正在载入交互式动画窗口请稍等
KMP 算法 可视化交互式动画版
给定文本 txt[0 . 。 。 N-1] 和模式 pat[0 。 。 。 M-1] ,编写一个函数 search(char pat[], char txt[]) 打印 txt[] 中所有出现的 pat[]。 您可以假设 N > M 。
例子:
输入: txt[] =“这是测试文本”,pat[] =“测试”
输出: 在索引 10 处找到的模式输入: txt[] = “AABAACAADAABAABA”
pat[] = “AABA”
输出: 在索引 0 处找到模式、在索引 9 处找到模式、在索引 12 处找到模式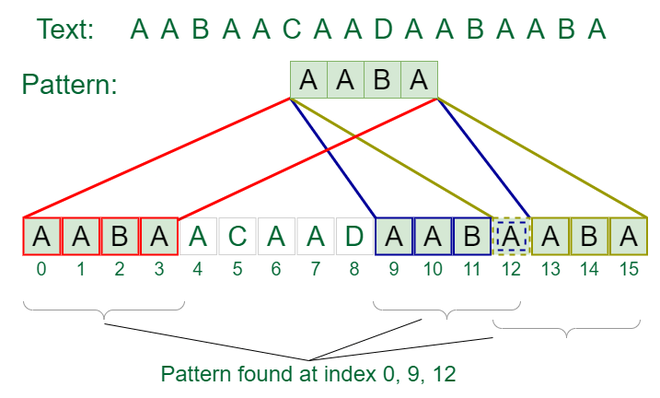
文本中模式的到达
模式搜索是计算机科学中的一个重要问题。 当我们在记事本/Word 文件、浏览器或数据库中搜索字符串时,会使用模式搜索算法来显示搜索结果。
我们在上一篇文章 中讨论了朴素模式搜索算法 。 Naive 算法最坏情况的复杂度为 O(m(n-m+1))。 KMP算法的时间复杂度在最坏的情况下是O(n+m)。
KMP(Knuth Morris Pratt)模式搜索:
当我们看到许多匹配字符后面跟着一个不匹配字符时,朴素模式搜索算法就不能很好地 工作 。
例子:
1) txt[] = “AAAAAAAAAAAAAAAAB”, pat[] = “AAAAB”
2) txt[] = “ABABABCABABABCABABABC”, pat[] = “ABABAC” (不是最坏的情况,但对 Naive 来说是个坏情况)
KMP匹配算法利用模式的退化特性(具有相同子模式在模式中出现多次的模式)并将最坏情况的复杂度提高到 O(n+m) 。
KMP 算法背后的基本思想是:每当我们检测到不匹配时(在一些匹配之后),我们就已经知道下一个窗口文本中的一些字符。 我们利用此信息来避免匹配我们知道无论如何都会匹配的字符。
匹配概览
txt = “AAAAABAAABA”
pat = “AAAA”
我们将 txt 的第一个窗口与 pat进行比较txt = “ AAAA ABAAABA”
pat = “ AAAA ” [初始位置]
我们找到匹配项。 这与朴素字符串匹配 相同 。在下一步中,我们将 txt 的下一个窗口与 pat 进行比较。
txt = “ AAAAA BAAABA”
pat = “ AAAA ” [图案移动一位]这就是 KMP 相对 Naive 进行优化的地方。 在第二个窗口中,我们仅将模式的第四个 A
与当前文本窗口的第四个字符进行比较,以决定当前窗口是否匹配。 由于我们知道
前三个字符无论如何都会匹配,因此我们跳过了匹配前三个字符。需要预处理吗?
