正在载入交互式动画窗口请稍等
栈-链表-带头结点 可视化交互式动画版
要使用单链表概念 实现 堆栈,所有单 链表 操作都应基于堆栈操作 LIFO(后进先出)执行,并且借助这些知识,我们将使用单链表实现堆栈列表。
因此,我们在堆栈的实现中需要遵循一个简单的规则,即 后进先出 ,并且所有操作都可以在顶部变量的帮助下执行。 让我们在下面的文章中 学习如何执行 Pop、Push、Peek 和 Display操作:
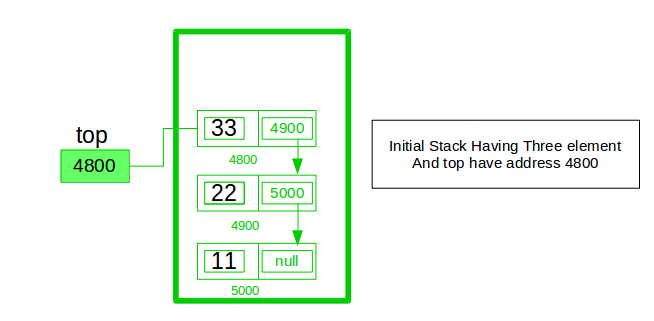
在栈实现中,栈包含一个栈顶指针。 这是堆栈的“头部”,其中推送和弹出项目发生在列表的头部。 第一个节点在链接字段中具有空值,第二个节点链接在链接字段中具有第一个节点地址,依此类推,最后一个节点地址在“顶部”指针中。
与数组相比,使用链表的主要优点是可以实现可以根据需要缩小或增长的堆栈。 使用数组会限制数组的最大容量,这可能导致堆栈溢出。 这里每个新节点将被动态分配。 所以溢出是不可能的。
堆栈操作:
- push() : 将一个新元素插入堆栈,即在链表的开头插入一个新元素。
- pop() : 返回堆栈的顶部元素,即简单地从链表中删除第一个元素。
- peek() : 返回顶部元素。
- display(): 打印Stack中的所有元素。
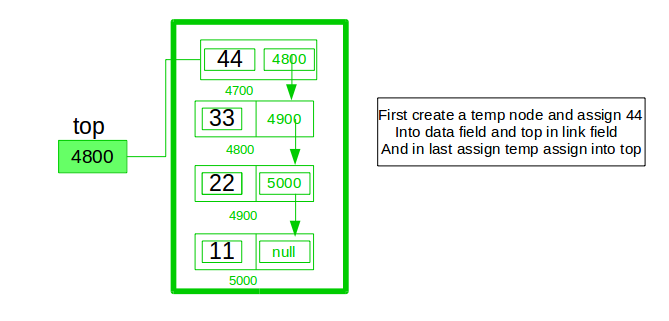
推送操作:
- 初始化一个节点
- 通过数据更新该节点的值,即 节点->数据=数据
- 现在将此节点链接到链表的顶部
- 并将top指针更新为当前节点
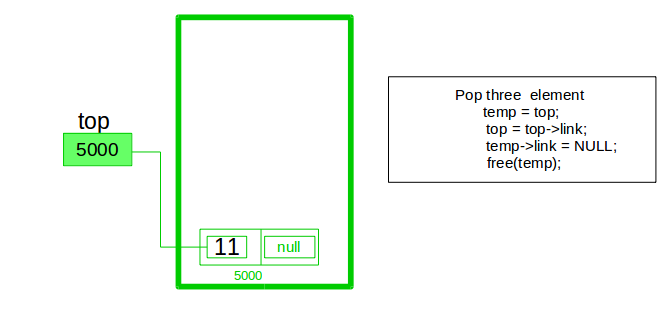
流行操作:
- 首先检查链表中是否存在节点,如果没有则返回
- 否则使指针(假设为 temp) 指向顶部节点,并将顶部节点向前移动 1 步
- 现在释放这个临时节点
窥视操作:
- 检查是否存在任何节点,如果不存在则返回。
- 否则返回链表顶节点的值
显示操作:
- 获取一个 临时 节点并使用顶部指针对其进行初始化
- 现在开始遍历temp直到遇到NULL
- 同时打印temp节点的值
下面是上述操作的实现
- C++
- Java
- Python3
- C#
- JavaScript
C++
// C++ program to Implement a stack// using singly linked list
#include <bits/stdc++.h>using namespace std;// creating a linked list;
class Node {public: int
data; Node* link;
// Constructor Node(int n)
{ this->data = n; this->link = NULL; }};class Stack { Node* top;public: Stack() { top = NULL; } void push(int data) { // Create new node temp and allocate memory in heap Node* temp = new Node(data); // Check if stack (heap) is full. // Then inserting an element would // lead to stack overflow if (!temp) { cout << "\nStack Overflow"; exit(1); } // Initialize data into temp data field temp->data = data; // Put top pointer reference into temp link temp->link = top; // Make temp as top of Stack top = temp; } // Utility function to check if // the stack is empty or not bool isEmpty() { // If top is NULL it means that // there are no elements are in stack return top == NULL; } // Utility function to return top element in a stack int
