点中增加了一个指向其前驱的指针prior ,因此双链表的按值查找和按位查找的操作与单链表的相同。但双链表在插入和删除操作的实现上,与单链表有着较大的不同。 这是因为“链”变化时也需要对指针 prior 做出修改,其关键是保证在修改的过程中不断链。 此外,双链表可以很方便地找到当前结点的前驱,因此,插入、除操作的时间复杂度仅为 O(1)。
双链表的基本操作实现
单链表的节点在需要时动态分配内存,这意味着不需要像数组那样在创建时预先分配一大片连续内存。因此,单链表在内存使用上更加灵活,可以有效应对内存碎片和动态增长的问题。
由于链表节点是在需要时分配的,可以避免数组因初始化大小不确定而造成的内存浪费。例如,如果数组大小初始化过大,未使用的部分将浪费内存;若初始化过小,则可能需要频繁重新分配和复制。
每个节点需要一个指针域来存储对下一个节点的引用,这意味着相比于数组,单链表在每个节点上都会有额外的内存开销。对于存储小数据的场景,这个开销相对较大,可能导致内存利用率下降。
按位序插入结点
该函数用于在双向链表中按指定位置插入一个新元素。(注意区分位置和下标:位置从1开始,下标从0开始)
在位置 i 插入元素 e,其中 i=1 表示插入到表头,i=length+1 表示插入到表尾。
重点注意下链表为空和不为空时的处理逻辑
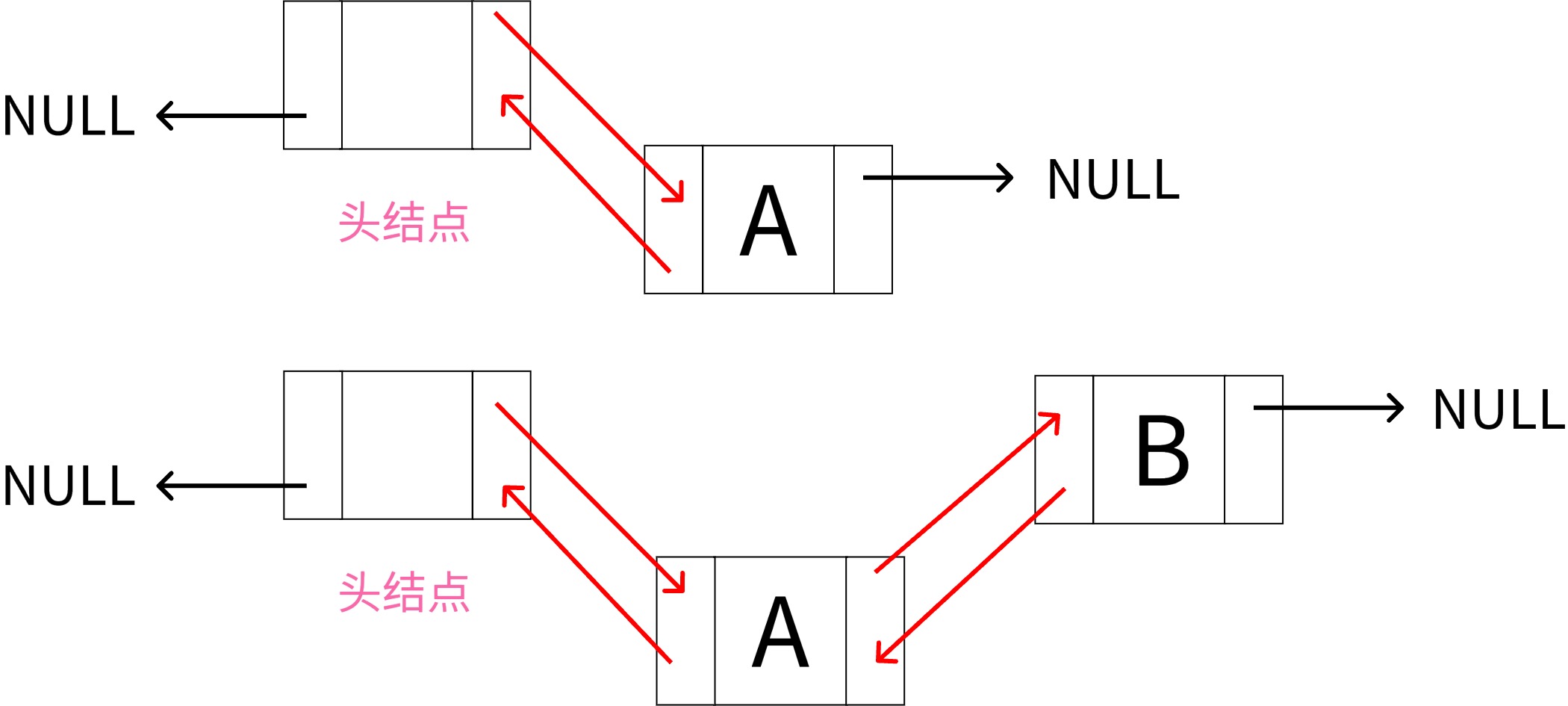
插入时链表空和不空时的区别
按位序插入结点 | 可视化完整可视化
2.3 Подробное объяснение двусвязного списка - Учебник по линейным спискам Визуализируйте свой код с помощью анимации

Линейные списки и связные списки: Полное руководство для изучающих структуры данных и алгоритмы
В мире программирования структуры данных являются фундаментом, на котором строятся эффективные алгоритмы. Одной из самых базовых и важных структур данных является линейный список. В этой статье мы подробно разберем, что такое линейные списки, особое внимание уделим связным спискам (linked lists), их принципам работы, преимуществам и недостаткам, а также реальным сценариям применения. Если вы изучаете структуры данных и алгоритмы, это руководство поможет вам понять ключевые концепции, которые пригодятся на собеседованиях и в практической разработке.
Что такое линейный список? Определение и основные свойства
Линейный список — это упорядоченная коллекция элементов, где каждый элемент (узел) имеет уникальную позицию. Представьте себе список покупок: у вас есть первый пункт, второй, третий и так далее. В программировании линейные списки могут быть реализованы по-разному: с помощью массива (статический список) или с помощью связных узлов (динамический список). Основное свойство линейного списка — это линейный порядок: каждый элемент, кроме первого и последнего, имеет ровно одного предшественника и одного последователя.