从上面的解释中产生了一个重要的问题,如何知道要跳过多少个字符。 为了了解这一点,
我们预处理模式并准备一个整数数组 lps[] 来告诉我们要跳过的字符数
预处理概述:
- KMP算法预处理pat[]并构造一个大小为 m (与模式大小相同)的辅助 lps[] ,用于在匹配时跳过字符。
- 名称 lps 表示最长的正确前缀,它也是一个后缀。 正确的前缀是不允许包含整个字符串的前缀。 例如,“ABC”的前缀是“”、“A”、“AB”和“ABC”。 正确的前缀是“”、“A”和“AB”。 字符串的后缀是“”、“C”、“BC”和“ABC”。
- 我们在子模式中搜索 lps。 更清楚地说,我们关注的是既是前缀又是后缀的模式子串。
- 对于每个子模式 pat[0..i](其中 i = 0 到 m-1),lps[i] 存储最大匹配正确前缀的长度,该前缀也是子模式 pat[0..i 的后缀]。
lps[i] = pat[0..i] 的最长真前缀,也是 pat[0..i] 的后缀。
注意: lps[i] 也可以定义为最长的前缀,这也是一个适当的后缀。 我们需要在一个地方正确使用它,以确保不考虑整个子字符串。
lps[] 构造示例:
对于模式“AAAA”,lps[] 为 [0, 1, 2, 3]
对于模式“ABCDE”,lps[] 为 [0, 0, 0, 0, 0]
对于模式“AABAACAABAA”,lps[] 为 [0, 1, 0, 1, 2, 0, 1, 2, 3, 4, 5]
对于模式“AAACAAAAAC”,lps[] 为 [0, 1, 2, 0, 1, 2, 3, 3, 3, 4]
对于模式“AAABAAA”,lps[] 为 [0, 1, 2, 0, 1, 2, 3]
预处理算法:
在预处理部分,
- 我们计算lps[] 中的值 。 为此,我们跟踪 前一个索引的最长前缀后缀值的长度(为此目的,我们使用 len变量)
- 我们将 lps[0] 和 len 初始化为 0。
- 如果 pat[len] 和 pat[i] 匹配,我们将 len 加 1,并将增加后的值赋给 lps[i]。
- 如果 pat[i] 和 pat[len] 不匹配并且 len 不为 0,我们将 len 更新为 lps[len-1]
- 有关详细信息,请参阅 下面代码中的 computeLPSArray()
预处理说明(或构建lps[]):
帕特[] =“AAACAAAA”
=> 长度= 0,我= 0:
- lps[0] 始终为 0,我们移动到 i = 1
=> 长度 = 0,我 = 1:
- 由于 pat[len] 和 pat[i] 匹配,因此执行 len++,
- 将其存储在 lps[i] 中并执行 i++。
- 设置 len = 1,lps[1] = 1,i = 2
=> 长度 = 1,我 = 2:
- 由于 pat[len] 和 pat[i] 匹配,因此执行 len++,
- 将其存储在 lps[i] 中并执行 i++。
- 设置 len = 2,lps[2] = 2,i = 3
=> 长度 = 2,我 = 3:
- 由于 pat[len] 和 pat[i] 不匹配,并且 len > 0,
- 设置 len = lps[len-1] = lps[1] = 1
=> 长度 = 1,我 = 3:
- 由于 pat[len] 和 pat[i] 不匹配且 len > 0,
- len = lps[len-1] = lps[0] = 0
=> 长度 = 0,我 = 3:
- 由于 pat[len] 和 pat[i] 不匹配且 len = 0,
- 设置 lps[3] = 0 且 i = 4
=> 长度 = 0,我 = 4:
- 由于 pat[len] 和 pat[i] 匹配,因此执行 len++,
- 将其存储在 lps[i] 中并执行 i++。
- 设置 len = 1,lps[4] = 1,i = 5
=> 长度 = 1,我 = 5:
- 由于 pat[len] 和 pat[i] 匹配,因此执行 len++,
- 将其存储在 lps[i] 中并执行 i++。
- 设置 len = 2,lps[5] = 2,i = 6
=> 长度 = 2,我 = 6:
- 由于 pat[len] 和 pat[i] 匹配,因此执行 len++,
- 将其存储在 lps[i] 中并执行 i++。
- 长度 = 3,lps[6] = 3,i = 7
=> 长度= 3,我= 7:
- 由于 pat[len] 和 pat[i] 不匹配且 len > 0,
- 设置 len = lps[len-1] = lps[2] = 2
=> 长度 = 2,我 = 7:
- 由于 pat[len] 和 pat[i] 匹配,因此执行 len++,
- 将其存储在 lps[i] 中并执行 i++。
- 长度 = 3,lps[7] = 3,i = 8
我们在这里停下来,因为我们已经构建了整个 lps[]。
KMP算法的实现:
与 Naive 算法 不同,我们将模式滑动 1 并在每次移位时比较所有字符,我们使用 lps[] 中的值来决定下一个要匹配的字符。 这个想法是不匹配我们知道无论如何都会匹配的字符。
如何使用 lps[] 来决定下一个位置(或知道要跳过的字符数)?