peek() { // If stack is not empty , return the top element if (!isEmpty()) return top->data; else exit(1); } // Function to remove // a key from given queue q void pop() { Node* temp; // Check for stack underflow if (top == NULL) { cout << "\nStack Underflow" << endl; exit(1); } else { // Assign top to temp temp = top; // Assign second node to top top = top->link; // This will automatically destroy // the link between first node and second node // Release memory of top node // i.e delete the node free(temp); } } // Function to print all the // elements of the stack void display() { Node* temp; // Check for stack underflow if (top == NULL) { cout << "\nStack Underflow"; exit(1); } else { temp = top; while (temp != NULL) { // Print node data cout << temp->data; // Assign temp link to temp temp = temp->link; if (temp != NULL) cout << " -> "; } } }};// Driven Programint main(){ // Creating a stack Stack s;
// Push the elements of stack s.push(11); s.push(22); s.push(33); s.push(44); // Display stack elements s.display(); // Print top element of stack cout << "\nTop element is " << s.peek() << endl; // Delete top elements of stack s.pop();
s.pop();
// Display stack elements s.display(); // Print top element of stack cout << "\nTop element is " << s.peek() << endl; return 0;} |
Java
Python3
C#
Javascript
44 -> 33 -> 22 -> 11 顶部元素为 44 22 -> 11 顶部元素为 22
时间复杂度:
O(1),对于所有的push()、pop()和peek(),因为我们没有对列表执行任何类型的遍历。
我们仅通过当前指针执行所有操作。
辅助空间:
O(N),其中N是堆栈的大小
在这个实现中,我们定义了一个Node类来表示链表中的一个节点,以及一个Stack类,使用这个节点类来实现栈。 Stack类的head属性指向栈顶(即链表中的第一个节点)。
要将项目压入堆栈,我们使用给定项目创建一个新节点,并将其下一个指针设置为堆栈的当前头。 然后,我们将堆栈的头部设置为新节点,有效地使其成为堆栈的新顶部。
要从堆栈中弹出一个项目,我们只需将堆栈的头设置为链表中的下一个节点(即当前头的下一个指针指向的节点),即可从链表中删除第一个节点。 我们返回原始头节点中存储的数据,该节点是从堆栈顶部删除的项。
使用单链表实现堆栈的好处包括:
动态内存分配 :可以通过在链表中添加或删除节点来动态增加或减少堆栈的大小,而不需要预先为堆栈分配固定数量的内存。
高效的内存使用: 由于单链表中的节点只有 next 指针而没有 prev 指针,因此它们比双向链表中的节点使用更少的内存。
易于实现 :使用单链表实现堆栈非常简单,只需几行代码即可完成。
通用性 :单链表可用于实现其他数据结构,例如队列、链表和树。
总而言之,使用单链表实现堆栈是在 Python 中创建动态堆栈数据结构的一种简单而有效的方法。
堆栈的实时示例:
堆栈用于需要后进先出 (LIFO) 数据结构的各种实际场景。 下面是一些堆栈实时应用的例子:
函数调用栈 :当程序中调用函数时,返回地址和所有函数参数都被压入函数调用栈。 堆栈允许函数按照与调用顺序相反的顺序执行并返回到调用者函数。
撤消/重做操作: 在许多应用程序中,例如文本编辑器、图像编辑器或 Web 浏览器,撤消和重做功能是使用堆栈实现的。 每次执行一个操作时,都会将其压入堆栈。 当用户想要撤消上一个操作时,堆栈顶部的元素将被弹出,并且操作将被反转。
浏览器历史记录: Web 浏览器使用堆栈来跟踪用户访问的页面。 每次访问新页面时,其 URL 都会被压入堆栈。 当用户单击“后退”按钮时,最后访问的 URL 将从堆栈中弹出,并将用户定向到上一页。
表达式求值 :编译器和解释器中使用堆栈来求值表达式。 当解析表达式时,它会被转换为后缀表示法并压入堆栈。 然后使用堆栈计算后缀表达式。
递归中的调用堆栈: 当调用递归函数时,其调用被压入堆栈。 该函数执行并调用自身,并且每个后续调用都被压入堆栈。 当递归结束时,堆栈被弹出,程序返回到上一个函数调用。
总之,堆栈广泛应用于许多需要 LIFO 功能的应用程序中,例如函数调用、撤消/重做操作、浏览器历史记录、表达式求值和递归函数调用。