Связный список (Linked List): подробный разбор
Связный список — это динамическая структура данных, состоящая из узлов. Каждый узел содержит данные (значение) и указатель (ссылку) на следующий узел в последовательности. В отличие от массива, элементы связного списка не хранятся в непрерывной области памяти. Это ключевое отличие, которое дает связным спискам уникальные свойства.
Основные виды связных списков
Односвязный список (Singly Linked List): Каждый узел содержит данные и указатель только на следующий узел. Обход возможен только в одном направлении — от головы (head) к хвосту (tail). Последний узел указывает на null (None в Python).
Двусвязный список (Doubly Linked List): Каждый узел содержит данные, указатель на следующий узел и указатель на предыдущий узел. Это позволяет обходить список в обоих направлениях, что упрощает некоторые операции (например, удаление узла по ссылке).
Кольцевой (циклический) связный список (Circular Linked List): В такой структуре последний узел указывает не на null, а на первый узел, образуя замкнутый цикл. Это удобно для задач, где требуется циклический обход (например, игровые циклы или планировщики задач).
Принцип работы связного списка: как это выглядит в памяти
Представьте, что у вас есть цепочка из бумажных полосок, скрепленных скрепками. Каждая полоска — это узел с данными, а скрепка — это указатель на следующий узел. Если вы хотите добавить новую полоску в середину цепочки, вам не нужно переписывать всю цепочку — достаточно разомкнуть скрепки в нужном месте и вставить новый элемент. Именно так работает вставка в связный список: вы просто меняете указатели, не перемещая остальные элементы.
При удалении элемента из связного списка вы перенаправляете указатель предыдущего узла на узел, следующий за удаляемым. Сам удаляемый узел затем может быть освобожден сборщиком мусора (в языках с автоматическим управлением памятью) или удален вручную (в C/C++).