- 我们开始将 j = 0 的 pat[j] 与当前文本窗口的字符进行比较。
- 我们保持匹配字符 txt[i] 和 pat[j] 并保持递增 i 和 j,同时 pat[j] 和 txt[i] 保持 匹配 。
-
当我们看到
不匹配的情况时
- 我们知道字符 pat[0..j-1] 与 txt[ij…i-1] 匹配(请注意,j 以 0 开头,仅当匹配时才递增)。
- 我们还知道(从上面的定义)lps[j-1] 是 pat[0…j-1] 中既是正确前缀又是正确后缀的字符数。
- 从以上两点,我们可以得出结论,我们不需要将这些 lps[j-1] 字符与 txt[ij…i-1] 匹配,因为我们知道这些字符无论如何都会匹配。 让我们考虑一下上面的例子来理解这一点。
下图是上述算法的示意图:
考虑 txt[] =“ AAAAABAAABA ”,pat[] =“ AAAA ”
如果我们遵循上面的 LPS 构建过程,则 lps[] = {0, 1, 2, 3}
-> i = 0, j = 0: txt[i] 和 pat[j] 匹配,执行 i++, j++
-> i = 1, j = 1: txt[i] 和 pat[j] 匹配,做 i++, j++
-> i = 2, j = 2: txt[i] 和 pat[j] 匹配,做 i++, j++
-> i = 3, j = 3: txt[i] 和 pat[j] 匹配,做 i++, j++
-> i = 4, j = 4: 由于 j = M,打印找到的模式并重置 j, j = lps[j-1] = lps[3] = 3
与 Naive 算法不同,这里我们不匹配
该窗口的前三个字符。 lps[j-1] 的值(在上面的步骤中)为我们提供了下一个要匹配的字符的索引。-> i = 4, j = 3: txt[i] 和 pat[j] 匹配,执行 i++, j++
-> i = 5, j = 4: 由于 j == M,找到打印模式并重置 j, j = lps[j-1] = lps[3] = 3
再次与 Naive 算法不同,我们不匹配前三个字符这个窗口的。 lps[j-1] 的值(在上面的步骤中)为我们提供了下一个要匹配的字符的索引。-> i = 5, j = 3: txt[i] 和 pat[j] 不匹配且 j > 0,仅更改 j。 j = lps[j-1] = lps[2] = 2
-> i = 5, j = 2: txt[i] 和 pat[j] 不匹配且 j > 0,仅更改 j。 j = lps[j-1] = lps[1] = 1
-> i = 5, j = 1: txt[i] 和 pat[j] 不匹配且 j > 0,仅更改 j。 j = lps[j-1] = lps[0] = 0
-> i = 5, j = 0: txt[i] 和 pat[j] 不匹配并且 j 为 0,我们执行 i++。
-> i = 6, j = 0: txt[i] 和 pat[j] 匹配,i++ 和 j++ 匹配吗
-> i = 7, j = 1: txt[i] 和 pat[j] 匹配,i++ 和 j++ 匹配吗
我们继续这样,直到文本中有足够的字符可以与模式中的字符进行比较......
下面是上述方法的实现:
- C++
- Java
- Python3
- C#
- PHP
- JavaScript
C++
// C++ program for implementation of KMP pattern searching// algorithm#include <bits/stdc++.h>void computeLPSArray(char* pat, int M, int* lps);// Prints occurrences of txt[] in pat[]void KMPSearch(char* pat, char* txt){ int
M = strlen(pat); int
N = strlen(txt); // create lps[] that will hold the longest prefix suffix // values for pattern int
lps[M]; // Preprocess the pattern (calculate lps[] array) computeLPSArray(pat, M, lps); int
i = 0; // index for txt[] int
j = 0; // index for pat[] while ((N - i) >= (M - j)) { if (pat[j] == txt[i]) { j++; i++; } if (j == M) { printf("Found pattern at index %d ", i - j); j = lps[j - 1]; } // mismatch after j matches else if (i < N && pat[j] != txt[i]) { // Do not match lps[0..lps[j-1]] characters, // they will match anyway if (j != 0) j = lps[j - 1]; else i = i + 1; } }}// Fills lps[] for given pattern pat[0..M-1]void computeLPSArray(char* pat, int M, int* lps){ // length of the previous longest prefix suffix int
len = 0; lps[0] = 0; // lps[0] is always 0 // the loop calculates lps[i] for i = 1 to M-1 int
i = 1; while (i < M) { if (pat[i] == pat[len]) { len++; lps[i] = len; i++; } else // (pat[i] != pat[len]) { // This is tricky. Consider the example. // AAACAAAA and i = 7. The idea is similar // to search step. if (len != 0) { len = lps[len - 1]; // Also, note that we do not increment // i here } else // if (len == 0) { lps[i] = 0; i++; } } }}// Driver codeint main(){ char txt[] = "ABABDABACDABABCABAB"; char pat[] = "ABABCABAB"; KMPSearch(pat, txt); return 0;} |
Java
Python3
C#
PHP
Javascript
在索引 10 处找到模式
时间复杂度:
O(N+M),其中 N 是文本的长度,M 是要查找的模式的长度。
辅助空间:
O(M)
如果您发现任何不正确的内容,或者您想分享有关上述主题的更多信息,请发表评论。