Преимущества связных списков перед массивами
Динамический размер: Связный список может расти и уменьшаться во время выполнения программы без необходимости перераспределения памяти. Массив же имеет фиксированный размер (в статических языках) или требует дорогостоящей операции изменения размера (например, при переполнении ArrayList в Java).
Эффективная вставка и удаление: Вставка нового элемента в начало или середину списка, а также удалени элемента, выполняется за O(1) (константное время), если у вас есть ссылка на нужную позицию. В массиве вставка в начало требует сдвига всех остальных элементов — это O(n).
Отсутствие фрагментации памяти (в некоторых случаях): Хотя узлы списка разбросаны по памяти, они не требуют непрерывного блока, что может быть полезно при работе с ограниченной памятью или при частых операциях выделения/освобождения.
Недостатки связных списков
Медленный доступ по индексу: Чтобы получить элемент с индексом i, нужно пройти по списку от головы до i-го узла — это O(n). В массиве доступ по индексу — O(1).
Дополнительная память на указатели: Каждый узел хранит не только данные, но и один или два указателя, что увеличивает потребление памяти (обычно на 8-16 байт на узел в современных системах).
Плохая локальность кэша: Поскольку узлы разбросаны в памяти, процессорный кэш работает менее эффективно, чем при последовательном доступе к массиву. Это может замедлить обход больших списков.
Сценарии применения связных списков в реальных проектах
Реализация стеков и очередей: Связные списки идеально подходят для создания стеков (LIFO) и очередей (FIFO), где операции добавления и удаления выполняются на концах структуры. Например, стек браузера (кнопка "Назад") может быть реализован как связный список.
Управление памятью в операционных системах: Системы управления памятью (например, free list в malloc) часто используют связные списки для отслеживания свободных блоков памяти.
Представление разреженных матриц: Если матрица содержит много нулей, можно хранить только ненулевые элементы в виде связного списка, экономя память.
Реализация хеш-таблиц с цепочками (chaining): При коллизиях в хеш-таблице элементы, попавшие в одну корзину, хранятся в связном списке.
Музыкальные плееры и редакторы: Плейлисты часто реализуются как двусвязные списки, чтобы легко перемещаться между треками вперед и назад.
Графы и деревья: Связные списки используются для представления списков смежности в графах (каждая вершина хранит список соседей) и для реализации деревьев (например, children list в n-арных деревьях).
Визуализация связных списков: как платформа помогает понять структуру
Изучение связных списков по тексту или коду может быть сложным, особенно когда речь идет о работе с указателями. Платформа визуализации структур данных и алгоритмов решает эту проблему, позволяя вам "увидеть" работу связного списка в реальном времени.
Как работает визуализация на платформе
Когда вы заходите на страницу визуализации связного списка, вы видите:
- Графическое представление узлов в виде прямоугольников, соединенных стрелками (указателями).
- Анимацию вставки: новый узел "появляется" и стрелки перерисовываются, показывая, как меняются ссылки.
- Анимацию удаления: узел "исчезает", а стрелки соединяют соседние узлы.
- Подсветку текущего узла ри обходе списка.
- Интерактивные элементы управления: кнопки "Вставить в начало", "Вставить в конец", "Удалить по значению", "Поиск элемента".
Преимущества использования платформы визуализации для изучения
Наглядное понимание указателей: Многие студенты путаются в том, как работают ссылки на узлы. Визуализация делает этот процесс прозрачным: вы видите, как указатель меняется с одного узла на другой.
Мгновенная обратная связь: Вы можете выполнить операцию (например, вставку в середину) и сразу увидеть результат. Это позволяет экспериментировать и проверять гипотезы без написания кода.
Пошаговый режим: Платформа позволяет выполнять алгоритмы шаг за шагом, наблюдая за изменением состояния списка на каждом этапе. Это особенно полезно для сложных операций, таких как реверс списка или обнаружение цикла.
Сравнение различных реализаций: Вы можете визуализировать односвязный и двусвязный список рядом, чтобы понять разницу в структуре и производительности операций.
Поддержка множества языков программирования: Платформа показывает не только визуализацию, но и соответствующий код на популярных языках (Python, Java, C++, JavaScript), что помогает связать визуальное представление с реальной реализацией.
Как использовать платформу для максимальной эффективности обучения
Шаг 1: Изучите теорию. Прочитайте эту статью или другие материалы о связных списках. Поймите базовые понятия: узел, указатель, голова, хвост.
Шаг 2: Откройте визуализацию. Перейдите на страницу визуализации связного списка на платформе. Начните с создания простого списка из 3-5 элементов.
Шаг 3: Выполните базовые операции. Используйте кнопки интерфейса, чтобы вставить элемент в начало, в конец и в середину. Наблюдайте за изменениями стрелок. Обратите внимание, как меняется указатель головы при вставке в начало.
Шаг 4: Поэкспериментируйте с удалением. Удалите элемент из начала, середины и конца. Посмотрите, как платформа обрабатывает удаление последнего элемента (список становится пустым).
Шаг 5: Используйте пошаговый режим. Запустите алгоритм (например, поиск элемента или реверс спска) в пошаговом режиме. Сделайте паузу на каждом шаге и сравните состояние писка с кодом, который отображается рядом.
Шаг 6: Решите задачи. Многие платформы визуализации включают встроенные задачи (например, "Обнаружить цикл в списке" или "Найти середину списка"). Попробуйте решить их сначала визуально, а затем напишите код.
Шаг 7: Сравните с массивом. Используйте визуализацию массива на той же платформе, чтобы сравнить операции вставки и удаления. Вы увидите, почему вставка в массив требует сдвига элементов, а в списке — только изменения указателей.
Сложные темы, которые можно изучить с помощью визуализации
Реверс связного списка: Одна из самых популярных задач на собеседованиях. Визуализация поможет понять, как три указателя (prev, current, next) перемещаются по списку, разворачивая ссылки.
Обнаружение цикла (алгоритм Флойда): Используя два указателя (медленный и быстрый), можно определить, есть ли в списке цикл. Визуализация делает этот алгоритм интуитивно понятным.
Сортировка связного списка: Сортировка слиянием (merge sort) для связного списка. Визуализация помогает увидеть, как список делится на две половины, сортируется рекурсивно, а затем сливается.
Работа с двусвязным списком: Визуализация показывает, как два указателя (next и prev) облегчают такие операции, как удаление узла по ссылке (не нужно искать предыдущий узел).
Часто задаваемые вопросы о связных списках
Вопрос: В чем разница между односвязным и двусвязным списком?
Ответ: В односвязном списке каждый узел знает только о следующем узле. В двусвязном списке каждый узел знает и о следующем, и о предыдущем. Двусвязный список занимает больше памяти (дополнительный указатель), но позволяет обходить список в обратном направлении и удалять узел за O(1), имея только ссылку на него.
Вопрос: Когда стоит использовать связный список вместо массива?
Ответ: Когда вам нужно часто вставлять или удалять элементы в начале или середине коллекции, и при этом размер коллекции динамически меняется. Если вам нужен быстрый доступ по индексу, лучше выбрать массив.
Вопрос: Что такое "голова" и "хвост" списка?
Ответ: Голова (head) — это первый узел списка. Хвост (tail) — это последний узел, который указывает на null (в некольцевых списках). Хранение отделього указателя на хвост позволяет выполнять вставку в конец за O(1).
Вопрос: Как реализовать стек на основе связного списка?
Ответ: Стек (LIFO) можно реализовать, вставляя и удаляя элементы только в начале списка. Операции push и pop будут выполняться за O(1).
Заключение: визуализация как ключ к пониманию структур данных
Связные списки — это не просто академическая концепция, а мощный инструмент, который используется в реальных проектах ежедневно. Понимание их работы на уровне указателей и памяти — важный шаг в становлении профессионального разработчика. Платформа визуализации структур данных и алгоритмов делает этот процесс наглядным, интерактивным и эффективным. Вместо того чтобы просто читать о том, как работает вставка в список, вы можете увидеть ее своими глазами, поэкспериментировать с различными сценариями и закрепить знания на практике.
Начните с простого: создайте свой первый связный список на платформе, выполните несколько операций, а затем переходите к более сложным алгоритмам. Помните, что лучший способ выучить структуры данных — это практика, а визуализация — лучший помощник в этой практике. Используйте платформу регулярно, и вы заметите, как сложные концепции становятся интуитивно понятными. Удачи в изучении структур данных и алгоритмов!
按位序删除结点
该函数用于按位序删除节点的功能。具体来说,当参数 i 为 1 时,删除链表的 头节点;当 i 等于链表长度时,删除链表的 尾节点。
重点注意下链表为空和不为空时的处理逻辑

删除时链表空和不空时的区别
按位序删除结点 | 可视化完整可视化
2.3 Подробное объяснение двусвязного списка - Учебник по линейным спискам Визуализируйте свой код с помощью анимации
Линейные списки и связные списки: Полное руководство для изучающих структуры данных и алгоритмы
В мире программирования структуры данных являются фундаментом, на котором строятся эффективные алгоритмы. Одной из самых базовых и важных структур данных является линейный список. В этой статье мы подробно разберем, что такое линейные списки, особое внимание уделим связным спискам (linked lists), их принципам работы, преимуществам и недостаткам, а также реальным сценариям применения. Если вы изучаете структуры данных и алгоритмы, это руководство поможет вам понять ключевые концепции, которые пригодятся на собеседованиях и в практической разработке.
Что такое линейный список? Определение и основные свойства
Линейный список — это упорядоченная коллекция элементов, где каждый элемент (узел) имеет уникальную позицию. Представьте себе список покупок: у вас есть первый пункт, второй, третий и так далее. В программировании линейные списки могут быть реализованы по-разному: с помощью массива (статический список) или с помощью связных узлов (динамический список). Основное свойство линейного списка — это линейный порядок: каждый элемент, кроме первого и последнего, имеет ровно одного предшественника и одного последователя.
Связный список (Linked List): подробный разбор
Связный список — это динамическая структура данных, состоящая из узлов. Каждый узел содержит данные (значение) и указатель (ссылку) на следующий узел в последовательности. В отличие от массива, элементы связного списка не хранятся в непрерывной области памяти. Это ключевое отличие, которое дает связным спискам уникальные свойства.
Основные виды связных списков
Односвязный список (Singly Linked List): Каждый узел содержит данные и указатель только на следующий узел. Обход возможен только в одном направлении — от головы (head) к хвосту (tail). Последний узел указывает на null (None в Python).
Двусвязный список (Doubly Linked List): Каждый узел содержит данные, указатель на следующий узел и указатель на предыдущий узел. Это позволяет обходить список в обоих направлениях, что упрощает некоторые операции (например, удаление узла по ссылке).
Кольцевой (циклический) связный список (Circular Linked List): В такой структуре последний узел указывает не на null, а на первый узел, образуя замкнутый цикл. Это удобно для задач, где требуется циклический обход (например, игровые циклы или планировщики задач).
Принцип работы связного списка: как это выглядит в памяти
Представьте, что у вас есть цепочка из бумажных полосок, скрепленных скрепками. Каждая полоска — это узел с данными, а скрепка — это указатель на следующий узел. Если вы хотите добавить новую полоску в середину цепочки, вам не нужно переписывать всю цепочку — достаточно разомкнуть скрепки в нужном месте и вставить новый элемент. Именно так работает вставка в связный список: вы просто меняете указатели, не перемещая остальные элементы.
При удалении элемента из связного списка вы перенаправляете указатель предыдущего узла на узел, следующий за удаляемым. Сам удаляемый узел затем может быть освобожден сборщиком мусора (в языках с автоматическим управлением памятью) или удален вручную (в C/C++).
Преимущества связных списков перед массивами
Динамический размер: Связный список может расти и уменьшаться во время выполнения программы без необходимости перераспределения памяти. Массив же имеет фиксированный размер (в статических языках) или требует дорогостоящей операции изменения размера (например, при переполнении ArrayList в Java).
Эффективная вставка и удаление: Вставка нового элемента в начало или середину списка, а также удалени элемента, выполняется за O(1) (константное время), если у вас есть ссылка на нужную позицию. В массиве вставка в начало требует сдвига всех остальных элементов — это O(n).
Отсутствие фрагментации памяти (в некоторых случаях): Хотя узлы списка разбросаны по памяти, они не требуют непрерывного блока, что может быть полезно при работе с ограниченной памятью или при частых операциях выделения/освобождения.
Недостатки связных списков
Медленный доступ по индексу: Чтобы получить элемент с индексом i, нужно пройти по списку от головы до i-го узла — это O(n). В массиве доступ по индексу — O(1).
Дополнительная память на указатели: Каждый узел хранит не только данные, но и один или два указателя, что увеличивает потребление памяти (обычно на 8-16 байт на узел в современных системах).
Плохая локальность кэша: Поскольку узлы разбросаны в памяти, процессорный кэш работает менее эффективно, чем при последовательном доступе к массиву. Это может замедлить обход больших списков.
Сценарии применения связных списков в реальных проектах
Реализация стеков и очередей: Связные списки идеально подходят для создания стеков (LIFO) и очередей (FIFO), где операции добавления и удаления выполняются на концах структуры. Например, стек браузера (кнопка "Назад") может быть реализован как связный список.
Управление памятью в операционных системах: Системы управления памятью (например, free list в malloc) часто используют связные списки для отслеживания свободных блоков памяти.
Представление разреженных матриц: Если матрица содержит много нулей, можно хранить только ненулевые элементы в виде связного списка, экономя память.
Реализация хеш-таблиц с цепочками (chaining): При коллизиях в хеш-таблице элементы, попавшие в одну корзину, хранятся в связном списке.
Музыкальные плееры и редакторы: Плейлисты часто реализуются как двусвязные списки, чтобы легко перемещаться между треками вперед и назад.
Графы и деревья: Связные списки используются для представления списков смежности в графах (каждая вершина хранит список соседей) и для реализации деревьев (например, children list в n-арных деревьях).
Визуализация связных списков: как платформа помогает понять структуру
Изучение связных списков по тексту или коду может быть сложным, особенно когда речь идет о работе с указателями. Платформа визуализации структур данных и алгоритмов решает эту проблему, позволяя вам "увидеть" работу связного списка в реальном времени.
Как работает визуализация на платформе
Когда вы заходите на страницу визуализации связного списка, вы видите:
- Графическое представление узлов в виде прямоугольников, соединенных стрелками (указателями).
- Анимацию вставки: новый узел "появляется" и стрелки перерисовываются, показывая, как меняются ссылки.
- Анимацию удаления: узел "исчезает", а стрелки соединяют соседние узлы.
- Подсветку текущего узла ри обходе списка.
- Интерактивные элементы управления: кнопки "Вставить в начало", "Вставить в конец", "Удалить по значению", "Поиск элемента".
Преимущества использования платформы визуализации для изучения
Наглядное понимание указателей: Многие студенты путаются в том, как работают ссылки на узлы. Визуализация делает этот процесс прозрачным: вы видите, как указатель меняется с одного узла на другой.
Мгновенная обратная связь: Вы можете выполнить операцию (например, вставку в середину) и сразу увидеть результат. Это позволяет экспериментировать и проверять гипотезы без написания кода.
Пошаговый режим: Платформа позволяет выполнять алгоритмы шаг за шагом, наблюдая за изменением состояния списка на каждом этапе. Это особенно полезно для сложных операций, таких как реверс списка или обнаружение цикла.
Сравнение различных реализаций: Вы можете визуализировать односвязный и двусвязный список рядом, чтобы понять разницу в структуре и производительности операций.
Поддержка множества языков программирования: Платформа показывает не только визуализацию, но и соответствующий код на популярных языках (Python, Java, C++, JavaScript), что помогает связать визуальное представление с реальной реализацией.
Как использовать платформу для максимальной эффективности обучения
Шаг 1: Изучите теорию. Прочитайте эту статью или другие материалы о связных списках. Поймите базовые понятия: узел, указатель, голова, хвост.
Шаг 2: Откройте визуализацию. Перейдите на страницу визуализации связного списка на платформе. Начните с создания простого списка из 3-5 элементов.
Шаг 3: Выполните базовые операции. Используйте кнопки интерфейса, чтобы вставить элемент в начало, в конец и в середину. Наблюдайте за изменениями стрелок. Обратите внимание, как меняется указатель головы при вставке в начало.
Шаг 4: Поэкспериментируйте с удалением. Удалите элемент из начала, середины и конца. Посмотрите, как платформа обрабатывает удаление последнего элемента (список становится пустым).
Шаг 5: Используйте пошаговый режим. Запустите алгоритм (например, поиск элемента или реверс спска) в пошаговом режиме. Сделайте паузу на каждом шаге и сравните состояние писка с кодом, который отображается рядом.
Шаг 6: Решите задачи. Многие платформы визуализации включают встроенные задачи (например, "Обнаружить цикл в списке" или "Найти середину списка"). Попробуйте решить их сначала визуально, а затем напишите код.
Шаг 7: Сравните с массивом. Используйте визуализацию массива на той же платформе, чтобы сравнить операции вставки и удаления. Вы увидите, почему вставка в массив требует сдвига элементов, а в списке — только изменения указателей.
Сложные темы, которые можно изучить с помощью визуализации
Реверс связного списка: Одна из самых популярных задач на собеседованиях. Визуализация поможет понять, как три указателя (prev, current, next) перемещаются по списку, разворачивая ссылки.
Обнаружение цикла (алгоритм Флойда): Используя два указателя (медленный и быстрый), можно определить, есть ли в списке цикл. Визуализация делает этот алгоритм интуитивно понятным.
Сортировка связного списка: Сортировка слиянием (merge sort) для связного списка. Визуализация помогает увидеть, как список делится на две половины, сортируется рекурсивно, а затем сливается.
Работа с двусвязным списком: Визуализация показывает, как два указателя (next и prev) облегчают такие операции, как удаление узла по ссылке (не нужно искать предыдущий узел).
Часто задаваемые вопросы о связных списках
Вопрос: В чем разница между односвязным и двусвязным списком?
Ответ: В односвязном списке каждый узел знает только о следующем узле. В двусвязном списке каждый узел знает и о следующем, и о предыдущем. Двусвязный список занимает больше памяти (дополнительный указатель), но позволяет обходить список в обратном направлении и удалять узел за O(1), имея только ссылку на него.
Вопрос: Когда стоит использовать связный список вместо массива?
Ответ: Когда вам нужно часто вставлять или удалять элементы в начале или середине коллекции, и при этом размер коллекции динамически меняется. Если вам нужен быстрый доступ по индексу, лучше выбрать массив.
Вопрос: Что такое "голова" и "хвост" списка?
Ответ: Голова (head) — это первый узел списка. Хвост (tail) — это последний узел, который указывает на null (в некольцевых списках). Хранение отделього указателя на хвост позволяет выполнять вставку в конец за O(1).
Вопрос: Как реализовать стек на основе связного списка?
Ответ: Стек (LIFO) можно реализовать, вставляя и удаляя элементы только в начале списка. Операции push и pop будут выполняться за O(1).
Заключение: визуализация как ключ к пониманию структур данных
Связные списки — это не просто академическая концепция, а мощный инструмент, который используется в реальных проектах ежедневно. Понимание их работы на уровне указателей и памяти — важный шаг в становлении профессионального разработчика. Платформа визуализации структур данных и алгоритмов делает этот процесс наглядным, интерактивным и эффективным. Вместо того чтобы просто читать о том, как работает вставка в список, вы можете увидеть ее своими глазами, поэкспериментировать с различными сценариями и закрепить знания на практике.
Начните с простого: создайте свой первый связный список на платформе, выполните несколько операций, а затем переходите к более сложным алгоритмам. Помните, что лучший способ выучить структуры данных — это практика, а визуализация — лучший помощник в этой практике. Используйте платформу регулярно, и вы заметите, как сложные концепции становятся интуитивно понятными. Удачи в изучении структур данных и алгоритмов!